 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Matters for Generalization in Deep Metric Learning
Paper and Code
Apr 12, 2020


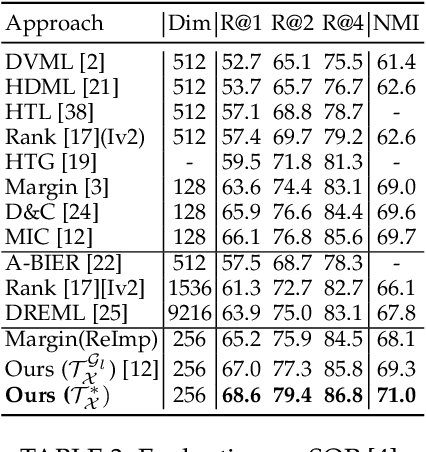
Learning the similarity between images constitutes the foundation for numerous vision tasks. The common paradigm is discriminative metric learning, which seeks an embedding that separates different training classes. However, the main challenge is to learn a metric that not only generalizes from training to novel, but related, test samples. It should also transfer to different object classes. So what complementary information is missed by the discriminative paradigm? Besides finding characteristics that separate between classes, we also need them to likely occur in novel categories, which is indicated if they are shared across training classes. This work investigates how to learn such characteristics without the need for extra annotations or training data. By formulating our approach as a novel triplet sampling strategy, it can be easily applied on top of recent ranking loss frameworks. Experiments show that, independent of the underlying network architecture and the specific ranking loss, our approach significantly improves performance in deep metric learning, leading to new the state-of-the-art results on various standard benchmark datasets.