 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentVoiceGrad: Nonparallel Voice Conversion with Latent Diffusion/Flow-Matching Models
Sep 10, 2025Previously, we introduced VoiceGrad, a nonparallel voice conversion (VC) technique enabling mel-spectrogram conversion from source to target speakers using a score-based diffusion model. The concept involves training a score network to predict the gradient of the log density of mel-spectrograms from various speakers. VC is executed by iteratively adjusting an input mel-spectrogram until resembling the target speaker's. However, challenges persist: audio quality needs improvement, and conversion is slower compared to modern VC methods designed to operate at very high speeds. To address these, we introduce latent diffusion models into VoiceGrad, proposing an improved version with reverse diffusion in the autoencoder bottleneck. Additionally, we propose using a flow matching model as an alternative to the diffusion model to further speed up the conversion process without compromising the conversion quality. Experimental results show enhanced speech quality and accelerated conversion compared to the original.
Vocoder-Projected Feature Discriminator
Aug 25, 2025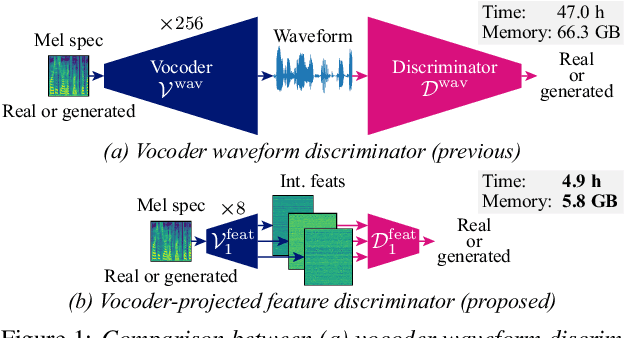

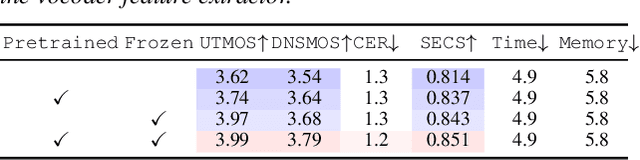

In text-to-speech (TTS) and voice conversion (VC), acoustic features, such as mel spectrograms, are typically used as synthesis or conversion targets owing to their compactness and ease of learning. However, because the ultimate goal is to generate high-quality waveforms, employing a vocoder to convert these features into waveforms and applying adversarial training in the time domain is reasonable. Nevertheless, upsampling the waveform introduces significant time and memory overheads. To address this issue, we propose a vocoder-projected feature discriminator (VPFD), which uses vocoder features for adversarial training. Experiments on diffusion-based VC distillation demonstrated that a pretrained and frozen vocoder feature extractor with a single upsampling step is necessary and sufficient to achieve a VC performance comparable to that of waveform discriminators while reducing the training time and memory consumption by 9.6 and 11.4 times, respectively.
FasterVoiceGrad: Faster One-step Diffusion-Based Voice Conversion with Adversarial Diffusion Conversion Distillation
Aug 25, 2025A diffusion-based voice conversion (VC) model (e.g., VoiceGrad) can achieve high speech quality and speaker similarity; however, its conversion process is slow owing to iterative sampling. FastVoiceGrad overcomes this limitation by distilling VoiceGrad into a one-step diffusion model. However, it still requires a computationally intensive content encoder to disentangle the speaker's identity and content, which slows conversion. Therefore, we propose FasterVoiceGrad, a novel one-step diffusion-based VC model obtained by simultaneously distilling a diffusion model and content encoder using adversarial diffusion conversion distillation (ADCD), where distillation is performed in the conversion process while leveraging adversarial and score distillation training. Experimental evaluations of one-shot VC demonstrated that FasterVoiceGrad achieves competitive VC performance compared to FastVoiceGrad, with 6.6-6.9 and 1.8 times faster speed on a GPU and CPU, respectively.
FastVoiceGrad: One-step Diffusion-Based Voice Conversion with Adversarial Conditional Diffusion Distillation
Sep 03, 2024



Diffusion-based voice conversion (VC) techniques such as VoiceGrad have attracted interest because of their high VC performance in terms of speech quality and speaker similarity. However, a notable limitation is the slow inference caused by the multi-step reverse diffusion. Therefore, we propose FastVoiceGrad, a novel one-step diffusion-based VC that reduces the number of iterations from dozens to one while inheriting the high VC performance of the multi-step diffusion-based VC. We obtain the model using adversarial conditional diffusion distillation (ACDD), leveraging the ability of generative adversarial networks and diffusion models while reconsidering the initial states in sampling. Evaluations of one-shot any-to-any VC demonstrate that FastVoiceGrad achieves VC performance superior to or comparable to that of previous multi-step diffusion-based VC while enhancing the inference speed. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/fastvoicegrad/.
Deficient Basis Estimation of Noise Spatial Covariance Matrix for Rank-Constrained Spatial Covariance Matrix Estimation Method in Blind Speech Extraction
May 06, 2021
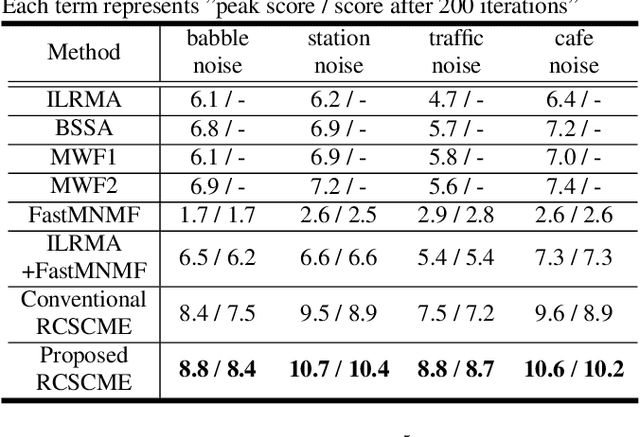
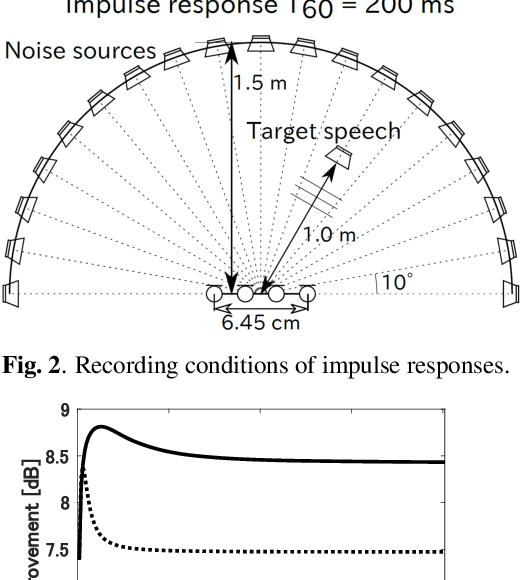
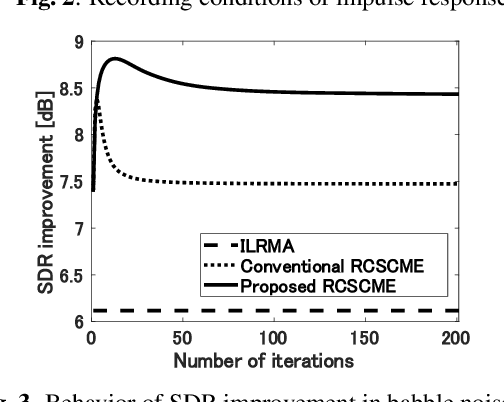
Rank-constrained spatial covariance matrix estimation (RCSCME) is a state-of-the-art blind speech extraction method applied to cases where one directional target speech and diffuse noise are mixed. In this paper, we proposed a new algorithmic extension of RCSCME. RCSCME complements a deficient one rank of the diffuse noise spatial covariance matrix, which cannot be estimated via preprocessing such as independent low-rank matrix analysis, and estimates the source model parameters simultaneously. In the conventional RCSCME, a direction of the deficient basis is fixed in advance and only the scale is estimated; however, the candidate of this deficient basis is not unique in general. In the proposed RCSCME model, the deficient basis itself can be accurately estimated as a vector variable by solving a vector optimization problem. Also, we derive new update rules based on the EM algorithm. We confirm that the proposed method outperforms conventional methods under several noise conditions.