 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Digital Signal Processing Mixture Model for Synthesis Parameter Extraction from Mixture of Harmonic Sounds
Feb 01, 2022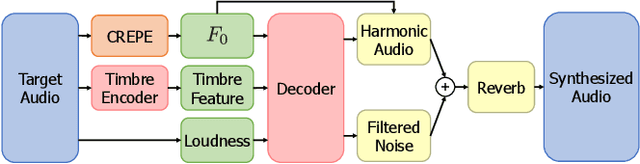


A differentiable digital signal processing (DDSP) autoencoder is a musical sound synthesizer that combines a deep neural network (DNN) and spectral modeling synthesis. It allows us to flexibly edit sounds by changing the fundamental frequency, timbre feature, and loudness (synthesis parameters) extracted from an input sound. However, it is designed for a monophonic harmonic sound and cannot handle mixtures of harmonic sounds. In this paper, we propose a model (DDSP mixture model) that represents a mixture as the sum of the outputs of multiple pretrained DDSP autoencoders. By fitting the output of the proposed model to the observed mixture, we can directly estimate the synthesis parameters of each source. Through synthesis parameter extraction experiments, we show that the proposed method has high and stable performance compared with a straightforward method that applies the DDSP autoencoder to the signals separated by an audio source separation method.
Multichannel Audio Source Separation with Independent Deeply Learned Matrix Analysis Using Product of Source Models
Sep 02, 2021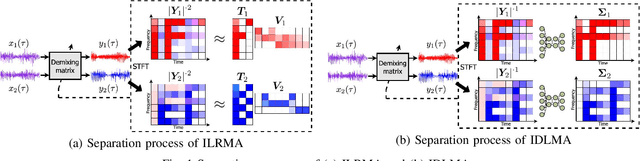
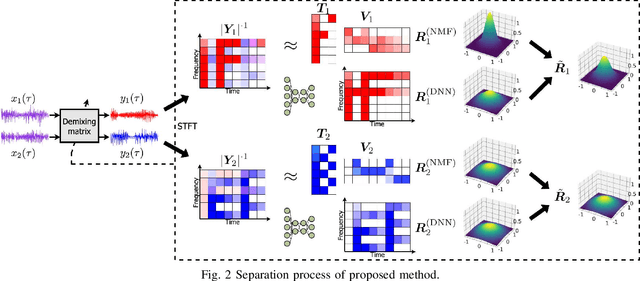
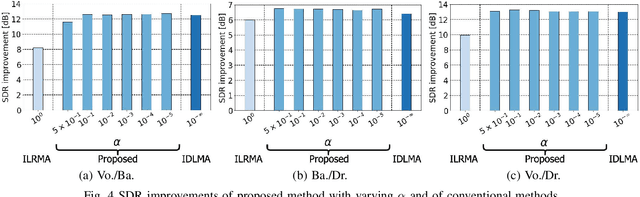
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art multichannel audio source separation methods using the source power estimation based on deep neural networks (DNNs). The DNN-based power estimation works well for sounds having timbres similar to the DNN training data. However, the sounds to which IDLMA is applied do not always have such timbres, and the timbral mismatch causes the performance degradation of IDLMA. To tackle this problem, we focus on a blind source separation counterpart of IDLMA, independent low-rank matrix analysis. It uses nonnegative matrix factorization (NMF) as the source model, which can capture source spectral components that only appear in the target mixture, using the low-rank structure of the source spectrogram as a clue. We thus extend the DNN-based source model to encompass the NMF-based source model on the basis of the product-of-expert concept, which we call the product of source models (PoSM). For the proposed PoSM-based IDLMA, we derive a computationally efficient parameter estimation algorithm based on an optimization principle called the majorization-minimization algorithm. Experimental evaluations show the effectiveness of the proposed method.
Prior Distribution Design for Music Bleeding-Sound Reduction Based on Nonnegative Matrix Factorization
Sep 01, 2021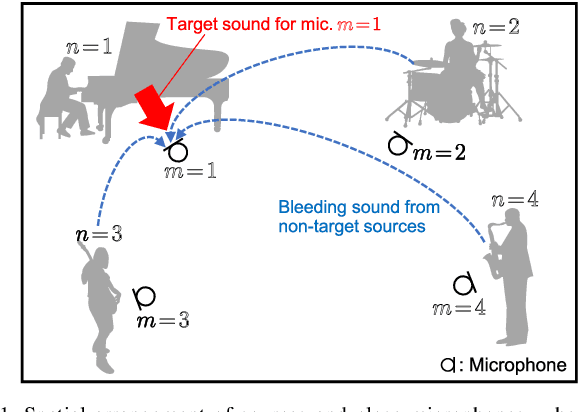

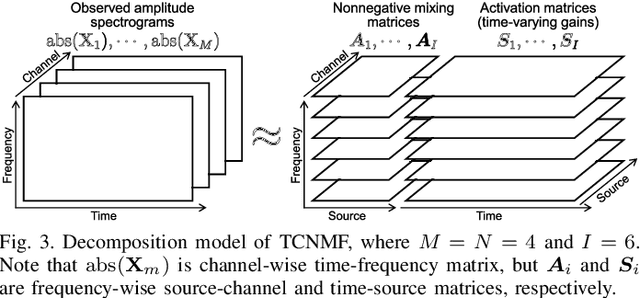

When we place microphones close to a sound source near other sources in audio recording, the obtained audio signal includes undesired sound from the other sources, which is often called cross-talk or bleeding sound. For many audio applications including onstage sound reinforcement and sound editing after a live performance, it is important to reduce the bleeding sound in each recorded signal. However, since microphones are spatially apart from each other in this situation, typical phase-aware blind source separation (BSS) methods cannot be used. We propose a phase-insensitive method for blind bleeding-sound reduction. This method is based on time-channel nonnegative matrix factorization, which is a BSS method using only amplitude spectrograms. With the proposed method, we introduce the gamma-distribution-based prior for leakage levels of bleeding sounds. Its optimization can be interpreted as maximum a posteriori estimation. The experimental results of music bleeding-sound reduction indicate that the proposed method is more effective for bleeding-sound reduction of music signals compared with other BSS methods.
Empirical Bayesian Independent Deeply Learned Matrix Analysis For Multichannel Audio Source Separation
Jun 07, 2021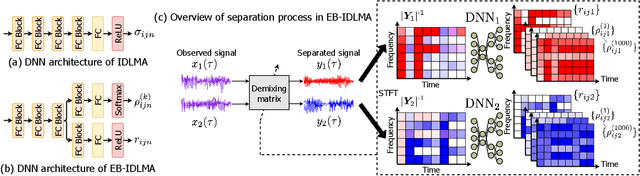
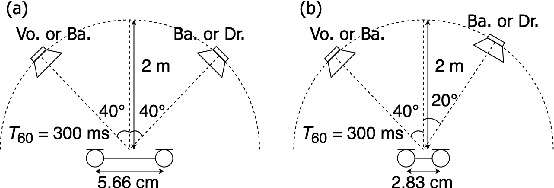
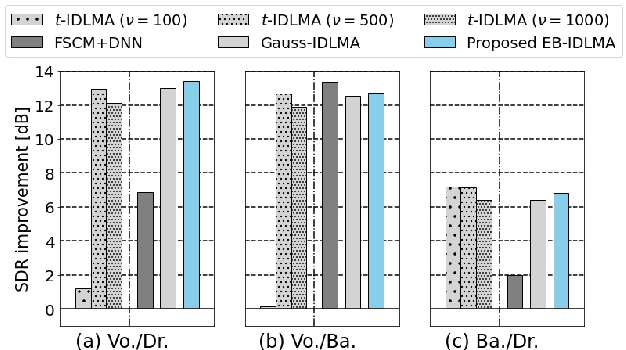
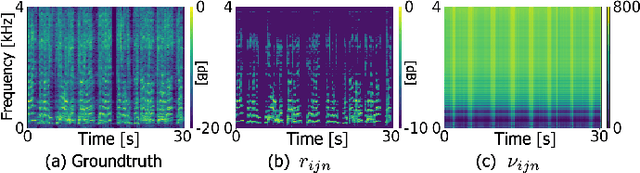
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art supervised multichannel audio source separation methods. It blindly estimates the demixing filters on the basis of source independence, using the source model estimated by the deep neural network (DNN). However, since the ratios of the source to interferer signals vary widely among time-frequency (TF) slots, it is difficult to obtain reliable estimated power spectrograms of sources at all TF slots. In this paper, we propose an IDLMA extension, empirical Bayesian IDLMA (EB-IDLMA), by introducing a prior distribution of source power spectrograms and treating the source power spectrograms as latent random variables. This treatment allows us to implicitly consider the reliability of the estimated source power spectrograms for the estimation of demixing filters through the hyperparameters of the prior distribution estimated by the DNN. Experimental evaluations show the effectiveness of EB-IDLMA and the importance of introducing the reliability of the estimated source power spectrograms.
Monaural source enhancement maximizing source-to-distortion ratio via automatic differentiation
Jun 15, 2018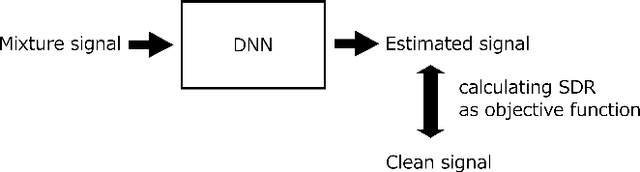

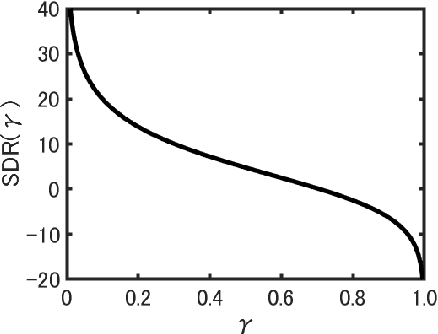
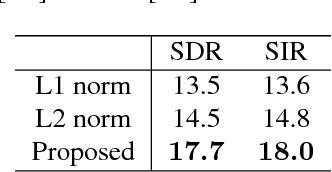
Recently, deep neural network (DNN) has made a breakthrough in monaural source enhancement. Through a training step by using a large amount of data, DNN estimates a mapping between mixed signals and clean signals. At this time, we use an objective function that numerically expresses the quality of a mapping by DNN. In the conventional methods, L1 norm, L2 norm, and Itakura-Saito divergence are often used as objective functions. Recently, an objective function based on short-time objective intelligibility (STOI) has also been proposed. However, these functions only indicate similarity between the clean signal and the estimated signal by DNN. In other words, they do not show the quality of noise reduction or source enhancement. Motivated by the fact, this paper adopts signal-to-distortion ratio (SDR) as the objective function. Since SDR virtually shows signal-to-noise ratio (SNR), maximizing SDR solves the above problem. The experimental results revealed that the proposed method achieved better performance than the conventional methods.