 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptBeam: Concept Driven Target Speech Extraction
Paper and Code
Jul 25, 2022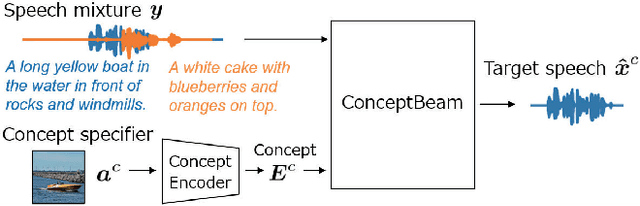
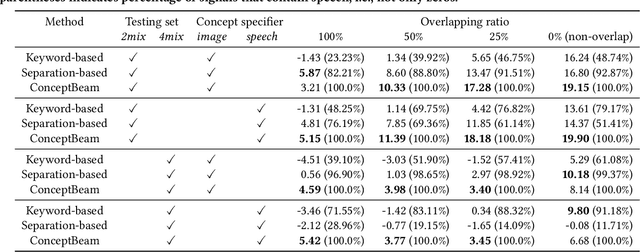
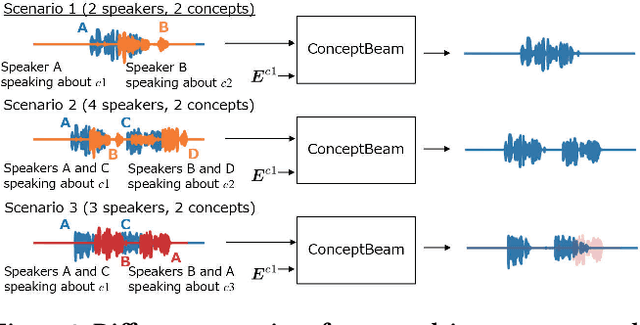

We propose a novel framework for target speech extraction based on semantic information, called ConceptBeam. Target speech extraction means extracting the speech of a target speaker in a mixture. Typical approaches have been exploiting properties of audio signals, such as harmonic structure and direction of arrival. In contrast, ConceptBeam tackles the problem with semantic clues. Specifically, we extract the speech of speakers speaking about a concept, i.e., a topic of interest, using a concept specifier such as an image or speech. Solving this novel problem would open the door to innovative applications such as listening systems that focus on a particular topic discussed in a conversation. Unlike keywords, concepts are abstract notions, making it challenging to directly represent a target concept. In our scheme, a concept is encoded as a semantic embedding by mapping the concept specifier to a shared embedding space. This modality-independent space can be built by means of deep metric learning using paired data consisting of images and their spoken captions. We use it to bridge modality-dependent information, i.e., the speech segments in the mixture, and the specified, modality-independent concept. As a proof of our scheme, we performed experiments using a set of images associated with spoken captions. That is, we generated speech mixtures from these spoken captions and used the images or speech signals as the concept specifiers. We then extracted the target speech using the acoustic characteristics of the identified segments. We compare ConceptBeam with two methods: one based on keywords obtained from recognition systems and another based on sound source separation. We show that ConceptBeam clearly outperforms the baseline methods and effectively extracts speech based on the semantic representation.