 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Training of Neural Networks at Arbitrary Precision and Sparsity
Sep 14, 2024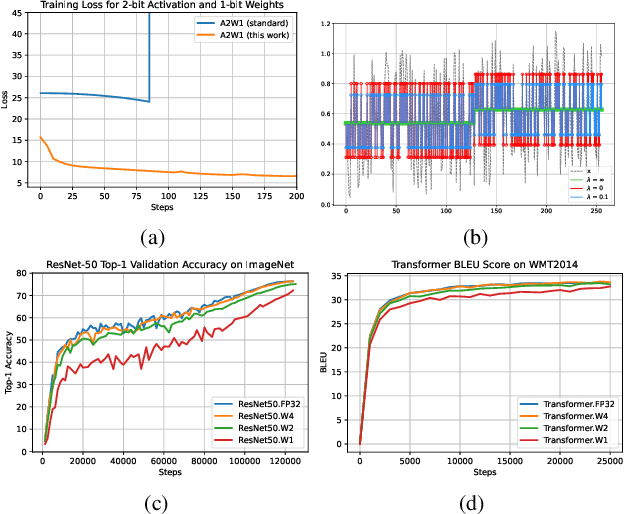
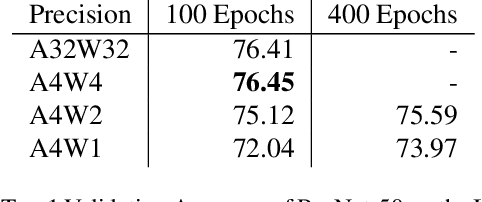

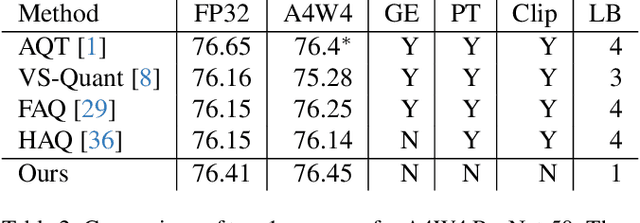
The discontinuous operations inherent in quantization and sparsification introduce obstacles to backpropagation. This is particularly challenging when training deep neural networks in ultra-low precision and sparse regimes. We propose a novel, robust, and universal solution: a denoising affine transform that stabilizes training under these challenging conditions. By formulating quantization and sparsification as perturbations during training, we derive a perturbation-resilient approach based on ridge regression. Our solution employs a piecewise constant backbone model to ensure a performance lower bound and features an inherent noise reduction mechanism to mitigate perturbation-induced corruption. This formulation allows existing models to be trained at arbitrarily low precision and sparsity levels with off-the-shelf recipes. Furthermore, our method provides a novel perspective on training temporal binary neural networks, contributing to ongoing efforts to narrow the gap between artificial and biological neural networks.
Integrating Deep Learning and Synthetic Biology: A Co-Design Approach for Enhancing Gene Expression via N-terminal Coding Sequences
Feb 20, 2024N-terminal coding sequence (NCS) influences gene expression by impacting the translation initiation rate. The NCS optimization problem is to find an NCS that maximizes gene expression. The problem is important in genetic engineering. However, current methods for NCS optimization such as rational design and statistics-guided approaches are labor-intensive yield only relatively small improvements. This paper introduces a deep learning/synthetic biology co-designed few-shot training workflow for NCS optimization. Our method utilizes k-nearest encoding followed by word2vec to encode the NCS, then performs feature extraction using attention mechanisms, before constructing a time-series network for predicting gene expression intensity, and finally a direct search algorithm identifies the optimal NCS with limited training data. We took green fluorescent protein (GFP) expressed by Bacillus subtilis as a reporting protein of NCSs, and employed the fluorescence enhancement factor as the metric of NCS optimization. Within just six iterative experiments, our model generated an NCS (MLD62) that increased average GFP expression by 5.41-fold, outperforming the state-of-the-art NCS designs. Extending our findings beyond GFP, we showed that our engineered NCS (MLD62) can effectively boost the production of N-acetylneuraminic acid by enhancing the expression of the crucial rate-limiting GNA1 gene, demonstrating its practical utility. We have open-sourced our NCS expression database and experimental procedures for public use.
RSSOD-Bench: A large-scale benchmark dataset for Salient Object Detection in Optical Remote Sensing Imagery
Jun 04, 2023We present the RSSOD-Bench dataset for salient object detection (SOD) in optical remote sensing imagery. While SOD has achieved success in natural scene images with deep learning, research in SOD for remote sensing imagery (RSSOD) is still in its early stages. Existing RSSOD datasets have limitations in terms of scale, and scene categories, which make them misaligned with real-world applications. To address these shortcomings, we construct the RSSOD-Bench dataset, which contains images from four different cities in the USA. The dataset provides annotations for various salient object categories, such as buildings, lakes, rivers, highways, bridges, aircraft, ships, athletic fields, and more. The salient objects in RSSOD-Bench exhibit large-scale variations, cluttered backgrounds, and different seasons. Unlike existing datasets, RSSOD-Bench offers uniform distribution across scene categories. We benchmark 23 different state-of-the-art approaches from both the computer vision and remote sensing communities. Experimental results demonstrate that more research efforts are required for the RSSOD task.
E2ETag: An End-to-End Trainable Method for Generating and Detecting Fiducial Markers
May 29, 2021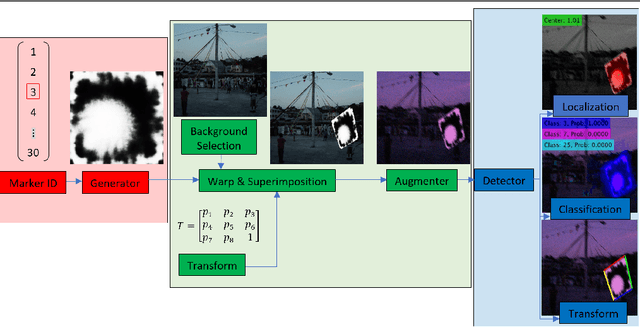
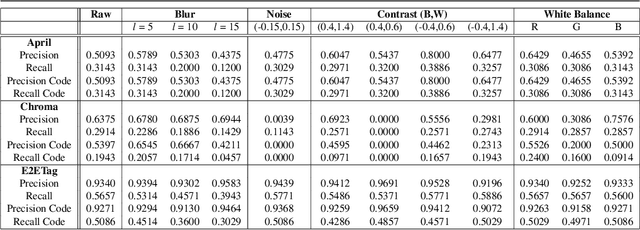


Existing fiducial markers solutions are designed for efficient detection and decoding, however, their ability to stand out in natural environments is difficult to infer from relatively limited analysis. Furthermore, worsening performance in challenging image capture scenarios - such as poor exposure, motion blur, and off-axis viewing - sheds light on their limitations. E2ETag introduces an end-to-end trainable method for designing fiducial markers and a complimentary detector. By introducing back-propagatable marker augmentation and superimposition into training, the method learns to generate markers that can be detected and classified in challenging real-world environments using a fully convolutional detector network. Results demonstrate that E2ETag outperforms existing methods in ideal conditions and performs much better in the presence of motion blur, contrast fluctuations, noise, and off-axis viewing angles. Source code and trained models are available at https://github.com/jbpeace/E2ETag.
Exploiting Invariance in Training Deep Neural Networks
Mar 30, 2021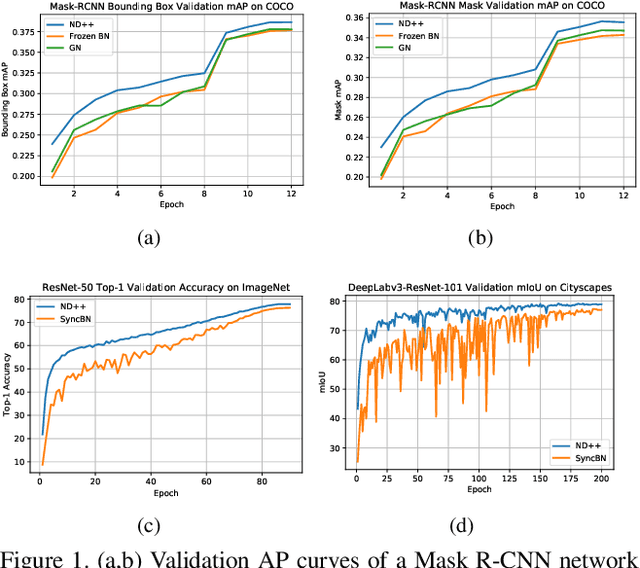
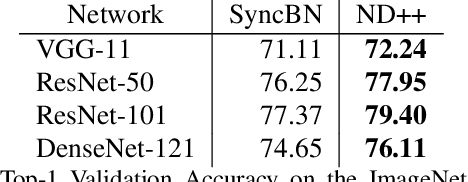
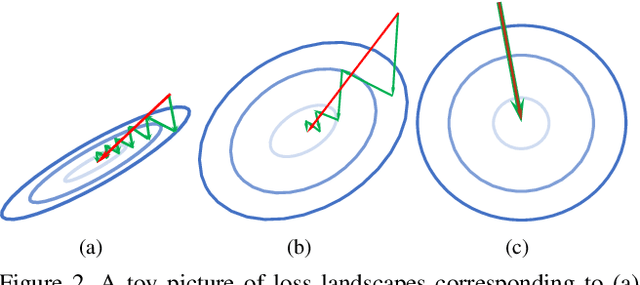

Inspired by two basic mechanisms in animal visual systems, we introduce a feature transform technique that imposes invariance properties in the training of deep neural networks. The resulting algorithm requires less parameter tuning, trains well with an initial learning rate 1.0, and easily generalizes to different tasks. We enforce scale invariance with local statistics in the data to align similar samples generated in diverse situations. To accelerate convergence, we enforce a GL(n)-invariance property with global statistics extracted from a batch that the gradient descent solution should remain invariant under basis change. Tested on ImageNet, MS COCO, and Cityscapes datasets, our proposed technique requires fewer iterations to train, surpasses all baselines by a large margin, seamlessly works on both small and large batch size training, and applies to different computer vision tasks of image classification, object detection, and semantic segmentation.
Layered Embeddings for Amodal Instance Segmentation
Feb 14, 2020
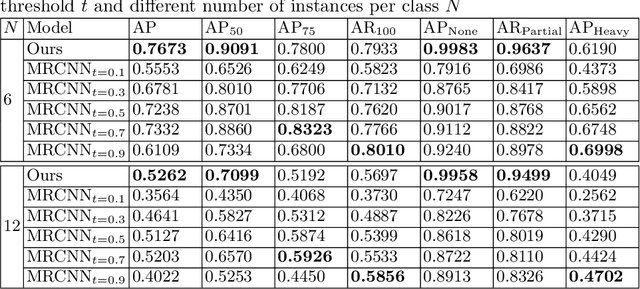
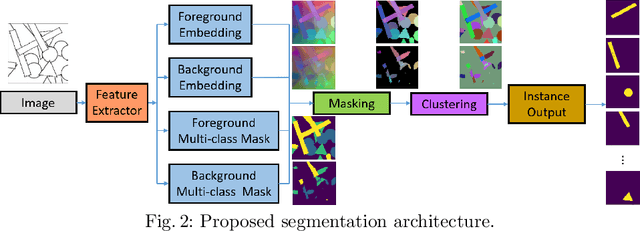
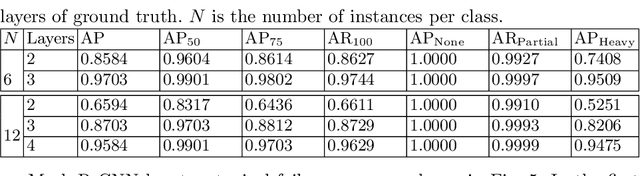
The proposed method extends upon the representational output of semantic instance segmentation by explicitly including both visible and occluded parts. A fully convolutional network is trained to produce consistent pixel-level embedding across two layers such that, when clustered, the results convey the full spatial extent and depth ordering of each instance. Results demonstrate that the network can accurately estimate complete masks in the presence of occlusion and outperform leading top-down bounding-box approaches. Source code available at https://github.com/yanfengliu/layered_embeddings