 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Voice Conversion: Voice Conversion Preserving Spatial Information and Non-target Signals
Jun 25, 2024



This paper proposes a new task called spatial voice conversion, which aims to convert a target voice while preserving spatial information and non-target signals. Traditional voice conversion methods focus on single-channel waveforms, ignoring the stereo listening experience inherent in human hearing. Our baseline approach addresses this gap by integrating blind source separation (BSS), voice conversion (VC), and spatial mixing to handle multi-channel waveforms. Through experimental evaluations, we organize and identify the key challenges inherent in this task, such as maintaining audio quality and accurately preserving spatial information. Our results highlight the fundamental difficulties in balancing these aspects, providing a benchmark for future research in spatial voice conversion. The proposed method's code is publicly available to encourage further exploration in this domain.
Real-time Speech Extraction Using Spatially Regularized Independent Low-rank Matrix Analysis and Rank-constrained Spatial Covariance Matrix Estimation
Mar 19, 2024


Real-time speech extraction is an important challenge with various applications such as speech recognition in a human-like avatar/robot. In this paper, we propose the real-time extension of a speech extraction method based on independent low-rank matrix analysis (ILRMA) and rank-constrained spatial covariance matrix estimation (RCSCME). The RCSCME-based method is a multichannel blind speech extraction method that demonstrates superior speech extraction performance in diffuse noise environments. To improve the performance, we introduce spatial regularization into the ILRMA part of the RCSCME-based speech extraction and design two regularizers. Speech extraction experiments demonstrated that the proposed methods can function in real time and the designed regularizers improve the speech extraction performance.
NoisyILRMA: Diffuse-Noise-Aware Independent Low-Rank Matrix Analysis for Fast Blind Source Extraction
Jun 22, 2023


In this paper, we address the multichannel blind source extraction (BSE) of a single source in diffuse noise environments. To solve this problem even faster than by fast multichannel nonnegative matrix factorization (FastMNMF) and its variant, we propose a BSE method called NoisyILRMA, which is a modification of independent low-rank matrix analysis (ILRMA) to account for diffuse noise. NoisyILRMA can achieve considerably fast BSE by incorporating an algorithm developed for independent vector extraction. In addition, to improve the BSE performance of NoisyILRMA, we propose a mechanism to switch the source model with ILRMA-like nonnegative matrix factorization to a more expressive source model during optimization. In the experiment, we show that NoisyILRMA runs faster than a FastMNMF algorithm while maintaining the BSE performance. We also confirm that the switching mechanism improves the BSE performance of NoisyILRMA.
Algorithms of Sampling-Frequency-Independent Layers for Non-integer Strides
Jun 19, 2023



In this paper, we propose algorithms for handling non-integer strides in sampling-frequency-independent (SFI) convolutional and transposed convolutional layers. The SFI layers have been developed for handling various sampling frequencies (SFs) by a single neural network. They are replaceable with their non-SFI counterparts and can be introduced into various network architectures. However, they could not handle some specific configurations when combined with non-SFI layers. For example, an SFI extension of Conv-TasNet, a standard audio source separation model, cannot handle some pairs of trained and target SFs because the strides of the SFI layers become non-integers. This problem cannot be solved by simple rounding or signal resampling, resulting in the significant performance degradation. To overcome this problem, we propose algorithms for handling non-integer strides by using windowed sinc interpolation. The proposed algorithms realize the continuous-time representations of features using the interpolation and enable us to sample instants with the desired stride. Experimental results on music source separation showed that the proposed algorithms outperformed the rounding- and signal-resampling-based methods at SFs lower than the trained SF.
Hyperbolic Timbre Embedding for Musical Instrument Sound Synthesis Based on Variational Autoencoders
Sep 27, 2022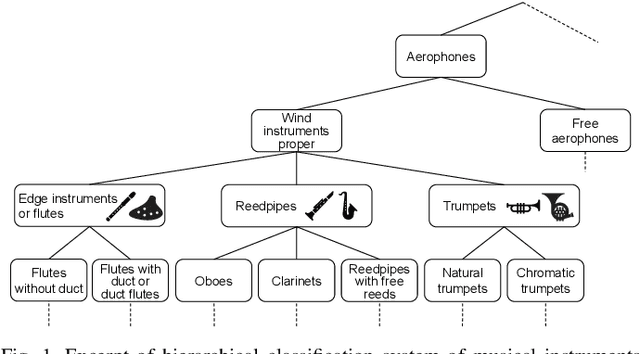
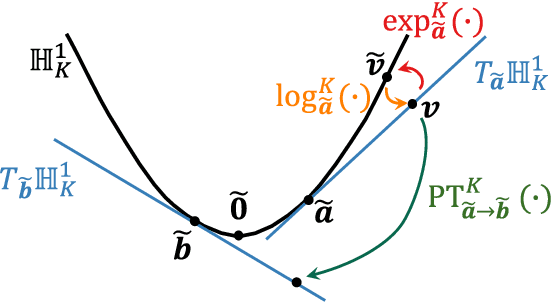
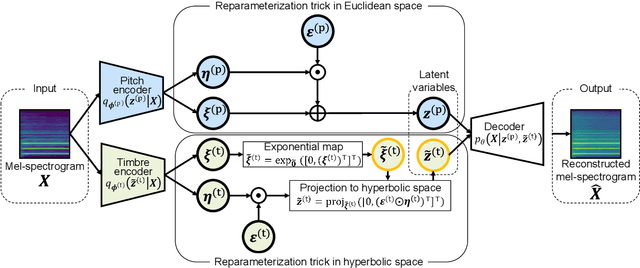
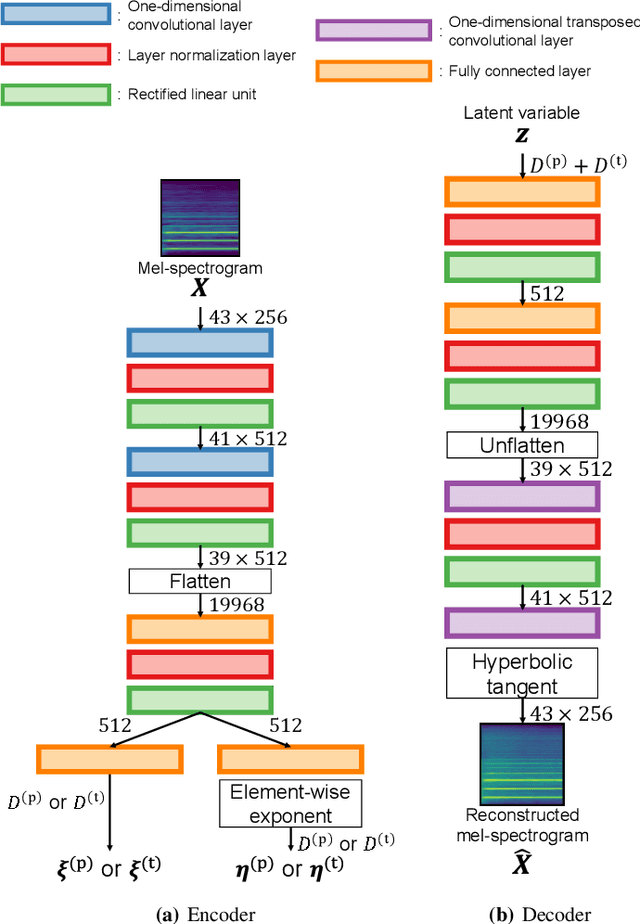
In this paper, we propose a musical instrument sound synthesis (MISS) method based on a variational autoencoder (VAE) that has a hierarchy-inducing latent space for timbre. VAE-based MISS methods embed an input signal into a low-dimensional latent representation that captures the characteristics of the input. Adequately manipulating this representation leads to sound morphing and timbre replacement. Although most VAE-based MISS methods seek a disentangled representation of pitch and timbre, how to capture an underlying structure in timbre remains an open problem. To address this problem, we focus on the fact that musical instruments can be hierarchically classified on the basis of their physical mechanisms. Motivated by this hierarchy, we propose a VAE-based MISS method by introducing a hyperbolic space for timbre. The hyperbolic space can represent treelike data more efficiently than the Euclidean space owing to its exponential growth property. Results of experiments show that the proposed method provides an efficient latent representation of timbre compared with the method using the Euclidean space.
Speech Enhancement by Noise Self-Supervised Rank-Constrained Spatial Covariance Matrix Estimation via Independent Deeply Learned Matrix Analysis
Sep 10, 2021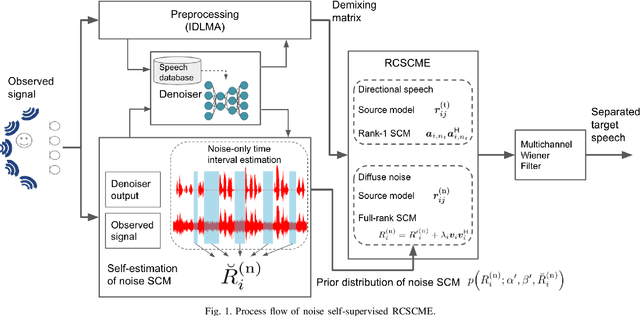
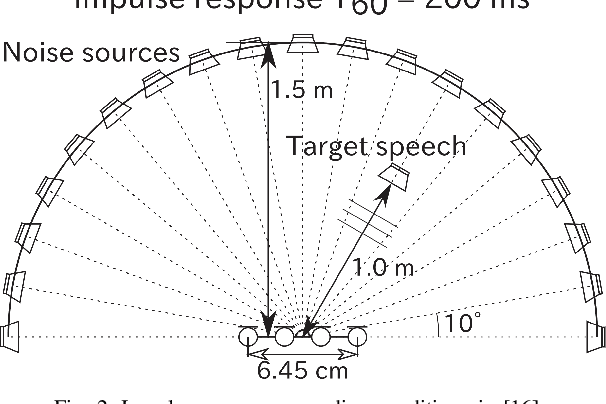
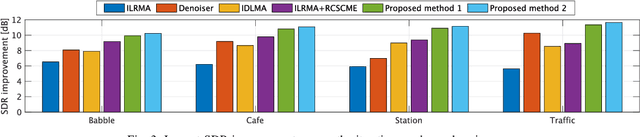
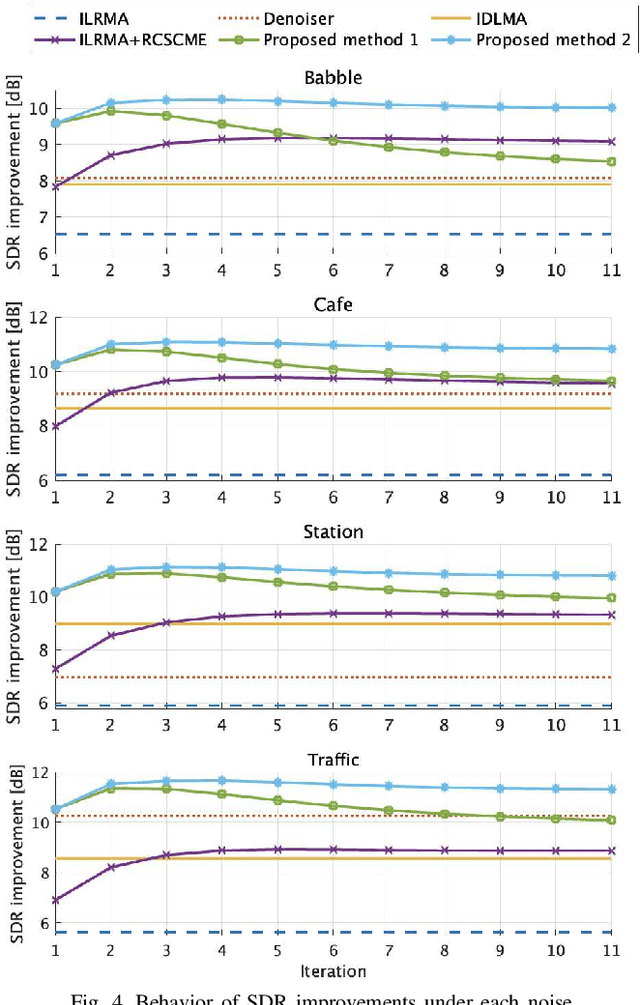
Rank-constrained spatial covariance matrix estimation (RCSCME) is a method for the situation that the directional target speech and the diffuse noise are mixed. In conventional RCSCME, independent low-rank matrix analysis (ILRMA) is used as the preprocessing method. We propose RCSCME using independent deeply learned matrix analysis (IDLMA), which is a supervised extension of ILRMA. In this method, IDLMA requires deep neural networks (DNNs) to separate the target speech and the noise. We use Denoiser, which is a single-channel speech enhancement DNN, in IDLMA to estimate not only the target speech but also the noise. We also propose noise self-supervised RCSCME, in which we estimate the noise-only time intervals using the output of Denoiser and design the prior distribution of the noise spatial covariance matrix for RCSCME. We confirm that the proposed methods outperform the conventional methods under several noise conditions.
Multichannel Audio Source Separation with Independent Deeply Learned Matrix Analysis Using Product of Source Models
Sep 02, 2021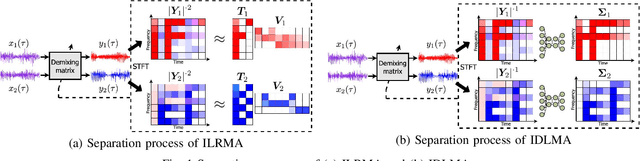
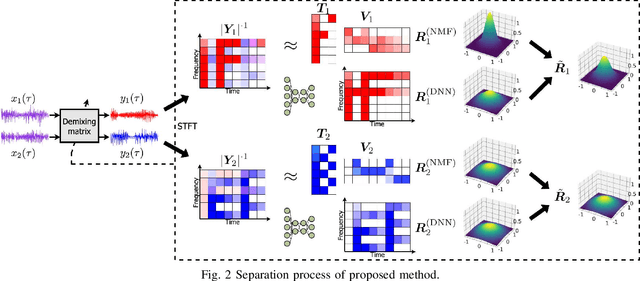
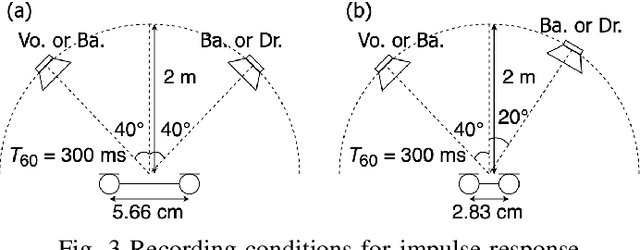
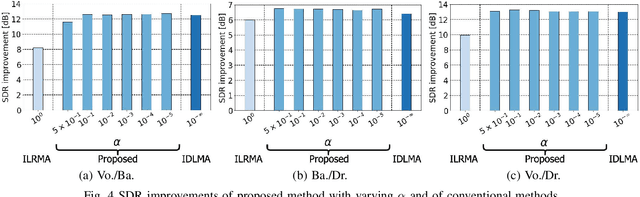
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art multichannel audio source separation methods using the source power estimation based on deep neural networks (DNNs). The DNN-based power estimation works well for sounds having timbres similar to the DNN training data. However, the sounds to which IDLMA is applied do not always have such timbres, and the timbral mismatch causes the performance degradation of IDLMA. To tackle this problem, we focus on a blind source separation counterpart of IDLMA, independent low-rank matrix analysis. It uses nonnegative matrix factorization (NMF) as the source model, which can capture source spectral components that only appear in the target mixture, using the low-rank structure of the source spectrogram as a clue. We thus extend the DNN-based source model to encompass the NMF-based source model on the basis of the product-of-expert concept, which we call the product of source models (PoSM). For the proposed PoSM-based IDLMA, we derive a computationally efficient parameter estimation algorithm based on an optimization principle called the majorization-minimization algorithm. Experimental evaluations show the effectiveness of the proposed method.
Independent Deeply Learned Tensor Analysis for Determined Audio Source Separation
Jun 10, 2021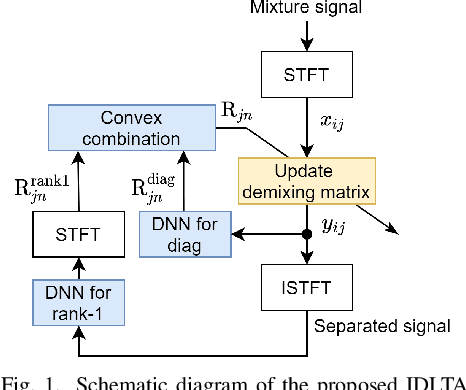

We address the determined audio source separation problem in the time-frequency domain. In independent deeply learned matrix analysis (IDLMA), it is assumed that the inter-frequency correlation of each source spectrum is zero, which is inappropriate for modeling nonstationary signals such as music signals. To account for the correlation between frequencies, independent positive semidefinite tensor analysis has been proposed. This unsupervised (blind) method, however, severely restrict the structure of frequency covariance matrices (FCMs) to reduce the number of model parameters. As an extension of these conventional approaches, we here propose a supervised method that models FCMs using deep neural networks (DNNs). It is difficult to directly infer FCMs using DNNs. Therefore, we also propose a new FCM model represented as a convex combination of a diagonal FCM and a rank-1 FCM. Our FCM model is flexible enough to not only consider inter-frequency correlation, but also capture the dynamics of time-varying FCMs of nonstationary signals. We infer the proposed FCMs using two DNNs: DNN for power spectrum estimation and DNN for time-domain signal estimation. An experimental result of separating music signals shows that the proposed method provides higher separation performance than IDLMA.
Empirical Bayesian Independent Deeply Learned Matrix Analysis For Multichannel Audio Source Separation
Jun 07, 2021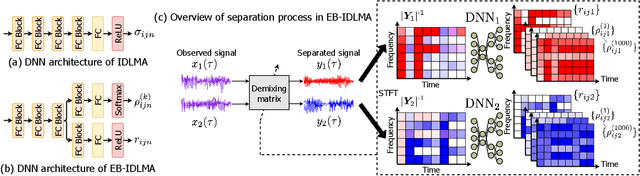
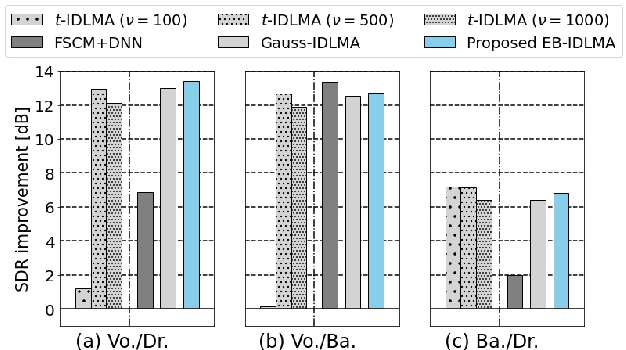
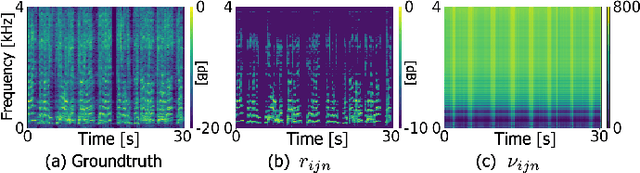
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art supervised multichannel audio source separation methods. It blindly estimates the demixing filters on the basis of source independence, using the source model estimated by the deep neural network (DNN). However, since the ratios of the source to interferer signals vary widely among time-frequency (TF) slots, it is difficult to obtain reliable estimated power spectrograms of sources at all TF slots. In this paper, we propose an IDLMA extension, empirical Bayesian IDLMA (EB-IDLMA), by introducing a prior distribution of source power spectrograms and treating the source power spectrograms as latent random variables. This treatment allows us to implicitly consider the reliability of the estimated source power spectrograms for the estimation of demixing filters through the hyperparameters of the prior distribution estimated by the DNN. Experimental evaluations show the effectiveness of EB-IDLMA and the importance of introducing the reliability of the estimated source power spectrograms.
Deficient Basis Estimation of Noise Spatial Covariance Matrix for Rank-Constrained Spatial Covariance Matrix Estimation Method in Blind Speech Extraction
May 06, 2021
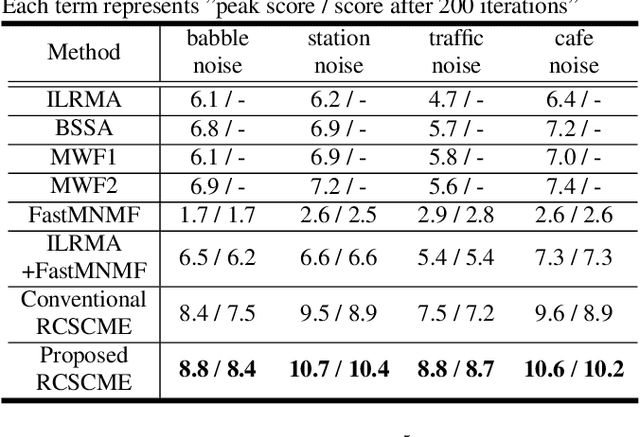
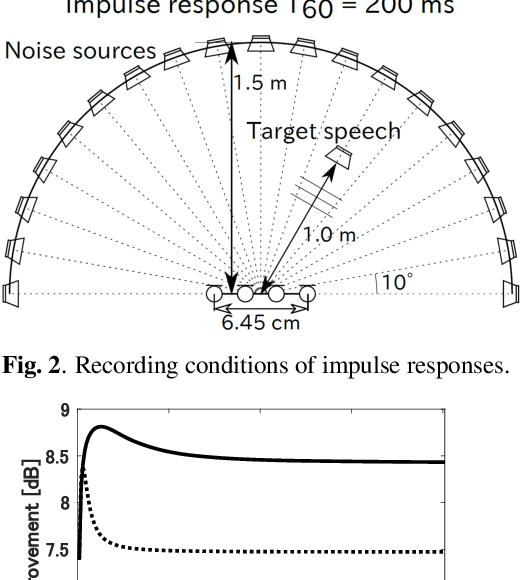
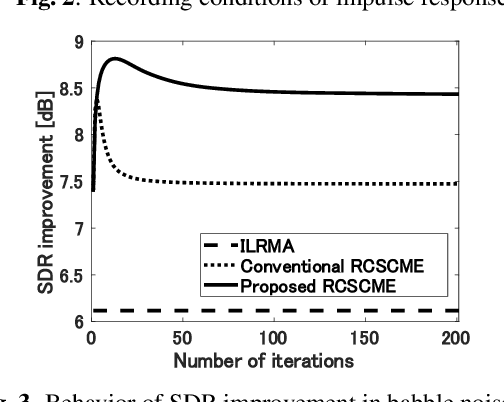
Rank-constrained spatial covariance matrix estimation (RCSCME) is a state-of-the-art blind speech extraction method applied to cases where one directional target speech and diffuse noise are mixed. In this paper, we proposed a new algorithmic extension of RCSCME. RCSCME complements a deficient one rank of the diffuse noise spatial covariance matrix, which cannot be estimated via preprocessing such as independent low-rank matrix analysis, and estimates the source model parameters simultaneously. In the conventional RCSCME, a direction of the deficient basis is fixed in advance and only the scale is estimated; however, the candidate of this deficient basis is not unique in general. In the proposed RCSCME model, the deficient basis itself can be accurately estimated as a vector variable by solving a vector optimization problem. Also, we derive new update rules based on the EM algorithm. We confirm that the proposed method outperforms conventional methods under several noise conditions.