 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization
Aug 08, 2019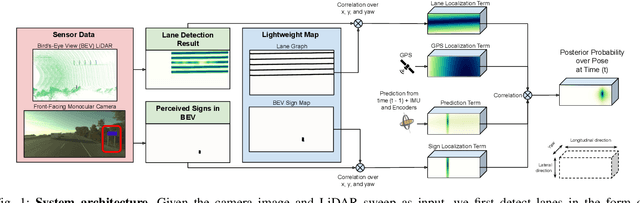
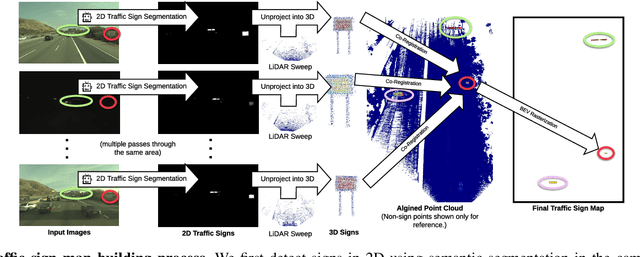

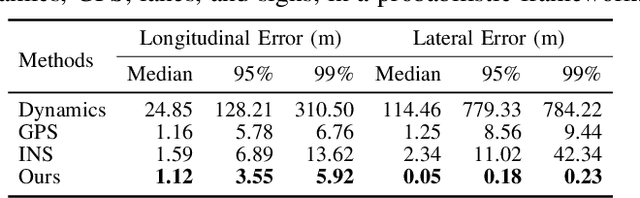
In this paper we propose a novel semantic localization algorithm that exploits multiple sensors and has precision on the order of a few centimeters. Our approach does not require detailed knowledge about the appearance of the world, and our maps require orders of magnitude less storage than maps utilized by traditional geometry- and LiDAR intensity-based localizers. This is important as self-driving cars need to operate in large environments. Towards this goal, we formulate the problem in a Bayesian filtering framework, and exploit lanes, traffic signs, as well as vehicle dynamics to localize robustly with respect to a sparse semantic map. We validate the effectiveness of our method on a new highway dataset consisting of 312km of roads. Our experiments show that the proposed approach is able to achieve 0.05m lateral accuracy and 1.12m longitudinal accuracy on average while taking up only 0.3% of the storage required by previous LiDAR intensity-based approaches.
Deep Multi-Sensor Lane Detection
May 04, 2019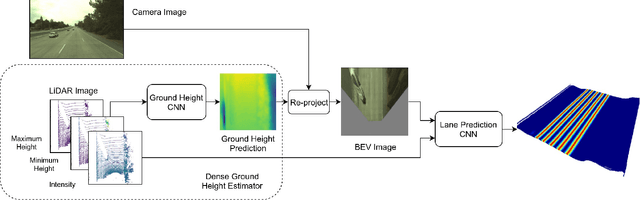

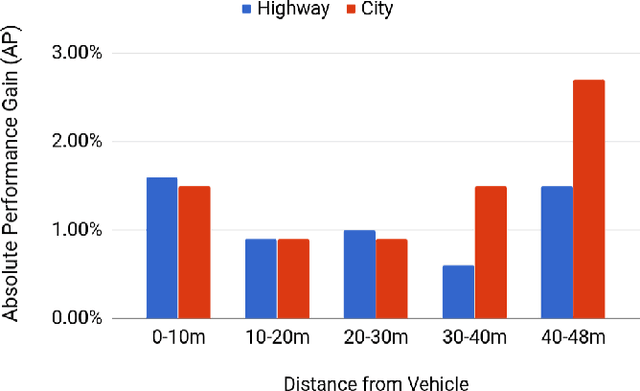
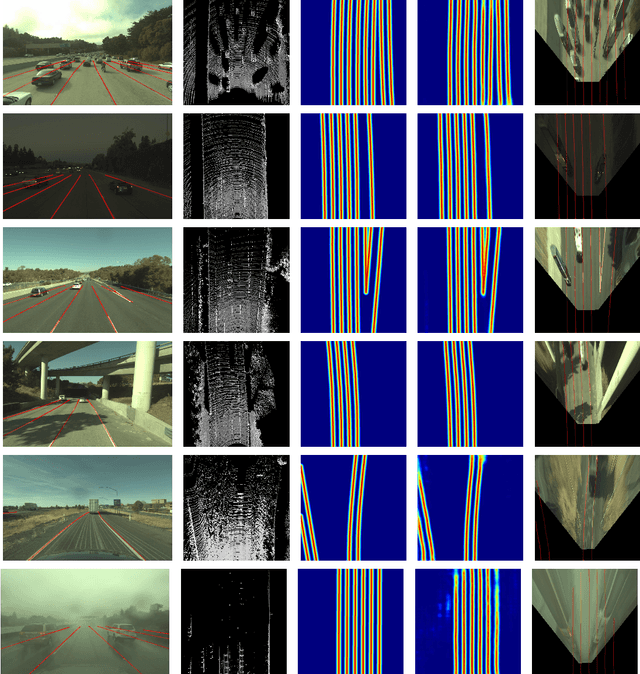
Reliable and accurate lane detection has been a long-standing problem in the field of autonomous driving. In recent years, many approaches have been developed that use images (or videos) as input and reason in image space. In this paper we argue that accurate image estimates do not translate to precise 3D lane boundaries, which are the input required by modern motion planning algorithms. To address this issue, we propose a novel deep neural network that takes advantage of both LiDAR and camera sensors and produces very accurate estimates directly in 3D space. We demonstrate the performance of our approach on both highways and in cities, and show very accurate estimates in complex scenarios such as heavy traffic (which produces occlusion), fork, merges and intersections.
TorontoCity: Seeing the World with a Million Eyes
Dec 01, 2016
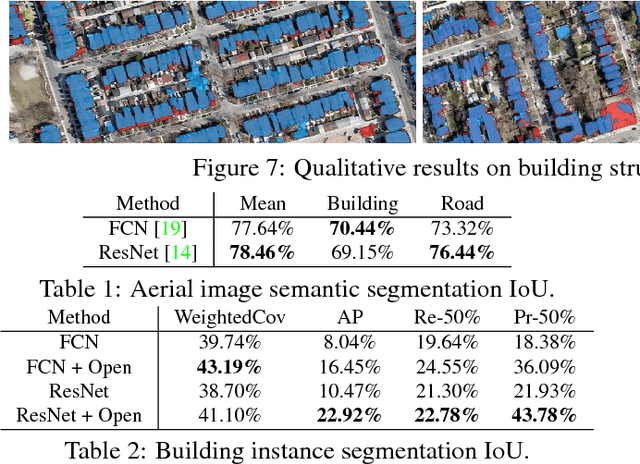


In this paper we introduce the TorontoCity benchmark, which covers the full greater Toronto area (GTA) with 712.5 $km^2$ of land, 8439 $km$ of road and around 400,000 buildings. Our benchmark provides different perspectives of the world captured from airplanes, drones and cars driving around the city. Manually labeling such a large scale dataset is infeasible. Instead, we propose to utilize different sources of high-precision maps to create our ground truth. Towards this goal, we develop algorithms that allow us to align all data sources with the maps while requiring minimal human supervision. We have designed a wide variety of tasks including building height estimation (reconstruction), road centerline and curb extraction, building instance segmentation, building contour extraction (reorganization), semantic labeling and scene type classification (recognition). Our pilot study shows that most of these tasks are still difficult for modern convolutional neural networks.