Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered Embeddings for Amodal Instance Segmentation
Paper and Code

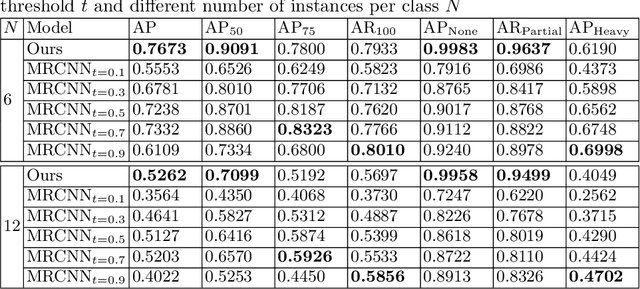
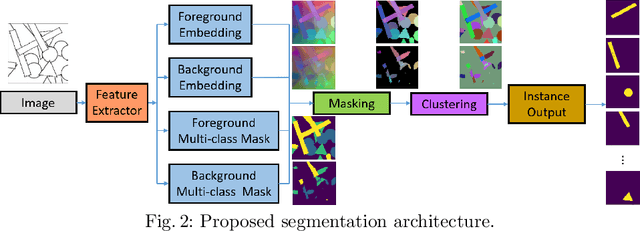
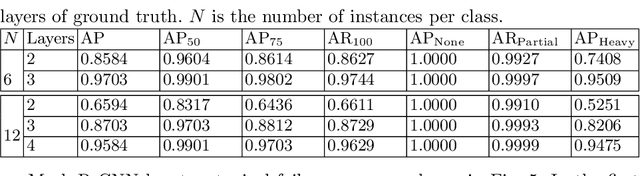
The proposed method extends upon the representational output of semantic instance segmentation by explicitly including both visible and occluded parts. A fully convolutional network is trained to produce consistent pixel-level embedding across two layers such that, when clustered, the results convey the full spatial extent and depth ordering of each instance. Results demonstrate that the network can accurately estimate complete masks in the presence of occlusion and outperform leading top-down bounding-box approaches. Source code available at https://github.com/yanfengliu/layered_embeddings
* International Conference on Image Analysis and Recognition. Springer,
Cham, 2019 (ICIAR 2019)
View paper on