 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2ETag: An End-to-End Trainable Method for Generating and Detecting Fiducial Markers
May 29, 2021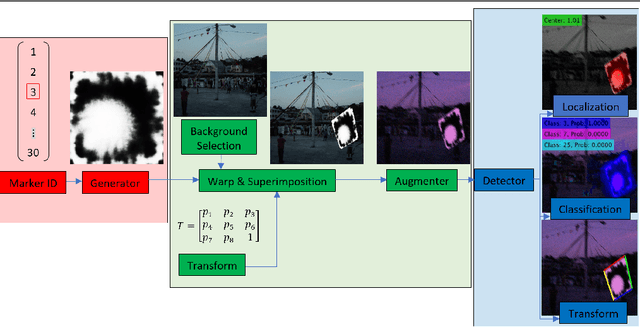
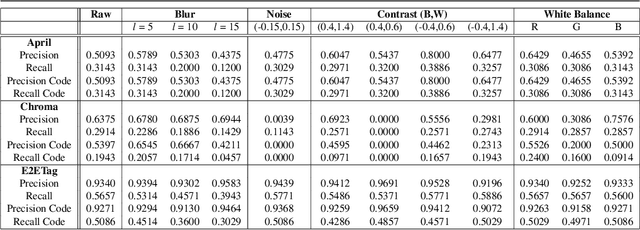


Existing fiducial markers solutions are designed for efficient detection and decoding, however, their ability to stand out in natural environments is difficult to infer from relatively limited analysis. Furthermore, worsening performance in challenging image capture scenarios - such as poor exposure, motion blur, and off-axis viewing - sheds light on their limitations. E2ETag introduces an end-to-end trainable method for designing fiducial markers and a complimentary detector. By introducing back-propagatable marker augmentation and superimposition into training, the method learns to generate markers that can be detected and classified in challenging real-world environments using a fully convolutional detector network. Results demonstrate that E2ETag outperforms existing methods in ideal conditions and performs much better in the presence of motion blur, contrast fluctuations, noise, and off-axis viewing angles. Source code and trained models are available at https://github.com/jbpeace/E2ETag.
Layered Embeddings for Amodal Instance Segmentation
Feb 14, 2020
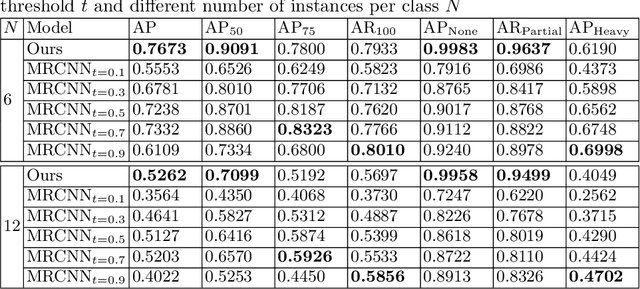
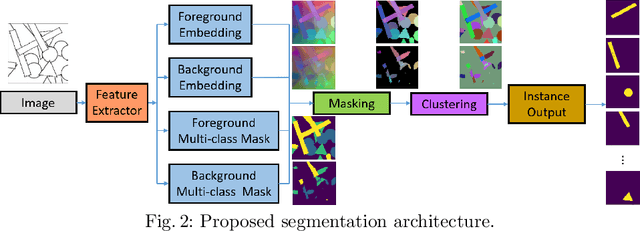
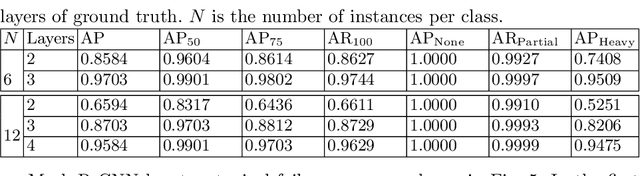
The proposed method extends upon the representational output of semantic instance segmentation by explicitly including both visible and occluded parts. A fully convolutional network is trained to produce consistent pixel-level embedding across two layers such that, when clustered, the results convey the full spatial extent and depth ordering of each instance. Results demonstrate that the network can accurately estimate complete masks in the presence of occlusion and outperform leading top-down bounding-box approaches. Source code available at https://github.com/yanfengliu/layered_embeddings