Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity-Promoting Human Motion Interpolation via Conditional Variational Auto-Encoder
Paper and Code
Nov 12, 2021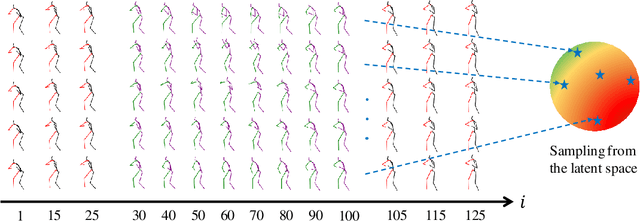
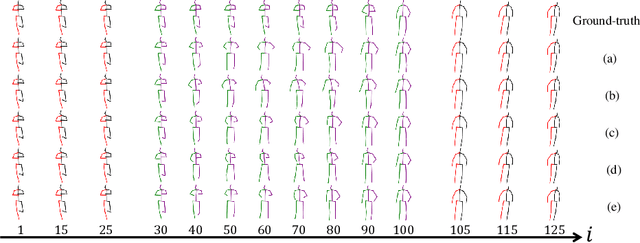
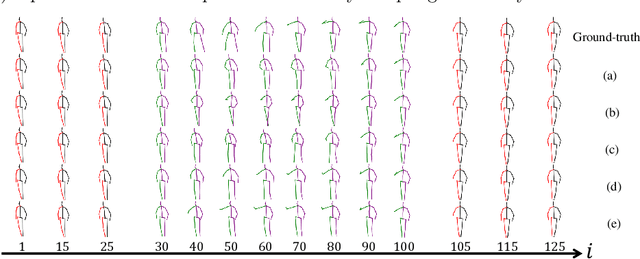
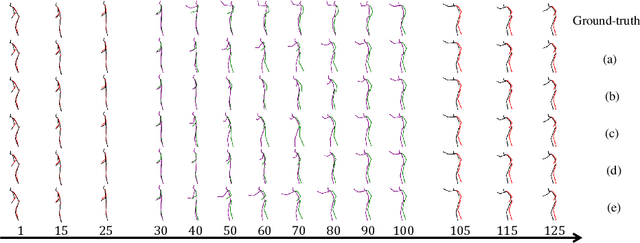
In this paper, we present a deep generative model based method to generate diverse human motion interpolation results. We resort to the Conditional Variational Auto-Encoder (CVAE) to learn human motion conditioned on a pair of given start and end motions, by leveraging the Recurrent Neural Network (RNN) structure for both the encoder and the decoder. Additionally, we introduce a regularization loss to further promote sample diversity. Once trained, our method is able to generate multiple plausible coherent motions by repetitively sampling from the learned latent space. Experiments on the publicly available dataset demonstrate the effectiveness of our method, in terms of sample plausibility and diversity.
View paper on