Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCVRL: Shuffled Contrastive Video Representation Learning
Paper and Code
May 24, 2022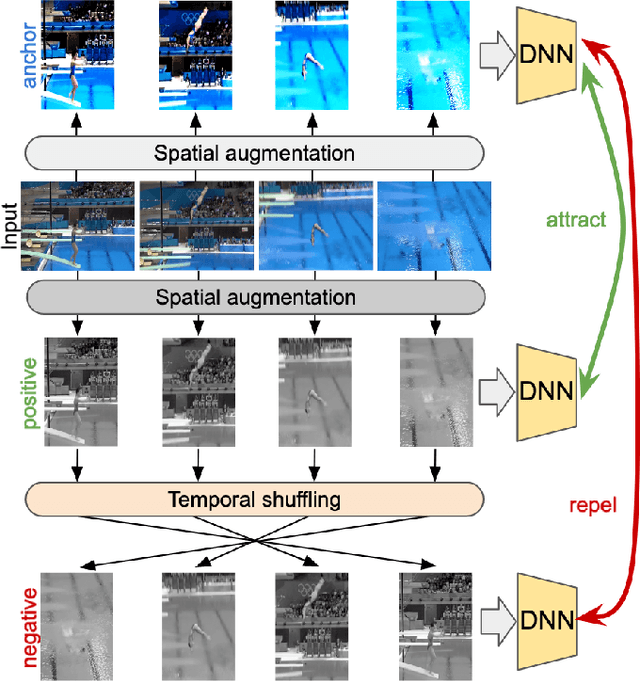
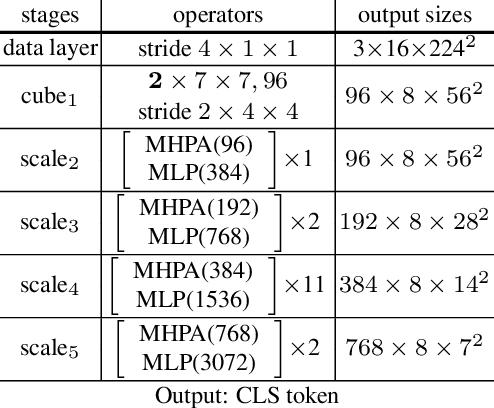
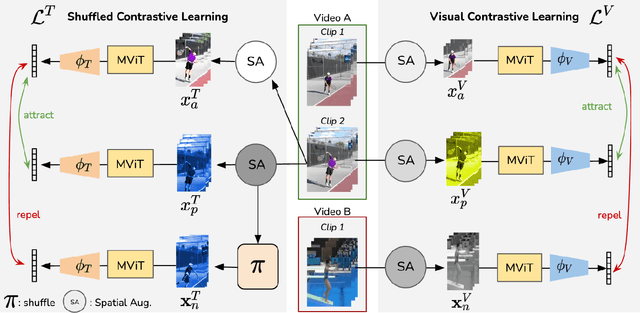
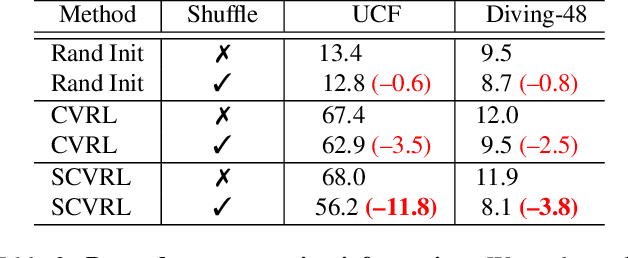
We propose SCVRL, a novel contrastive-based framework for self-supervised learning for videos. Differently from previous contrast learning based methods that mostly focus on learning visual semantics (e.g., CVRL), SCVRL is capable of learning both semantic and motion patterns. For that, we reformulate the popular shuffling pretext task within a modern contrastive learning paradigm. We show that our transformer-based network has a natural capacity to learn motion in self-supervised settings and achieves strong performance, outperforming CVRL on four benchmarks.
* CVPR 2022 - L3DIVU workshop
View paper on