 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Just Object, But State: Compositional Incremental Learning without Forgetting
Nov 05, 2024Most incremental learners excessively prioritize coarse classes of objects while neglecting various kinds of states (e.g. color and material) attached to the objects. As a result, they are limited in the ability to reason fine-grained compositionality of state-object pairs. To remedy this limitation, we propose a novel task called Compositional Incremental Learning (composition-IL), enabling the model to recognize state-object compositions as a whole in an incremental learning fashion. Since the lack of suitable benchmarks, we re-organize two existing datasets and make them tailored for composition-IL. Then, we propose a prompt-based Composition Incremental Learner (CompILer), to overcome the ambiguous composition boundary problem which challenges composition-IL largely. Specifically, we exploit multi-pool prompt learning, which is regularized by inter-pool prompt discrepancy and intra-pool prompt diversity. Besides, we devise object-injected state prompting by using object prompts to guide the selection of state prompts. Furthermore, we fuse the selected prompts by a generalized-mean strategy, to eliminate irrelevant information learned in the prompts. Extensive experiments on two datasets exhibit state-of-the-art performance achieved by CompILer.
CSCNET: Class-Specified Cascaded Network for Compositional Zero-Shot Learning
Mar 13, 2024



Attribute and object (A-O) disentanglement is a fundamental and critical problem for Compositional Zero-shot Learning (CZSL), whose aim is to recognize novel A-O compositions based on foregone knowledge. Existing methods based on disentangled representation learning lose sight of the contextual dependency between the A-O primitive pairs. Inspired by this, we propose a novel A-O disentangled framework for CZSL, namely Class-specified Cascaded Network (CSCNet). The key insight is to firstly classify one primitive and then specifies the predicted class as a priori for guiding another primitive recognition in a cascaded fashion. To this end, CSCNet constructs Attribute-to-Object and Object-to-Attribute cascaded branches, in addition to a composition branch modeling the two primitives as a whole. Notably, we devise a parametric classifier (ParamCls) to improve the matching between visual and semantic embeddings. By improving the A-O disentanglement, our framework achieves superior results than previous competitive methods.
VidTr: Video Transformer Without Convolutions
Apr 23, 2021
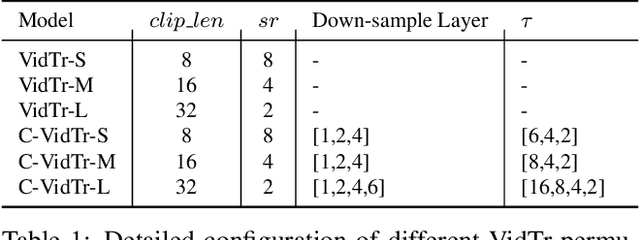
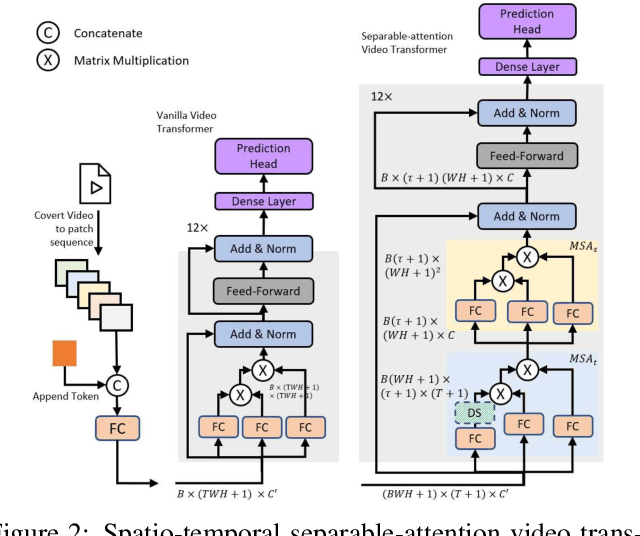
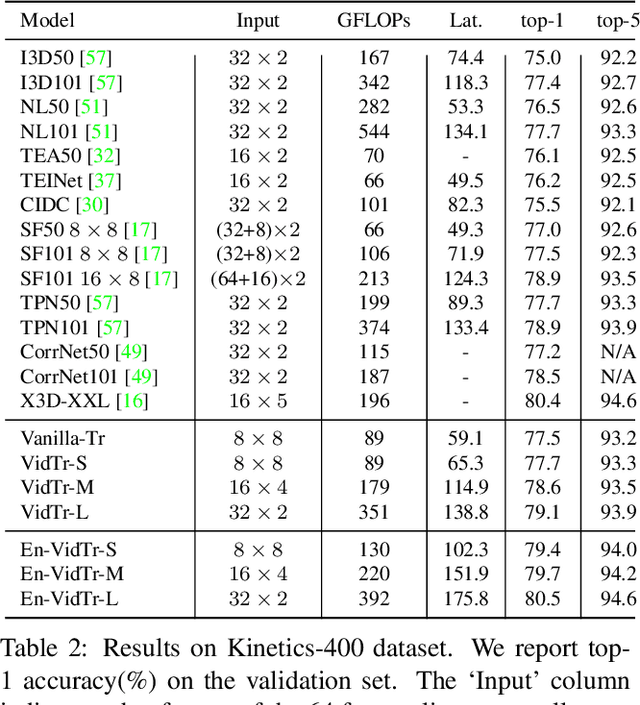
We introduce Video Transformer (VidTr) with separable-attention for video classification. Comparing with commonly used 3D networks, VidTr is able to aggregate spatio-temporal information via stacked attentions and provide better performance with higher efficiency. We first introduce the vanilla video transformer and show that transformer module is able to perform spatio-temporal modeling from raw pixels, but with heavy memory usage. We then present VidTr which reduces the memory cost by 3.3$\times$ while keeping the same performance. To further compact the model, we propose the standard deviation based topK pooling attention, which reduces the computation by dropping non-informative features. VidTr achieves state-of-the-art performance on five commonly used dataset with lower computational requirement, showing both the efficiency and effectiveness of our design. Finally, error analysis and visualization show that VidTr is especially good at predicting actions that require long-term temporal reasoning. The code and pre-trained weights will be released.
Multi-Label Activity Recognition using Activity-specific Features
Sep 16, 2020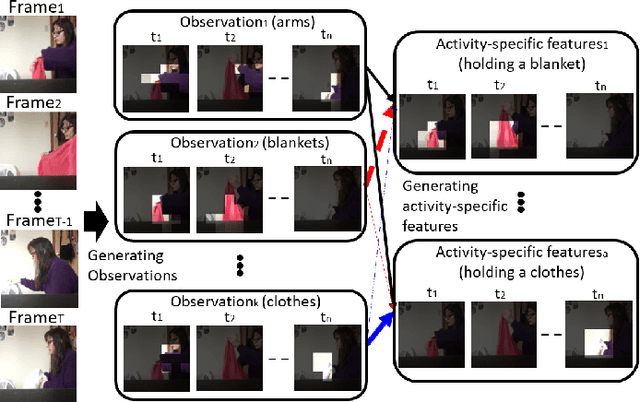
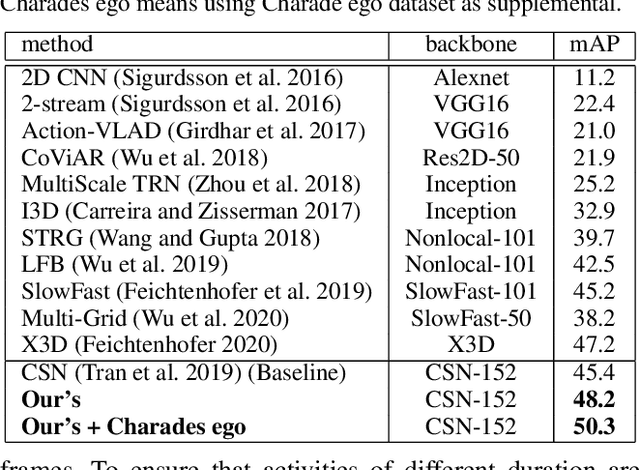
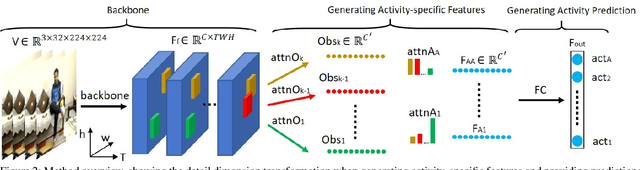

We introduce an approach to multi-label activity recognition by extracting independent feature descriptors for each activity. Our approach first extracts a set of independent feature snippets, focused on different spatio-temporal regions of a video, that we call "observations". We then generate independent feature descriptors for each activity, that we call "activity-specific features" by combining these observations with attention, and further make action prediction based on these activity-specific features. This structure can be trained end-to-end and plugged into any existing network structures for video classification. Our method outperformed state-of-the-art approaches on three multi-label activity recognition datasets. We also evaluated the method and achieved state-of-the-art performance on two single-activity recognition datasets to show the generalizability of our approach. Furthermore, to better understand the activity-specific features that the system generates, we visualized these activity-specific features in the Charades dataset.
Tri-axial Self-Attention for Concurrent Activity Recognition
Dec 06, 2018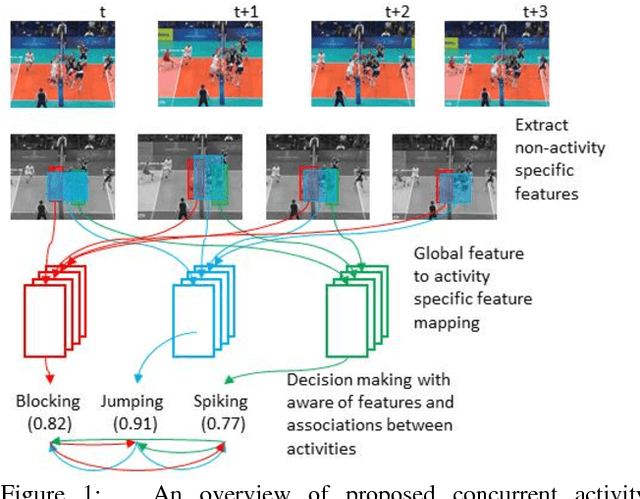
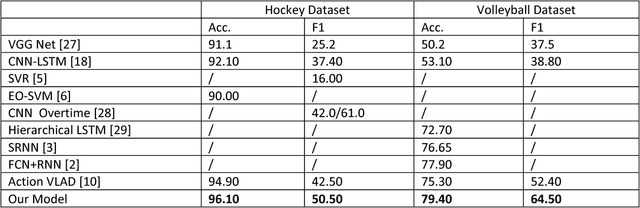
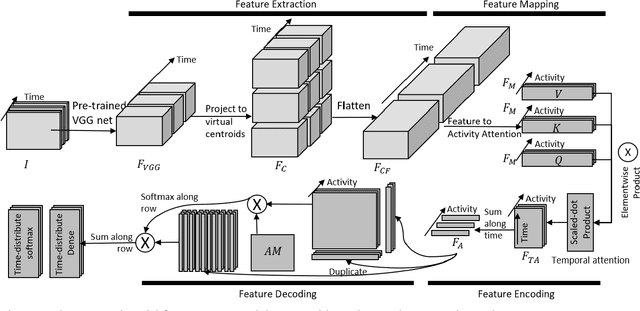
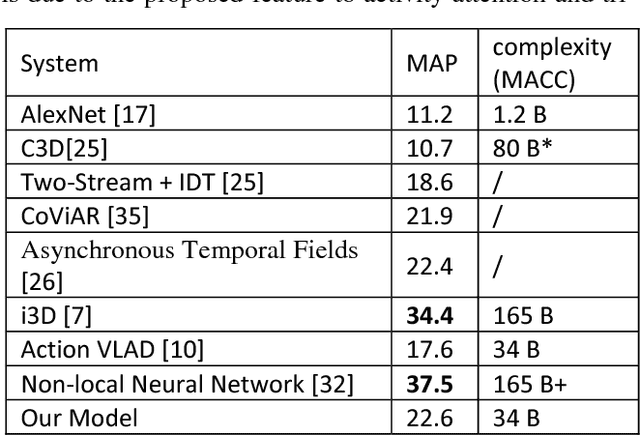
We present a system for concurrent activity recognition. To extract features associated with different activities, we propose a feature-to-activity attention that maps the extracted global features to sub-features associated with individual activities. To model the temporal associations of individual activities, we propose a transformer-network encoder that models independent temporal associations for each activity. To make the concurrent activity prediction aware of the potential associations between activities, we propose self-attention with an association mask. Our system achieved state-of-the-art or comparable performance on three commonly used concurrent activity detection datasets. Our visualizations demonstrate that our system is able to locate the important spatial-temporal features for final decision making. We also showed that our system can be applied to general multilabel classification problems.
Progress Estimation and Phase Detection for Sequential Processes
Jul 14, 2017

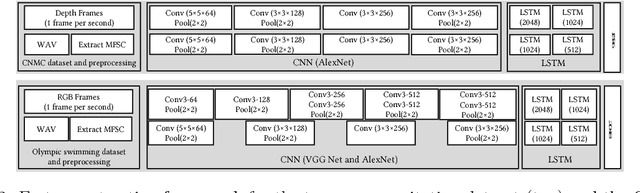
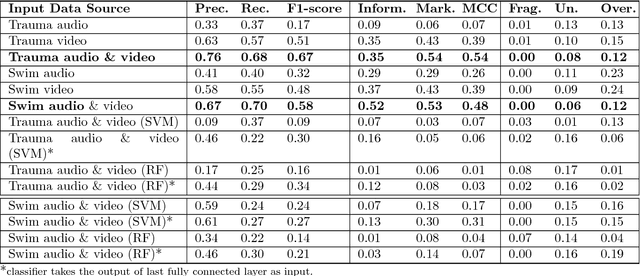
Process modeling and understanding are fundamental for advanced human-computer interfaces and automation systems. Most recent research has focused on activity recognition, but little has been done on sensor-based detection of process progress. We introduce a real-time, sensor-based system for modeling, recognizing and estimating the progress of a work process. We implemented a multimodal deep learning structure to extract the relevant spatio-temporal features from multiple sensory inputs and used a novel deep regression structure for overall completeness estimation. Using process completeness estimation with a Gaussian mixture model, our system can predict the phase for sequential processes. The performance speed, calculated using completeness estimation, allows online estimation of the remaining time. To train our system, we introduced a novel rectified hyperbolic tangent (rtanh) activation function and conditional loss. Our system was tested on data obtained from the medical process (trauma resuscitation) and sports events (Olympic swimming competition). Our system outperformed the existing trauma-resuscitation phase detectors with a phase detection accuracy of over 86%, an F1-score of 0.67, a completeness estimation error of under 12.6%, and a remaining-time estimation error of less than 7.5 minutes. For the Olympic swimming dataset, our system achieved an accuracy of 88%, an F1-score of 0.58, a completeness estimation error of 6.3% and a remaining-time estimation error of 2.9 minutes.
Concurrent Activity Recognition with Multimodal CNN-LSTM Structure
Feb 06, 2017
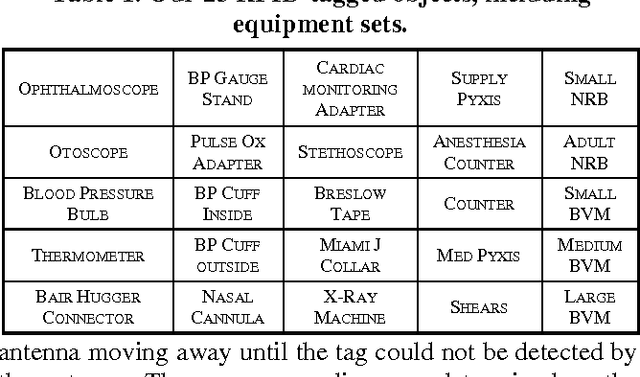
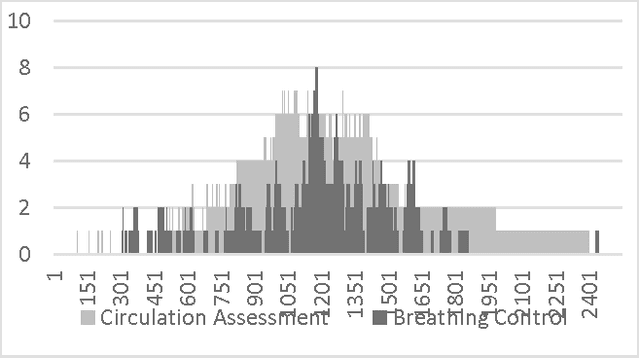
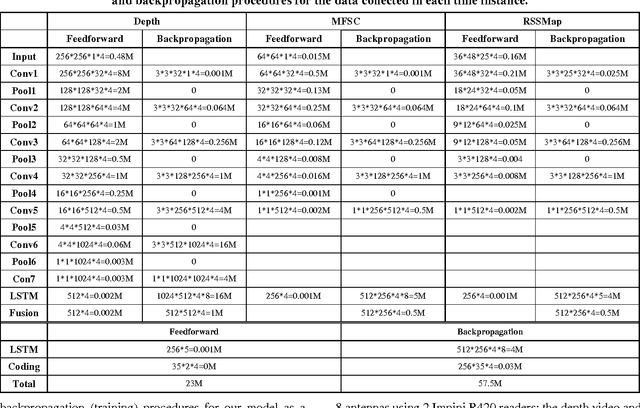
We introduce a system that recognizes concurrent activities from real-world data captured by multiple sensors of different types. The recognition is achieved in two steps. First, we extract spatial and temporal features from the multimodal data. We feed each datatype into a convolutional neural network that extracts spatial features, followed by a long-short term memory network that extracts temporal information in the sensory data. The extracted features are then fused for decision making in the second step. Second, we achieve concurrent activity recognition with a single classifier that encodes a binary output vector in which elements indicate whether the corresponding activity types are currently in progress. We tested our system with three datasets from different domains recorded using different sensors and achieved performance comparable to existing systems designed specifically for those domains. Our system is the first to address the concurrent activity recognition with multisensory data using a single model, which is scalable, simple to train and easy to deploy.