 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Parametric Continuous Convolutional Neural Networks
Jan 17, 2021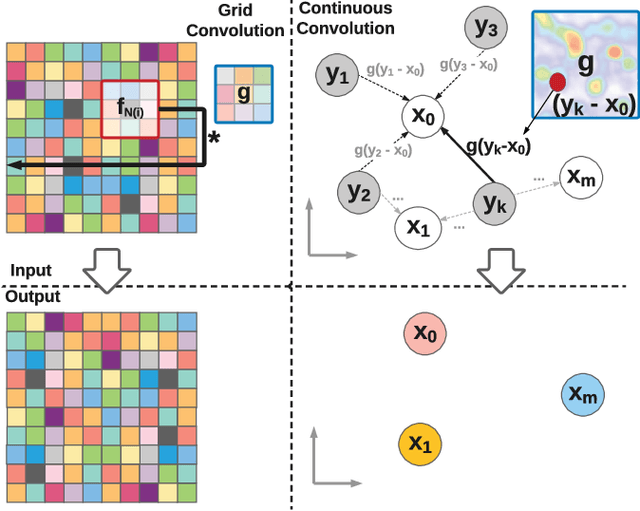

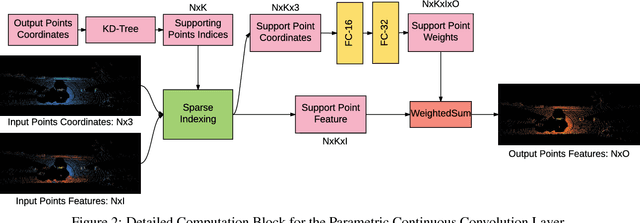
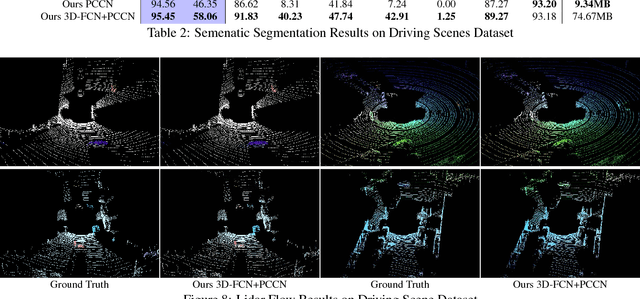
Standard convolutional neural networks assume a grid structured input is available and exploit discrete convolutions as their fundamental building blocks. This limits their applicability to many real-world applications. In this paper we propose Parametric Continuous Convolution, a new learnable operator that operates over non-grid structured data. The key idea is to exploit parameterized kernel functions that span the full continuous vector space. This generalization allows us to learn over arbitrary data structures as long as their support relationship is computable. Our experiments show significant improvement over the state-of-the-art in point cloud segmentation of indoor and outdoor scenes, and lidar motion estimation of driving scenes.
Learning to Localize Using a LiDAR Intensity Map
Dec 20, 2020

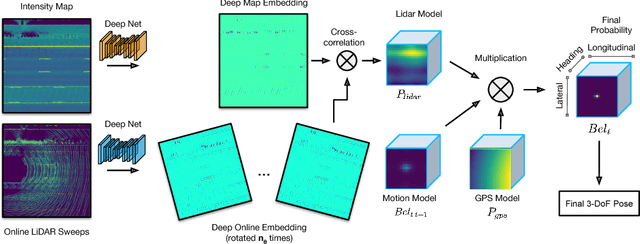

In this paper we propose a real-time, calibration-agnostic and effective localization system for self-driving cars. Our method learns to embed the online LiDAR sweeps and intensity map into a joint deep embedding space. Localization is then conducted through an efficient convolutional matching between the embeddings. Our full system can operate in real-time at 15Hz while achieving centimeter level accuracy across different LiDAR sensors and environments. Our experiments illustrate the performance of the proposed approach over a large-scale dataset consisting of over 4000km of driving.
* 12 pages, 7 figures, 5 tables; Presented at the 2nd Conference on Robot Learning (CoRL), 2018
Jointly Learnable Behavior and Trajectory Planning for Self-Driving Vehicles
Oct 10, 2019



The motion planners used in self-driving vehicles need to generate trajectories that are safe, comfortable, and obey the traffic rules. This is usually achieved by two modules: behavior planner, which handles high-level decisions and produces a coarse trajectory, and trajectory planner that generates a smooth, feasible trajectory for the duration of the planning horizon. These planners, however, are typically developed separately, and changes in the behavior planner might affect the trajectory planner in unexpected ways. Furthermore, the final trajectory outputted by the trajectory planner might differ significantly from the one generated by the behavior planner, as they do not share the same objective. In this paper, we propose a jointly learnable behavior and trajectory planner. Unlike most existing learnable motion planners that address either only behavior planning, or use an uninterpretable neural network to represent the entire logic from sensors to driving commands, our approach features an interpretable cost function on top of perception, prediction and vehicle dynamics, and a joint learning algorithm that learns a shared cost function employed by our behavior and trajectory components. Experiments on real-world self-driving data demonstrate that jointly learned planner performs significantly better in terms of both similarity to human driving and other safety metrics, compared to baselines that do not adopt joint behavior and trajectory learning.
Exploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization
Aug 08, 2019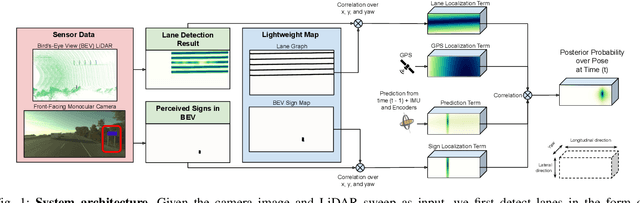
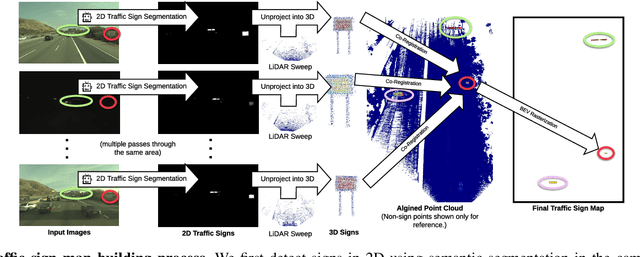

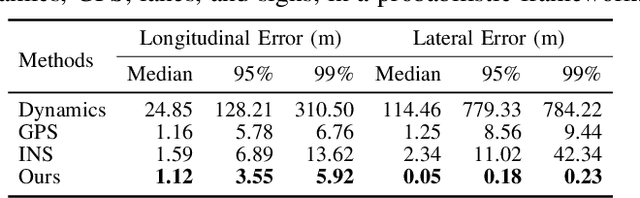
In this paper we propose a novel semantic localization algorithm that exploits multiple sensors and has precision on the order of a few centimeters. Our approach does not require detailed knowledge about the appearance of the world, and our maps require orders of magnitude less storage than maps utilized by traditional geometry- and LiDAR intensity-based localizers. This is important as self-driving cars need to operate in large environments. Towards this goal, we formulate the problem in a Bayesian filtering framework, and exploit lanes, traffic signs, as well as vehicle dynamics to localize robustly with respect to a sparse semantic map. We validate the effectiveness of our method on a new highway dataset consisting of 312km of roads. Our experiments show that the proposed approach is able to achieve 0.05m lateral accuracy and 1.12m longitudinal accuracy on average while taking up only 0.3% of the storage required by previous LiDAR intensity-based approaches.
SBNet: Sparse Blocks Network for Fast Inference
Jun 07, 2018



Conventional deep convolutional neural networks (CNNs) apply convolution operators uniformly in space across all feature maps for hundreds of layers - this incurs a high computational cost for real-time applications. For many problems such as object detection and semantic segmentation, we are able to obtain a low-cost computation mask, either from a priori problem knowledge, or from a low-resolution segmentation network. We show that such computation masks can be used to reduce computation in the high-resolution main network. Variants of sparse activation CNNs have previously been explored on small-scale tasks and showed no degradation in terms of object classification accuracy, but often measured gains in terms of theoretical FLOPs without realizing a practical speed-up when compared to highly optimized dense convolution implementations. In this work, we leverage the sparsity structure of computation masks and propose a novel tiling-based sparse convolution algorithm. We verified the effectiveness of our sparse CNN on LiDAR-based 3D object detection, and we report significant wall-clock speed-ups compared to dense convolution without noticeable loss of accuracy.