 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Conquer the Embedding Space for Metric Learning
Jun 14, 2019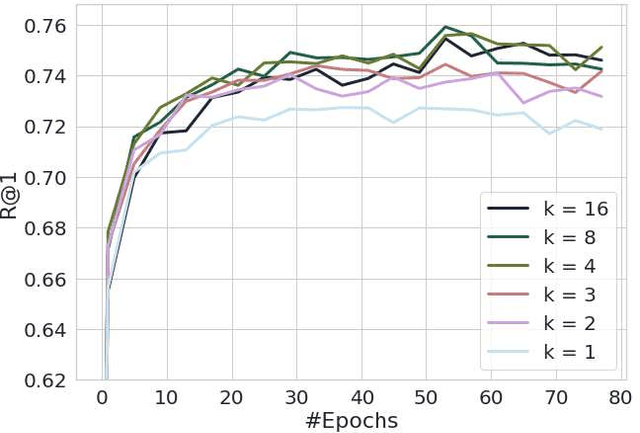
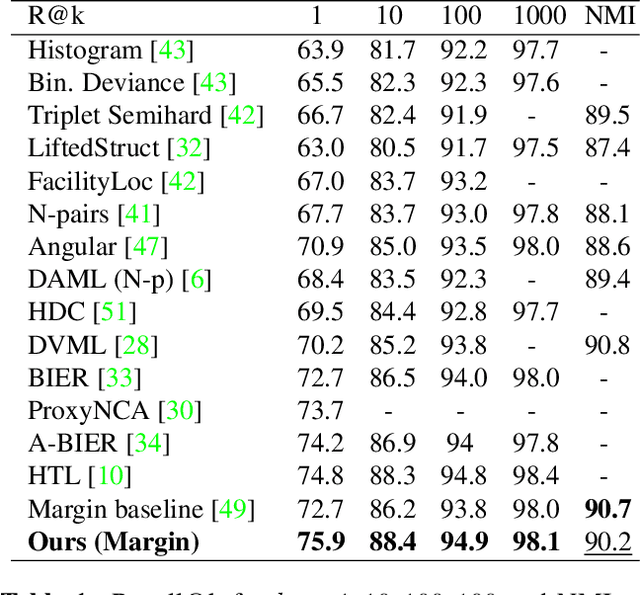
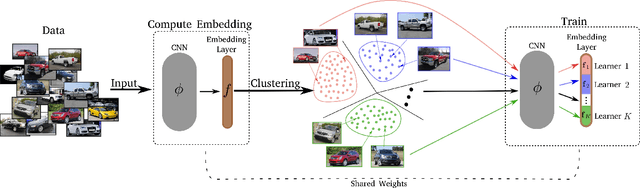
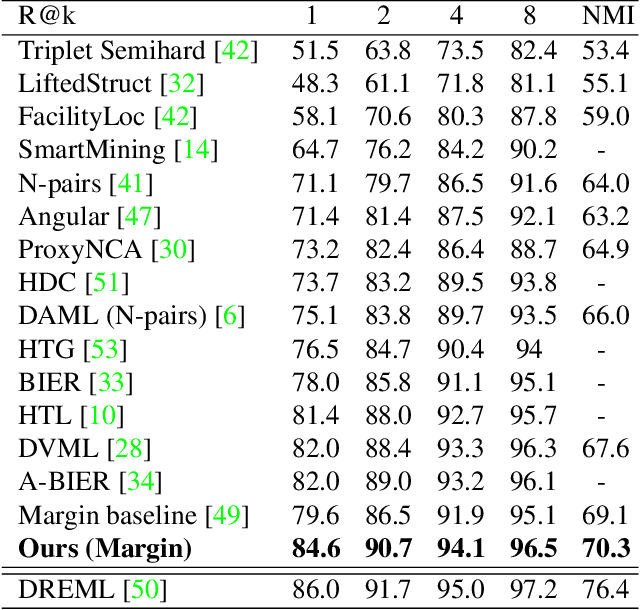
Learning the embedding space, where semantically similar objects are located close together and dissimilar objects far apart, is a cornerstone of many computer vision applications. Existing approaches usually learn a single metric in the embedding space for all available data points, which may have a very complex non-uniform distribution with different notions of similarity between objects, e.g. appearance, shape, color or semantic meaning. Approaches for learning a single distance metric often struggle to encode all different types of relationships and do not generalize well. In this work, we propose a novel easy-to-implement divide and conquer approach for deep metric learning, which significantly improves the state-of-the-art performance of metric learning. Our approach utilizes the embedding space more efficiently by jointly splitting the embedding space and data into $K$ smaller sub-problems. It divides both, the data and the embedding space into $K$ subsets and learns $K$ separate distance metrics in the non-overlapping subspaces of the embedding space, defined by groups of neurons in the embedding layer of the neural network. The proposed approach increases the convergence speed and improves generalization since the complexity of each sub-problem is reduced compared to the original one. We show that our approach outperforms the state-of-the-art by a large margin in retrieval, clustering and re-identification tasks on CUB200-2011, CARS196, Stanford Online Products, In-shop Clothes and PKU VehicleID datasets.
* Source code: https://github.com/CompVis/metric-learning-divide-and-conquer
Improving Spatiotemporal Self-Supervision by Deep Reinforcement Learning
Jul 30, 2018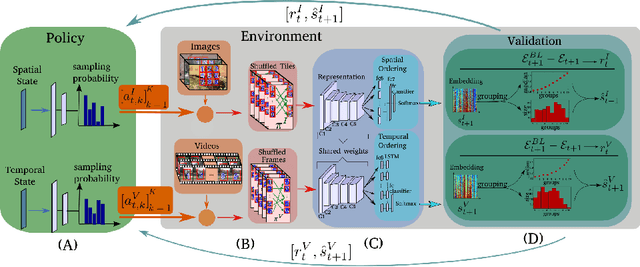



Self-supervised learning of convolutional neural networks can harness large amounts of cheap unlabeled data to train powerful feature representations. As surrogate task, we jointly address ordering of visual data in the spatial and temporal domain. The permutations of training samples, which are at the core of self-supervision by ordering, have so far been sampled randomly from a fixed preselected set. Based on deep reinforcement learning we propose a sampling policy that adapts to the state of the network, which is being trained. Therefore, new permutations are sampled according to their expected utility for updating the convolutional feature representation. Experimental evaluation on unsupervised and transfer learning tasks demonstrates competitive performance on standard benchmarks for image and video classification and nearest neighbor retrieval.