 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCal: Unified Neural Sensor Calibration
Sep 27, 2024



Self-driving vehicles (SDVs) require accurate calibration of LiDARs and cameras to fuse sensor data accurately for autonomy. Traditional calibration methods typically leverage fiducials captured in a controlled and structured scene and compute correspondences to optimize over. These approaches are costly and require substantial infrastructure and operations, making it challenging to scale for vehicle fleets. In this work, we propose UniCal, a unified framework for effortlessly calibrating SDVs equipped with multiple LiDARs and cameras. Our approach is built upon a differentiable scene representation capable of rendering multi-view geometrically and photometrically consistent sensor observations. We jointly learn the sensor calibration and the underlying scene representation through differentiable volume rendering, utilizing outdoor sensor data without the need for specific calibration fiducials. This "drive-and-calibrate" approach significantly reduces costs and operational overhead compared to existing calibration systems, enabling efficient calibration for large SDV fleets at scale. To ensure geometric consistency across observations from different sensors, we introduce a novel surface alignment loss that combines feature-based registration with neural rendering. Comprehensive evaluations on multiple datasets demonstrate that UniCal outperforms or matches the accuracy of existing calibration approaches while being more efficient, demonstrating the value of UniCal for scalable calibration.
CADSim: Robust and Scalable in-the-wild 3D Reconstruction for Controllable Sensor Simulation
Nov 02, 2023Realistic simulation is key to enabling safe and scalable development of % self-driving vehicles. A core component is simulating the sensors so that the entire autonomy system can be tested in simulation. Sensor simulation involves modeling traffic participants, such as vehicles, with high quality appearance and articulated geometry, and rendering them in real time. The self-driving industry has typically employed artists to build these assets. However, this is expensive, slow, and may not reflect reality. Instead, reconstructing assets automatically from sensor data collected in the wild would provide a better path to generating a diverse and large set with good real-world coverage. Nevertheless, current reconstruction approaches struggle on in-the-wild sensor data, due to its sparsity and noise. To tackle these issues, we present CADSim, which combines part-aware object-class priors via a small set of CAD models with differentiable rendering to automatically reconstruct vehicle geometry, including articulated wheels, with high-quality appearance. Our experiments show our method recovers more accurate shapes from sparse data compared to existing approaches. Importantly, it also trains and renders efficiently. We demonstrate our reconstructed vehicles in several applications, including accurate testing of autonomy perception systems.
Deep Multi-Task Learning for Joint Localization, Perception, and Prediction
Jan 19, 2021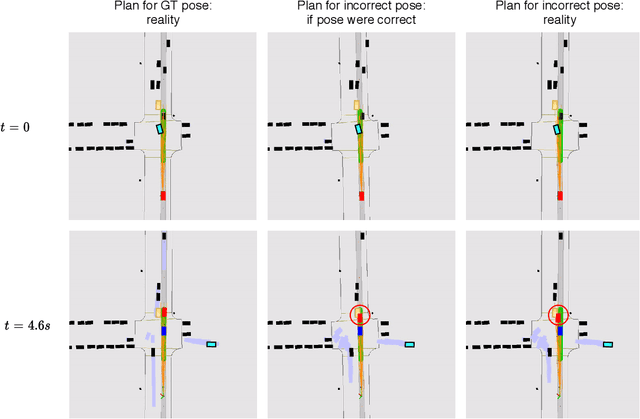

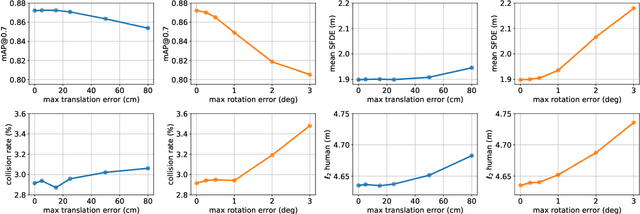

Over the last few years, we have witnessed tremendous progress on many subtasks of autonomous driving, including perception, motion forecasting, and motion planning. However, these systems often assume that the car is accurately localized against a high-definition map. In this paper we question this assumption, and investigate the issues that arise in state-of-the-art autonomy stacks under localization error. Based on our observations, we design a system that jointly performs perception, prediction, and localization. Our architecture is able to reuse computation between both tasks, and is thus able to correct localization errors efficiently. We show experiments on a large-scale autonomy dataset, demonstrating the efficiency and accuracy of our proposed approach.
Asynchronous Multi-View SLAM
Jan 17, 2021
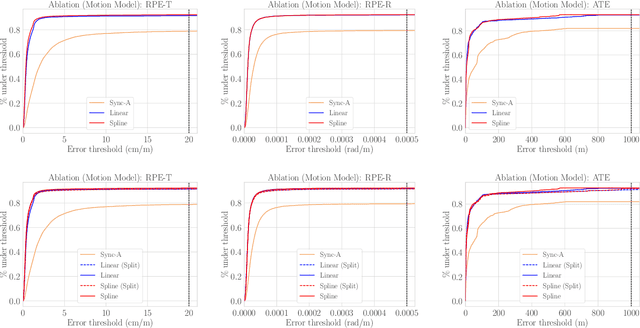
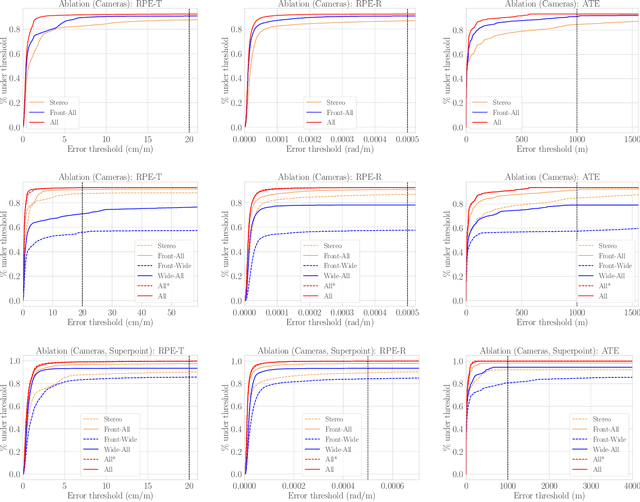
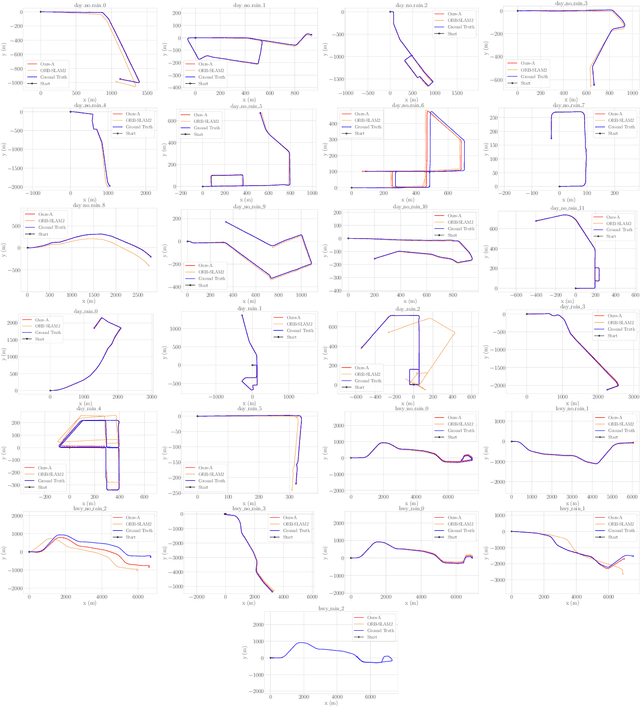
Existing multi-camera SLAM systems assume synchronized shutters for all cameras, which is often not the case in practice. In this work, we propose a generalized multi-camera SLAM formulation which accounts for asynchronous sensor observations. Our framework integrates a continuous-time motion model to relate information across asynchronous multi-frames during tracking, local mapping, and loop closing. For evaluation, we collected AMV-Bench, a challenging new SLAM dataset covering 482 km of driving recorded using our asynchronous multi-camera robotic platform. AMV-Bench is over an order of magnitude larger than previous multi-view HD outdoor SLAM datasets, and covers diverse and challenging motions and environments. Our experiments emphasize the necessity of asynchronous sensor modeling, and show that the use of multiple cameras is critical towards robust and accurate SLAM in challenging outdoor scenes.
Pit30M: A Benchmark for Global Localization in the Age of Self-Driving Cars
Dec 23, 2020



We are interested in understanding whether retrieval-based localization approaches are good enough in the context of self-driving vehicles. Towards this goal, we introduce Pit30M, a new image and LiDAR dataset with over 30 million frames, which is 10 to 100 times larger than those used in previous work. Pit30M is captured under diverse conditions (i.e., season, weather, time of the day, traffic), and provides accurate localization ground truth. We also automatically annotate our dataset with historical weather and astronomical data, as well as with image and LiDAR semantic segmentation as a proxy measure for occlusion. We benchmark multiple existing methods for image and LiDAR retrieval and, in the process, introduce a simple, yet effective convolutional network-based LiDAR retrieval method that is competitive with the state of the art. Our work provides, for the first time, a benchmark for sub-metre retrieval-based localization at city scale. The dataset, additional experimental results, as well as more information about the sensors, calibration, and metadata, are available on the project website: https://uber.com/atg/datasets/pit30m
Learning to Localize Through Compressed Binary Maps
Dec 20, 2020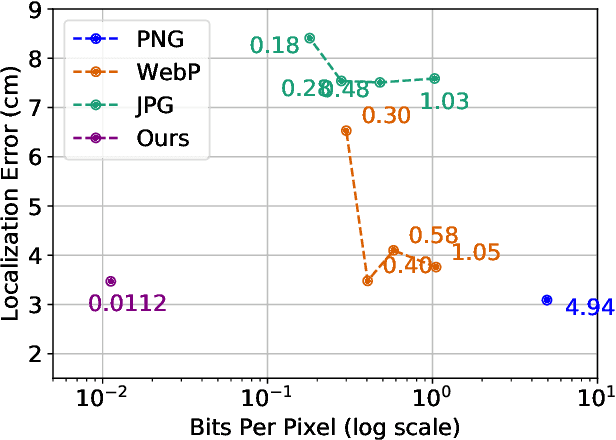
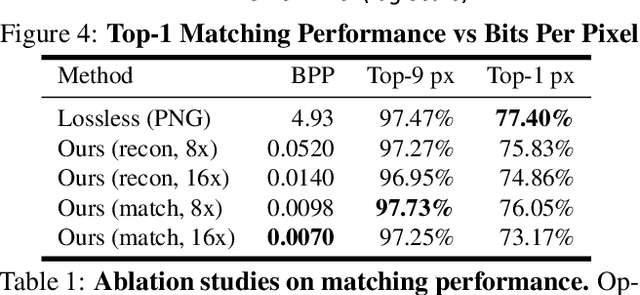
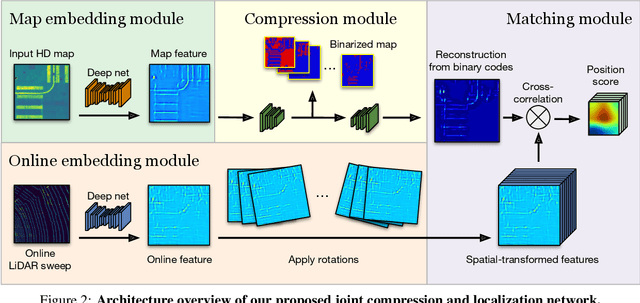
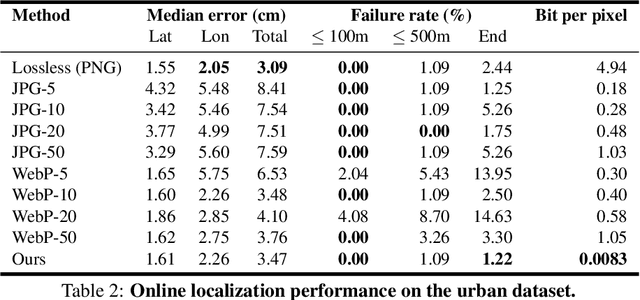
One of the main difficulties of scaling current localization systems to large environments is the on-board storage required for the maps. In this paper we propose to learn to compress the map representation such that it is optimal for the localization task. As a consequence, higher compression rates can be achieved without loss of localization accuracy when compared to standard coding schemes that optimize for reconstruction, thus ignoring the end task. Our experiments show that it is possible to learn a task-specific compression which reduces storage requirements by two orders of magnitude over general-purpose codecs such as WebP without sacrificing performance.
* 18 pages, 12 figures, 6 tables; Presented at CVPR 2019
Learning to Localize Using a LiDAR Intensity Map
Dec 20, 2020

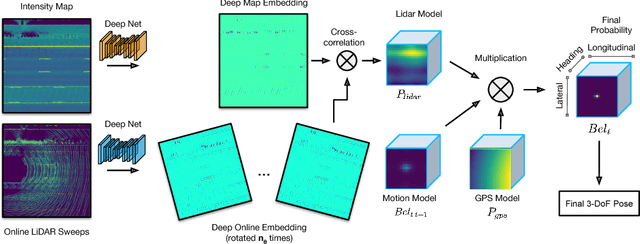

In this paper we propose a real-time, calibration-agnostic and effective localization system for self-driving cars. Our method learns to embed the online LiDAR sweeps and intensity map into a joint deep embedding space. Localization is then conducted through an efficient convolutional matching between the embeddings. Our full system can operate in real-time at 15Hz while achieving centimeter level accuracy across different LiDAR sensors and environments. Our experiments illustrate the performance of the proposed approach over a large-scale dataset consisting of over 4000km of driving.
* 12 pages, 7 figures, 5 tables; Presented at the 2nd Conference on Robot Learning (CoRL), 2018
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
Oct 29, 2020



Compressing large neural networks is an important step for their deployment in resource-constrained computational platforms. In this context, vector quantization is an appealing framework that expresses multiple parameters using a single code, and has recently achieved state-of-the-art network compression on a range of core vision and natural language processing tasks. Key to the success of vector quantization is deciding which parameter groups should be compressed together. Previous work has relied on heuristics that group the spatial dimension of individual convolutional filters, but a general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate modern architectures), linear layers (which have no notion of spatial dimension), and convolutions (when more than one filter is compressed to the same codeword). In this paper we make the observation that the weights of two adjacent layers can be permuted while expressing the same function. We then establish a connection to rate-distortion theory and search for permutations that result in networks that are easier to compress. Finally, we rely on an annealed quantization algorithm to better compress the network and achieve higher final accuracy. We show results on image classification, object detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to the current state of the art.
Exploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization
Aug 08, 2019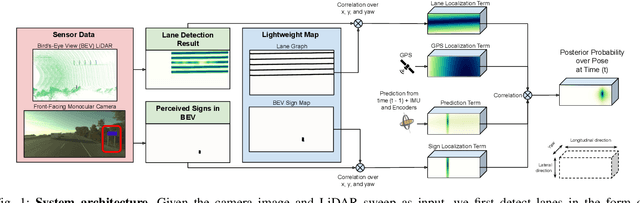
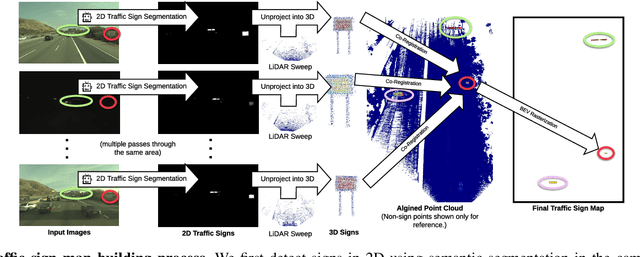

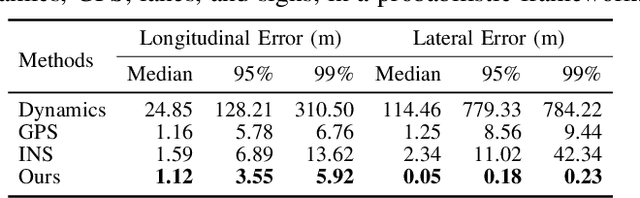
In this paper we propose a novel semantic localization algorithm that exploits multiple sensors and has precision on the order of a few centimeters. Our approach does not require detailed knowledge about the appearance of the world, and our maps require orders of magnitude less storage than maps utilized by traditional geometry- and LiDAR intensity-based localizers. This is important as self-driving cars need to operate in large environments. Towards this goal, we formulate the problem in a Bayesian filtering framework, and exploit lanes, traffic signs, as well as vehicle dynamics to localize robustly with respect to a sparse semantic map. We validate the effectiveness of our method on a new highway dataset consisting of 312km of roads. Our experiments show that the proposed approach is able to achieve 0.05m lateral accuracy and 1.12m longitudinal accuracy on average while taking up only 0.3% of the storage required by previous LiDAR intensity-based approaches.
Robust Dense Mapping for Large-Scale Dynamic Environments
May 07, 2019
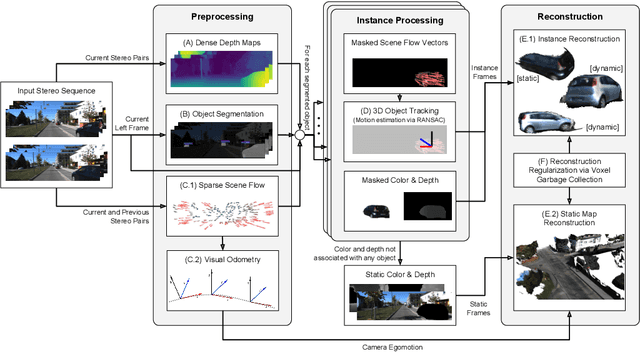


We present a stereo-based dense mapping algorithm for large-scale dynamic urban environments. In contrast to other existing methods, we simultaneously reconstruct the static background, the moving objects, and the potentially moving but currently stationary objects separately, which is desirable for high-level mobile robotic tasks such as path planning in crowded environments. We use both instance-aware semantic segmentation and sparse scene flow to classify objects as either background, moving, or potentially moving, thereby ensuring that the system is able to model objects with the potential to transition from static to dynamic, such as parked cars. Given camera poses estimated from visual odometry, both the background and the (potentially) moving objects are reconstructed separately by fusing the depth maps computed from the stereo input. In addition to visual odometry, sparse scene flow is also used to estimate the 3D motions of the detected moving objects, in order to reconstruct them accurately. A map pruning technique is further developed to improve reconstruction accuracy and reduce memory consumption, leading to increased scalability. We evaluate our system thoroughly on the well-known KITTI dataset. Our system is capable of running on a PC at approximately 2.5Hz, with the primary bottleneck being the instance-aware semantic segmentation, which is a limitation we hope to address in future work. The source code is available from the project website (http://andreibarsan.github.io/dynslam).
* Presented at IEEE International Conference on Robotics and Automation (ICRA), 2018