 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Activity Recognition using Activity-specific Features
Paper and Code
Sep 16, 2020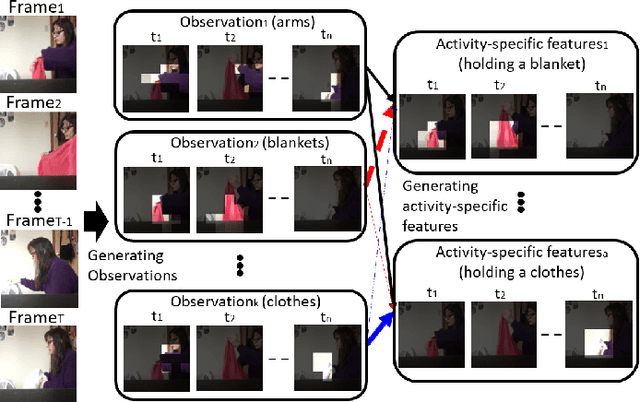
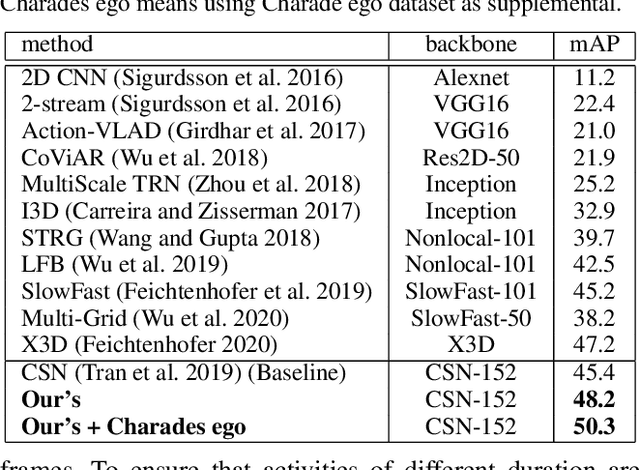
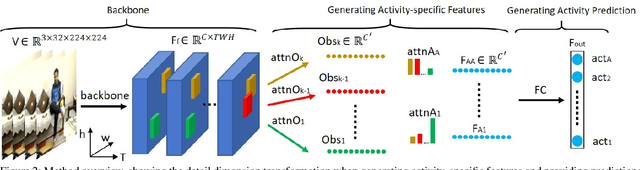

We introduce an approach to multi-label activity recognition by extracting independent feature descriptors for each activity. Our approach first extracts a set of independent feature snippets, focused on different spatio-temporal regions of a video, that we call "observations". We then generate independent feature descriptors for each activity, that we call "activity-specific features" by combining these observations with attention, and further make action prediction based on these activity-specific features. This structure can be trained end-to-end and plugged into any existing network structures for video classification. Our method outperformed state-of-the-art approaches on three multi-label activity recognition datasets. We also evaluated the method and achieved state-of-the-art performance on two single-activity recognition datasets to show the generalizability of our approach. Furthermore, to better understand the activity-specific features that the system generates, we visualized these activity-specific features in the Charades dataset.