 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Closed-loop Training for Autonomous Driving
Jun 27, 2023Recent advances in high-fidelity simulators have enabled closed-loop training of autonomous driving agents, potentially solving the distribution shift in training v.s. deployment and allowing training to be scaled both safely and cheaply. However, there is a lack of understanding of how to build effective training benchmarks for closed-loop training. In this work, we present the first empirical study which analyzes the effects of different training benchmark designs on the success of learning agents, such as how to design traffic scenarios and scale training environments. Furthermore, we show that many popular RL algorithms cannot achieve satisfactory performance in the context of autonomous driving, as they lack long-term planning and take an extremely long time to train. To address these issues, we propose trajectory value learning (TRAVL), an RL-based driving agent that performs planning with multistep look-ahead and exploits cheaply generated imagined data for efficient learning. Our experiments show that TRAVL can learn much faster and produce safer maneuvers compared to all the baselines. For more information, visit the project website: https://waabi.ai/research/travl
Weakly Supervised Semantic Segmentation via Alternative Self-Dual Teaching
Dec 17, 2021
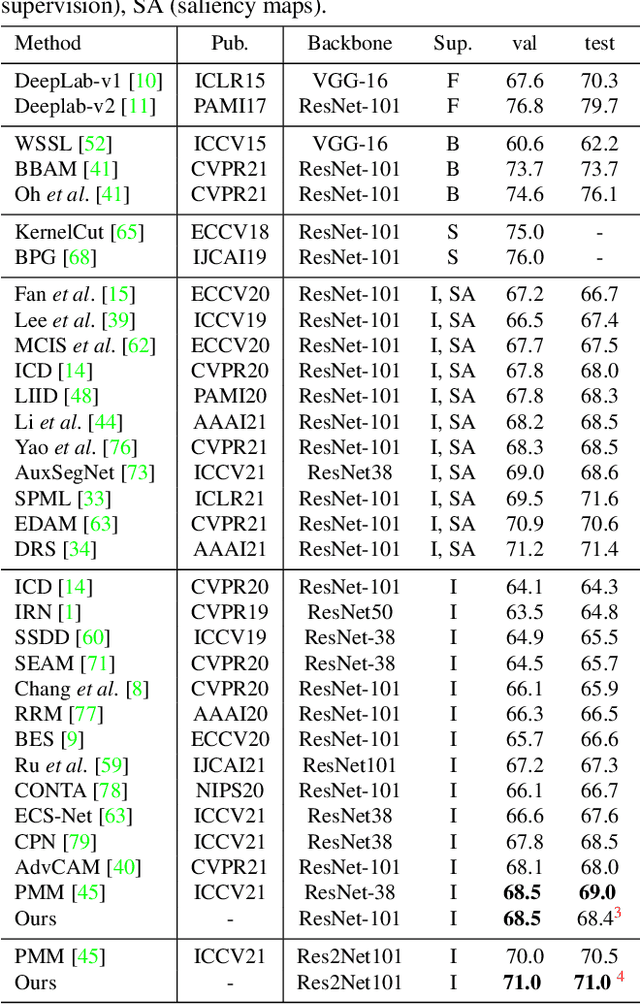
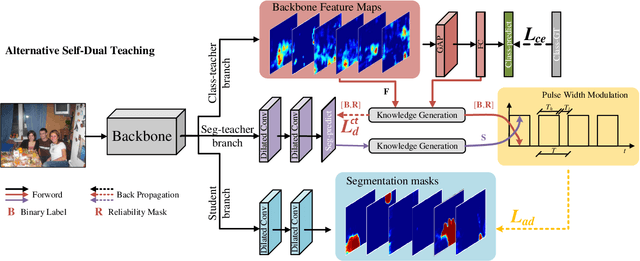

Current weakly supervised semantic segmentation (WSSS) frameworks usually contain the separated mask-refinement model and the main semantic region mining model. These approaches would contain redundant feature extraction backbones and biased learning objectives, making them computational complex yet sub-optimal to addressing the WSSS task. To solve this problem, this paper establishes a compact learning framework that embeds the classification and mask-refinement components into a unified deep model. With the shared feature extraction backbone, our model is able to facilitate knowledge sharing between the two components while preserving a low computational complexity. To encourage high-quality knowledge interaction, we propose a novel alternative self-dual teaching (ASDT) mechanism. Unlike the conventional distillation strategy, the knowledge of the two teacher branches in our model is alternatively distilled to the student branch by a Pulse Width Modulation (PWM), which generates PW wave-like selection signal to guide the knowledge distillation process. In this way, the student branch can help prevent the model from falling into local minimum solutions caused by the imperfect knowledge provided of either teacher branch. Comprehensive experiments on the PASCAL VOC 2012 and COCO-Stuff 10K demonstrate the effectiveness of the proposed alternative self-dual teaching mechanism as well as the new state-of-the-art performance of our approach.
Just Label What You Need: Fine-Grained Active Selection for Perception and Prediction through Partially Labeled Scenes
Apr 08, 2021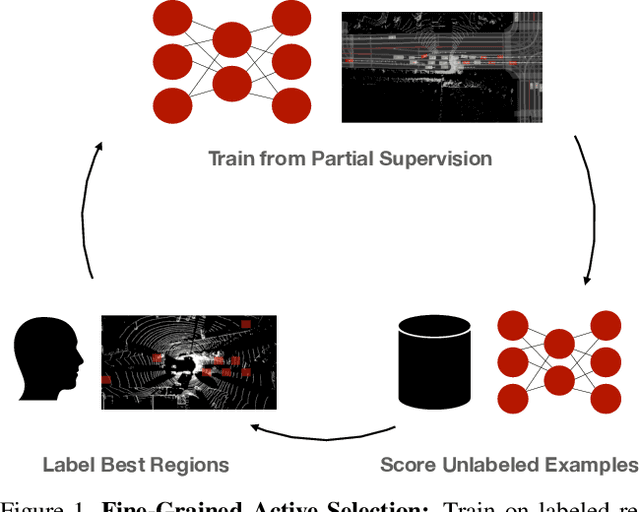
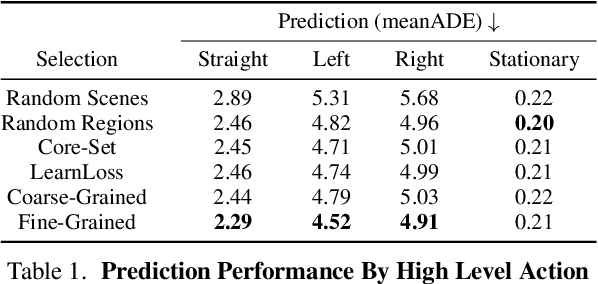
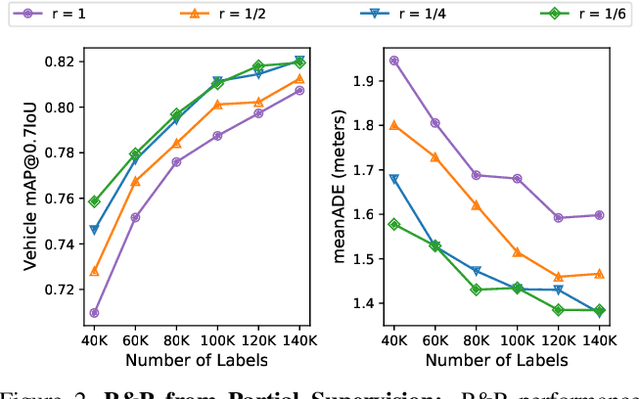
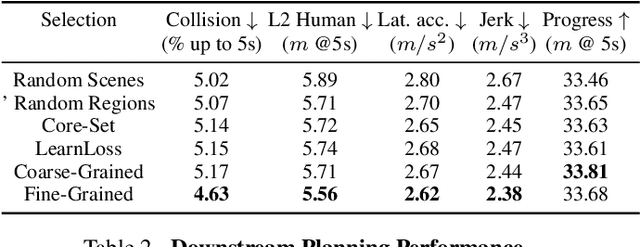
Self-driving vehicles must perceive and predict the future positions of nearby actors in order to avoid collisions and drive safely. A learned deep learning module is often responsible for this task, requiring large-scale, high-quality training datasets. As data collection is often significantly cheaper than labeling in this domain, the decision of which subset of examples to label can have a profound impact on model performance. Active learning techniques, which leverage the state of the current model to iteratively select examples for labeling, offer a promising solution to this problem. However, despite the appeal of this approach, there has been little scientific analysis of active learning approaches for the perception and prediction (P&P) problem. In this work, we study active learning techniques for P&P and find that the traditional active learning formulation is ill-suited for the P&P setting. We thus introduce generalizations that ensure that our approach is both cost-aware and allows for fine-grained selection of examples through partially labeled scenes. Our experiments on a real-world, large-scale self-driving dataset suggest that fine-grained selection can improve the performance across perception, prediction, and downstream planning tasks.
Deep Structured Reactive Planning
Jan 18, 2021
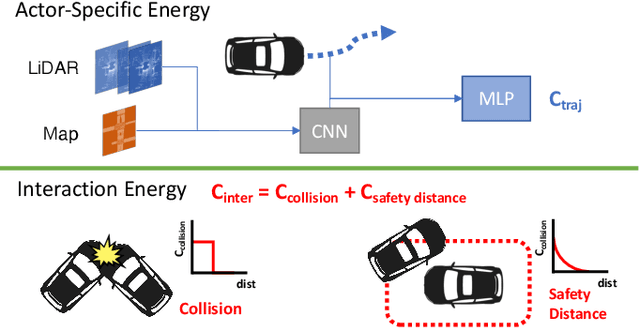

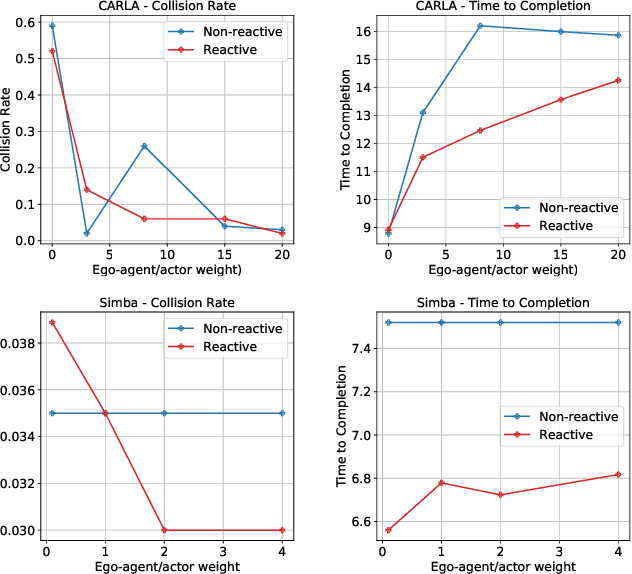
An intelligent agent operating in the real-world must balance achieving its goal with maintaining the safety and comfort of not only itself, but also other participants within the surrounding scene. This requires jointly reasoning about the behavior of other actors while deciding its own actions as these two processes are inherently intertwined - a vehicle will yield to us if we decide to proceed first at the intersection but will proceed first if we decide to yield. However, this is not captured in most self-driving pipelines, where planning follows prediction. In this paper we propose a novel data-driven, reactive planning objective which allows a self-driving vehicle to jointly reason about its own plans as well as how other actors will react to them. We formulate the problem as an energy-based deep structured model that is learned from observational data and encodes both the planning and prediction problems. Through simulations based on both real-world driving and synthetically generated dense traffic, we demonstrate that our reactive model outperforms a non-reactive variant in successfully completing highly complex maneuvers (lane merges/turns in traffic) faster, without trading off collision rate.
End-to-end Interpretable Neural Motion Planner
Jan 17, 2021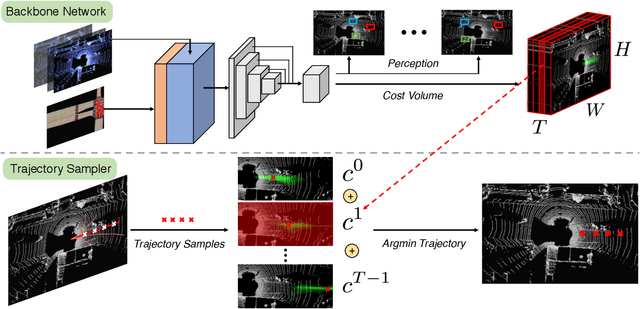
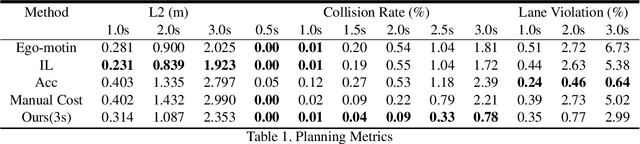
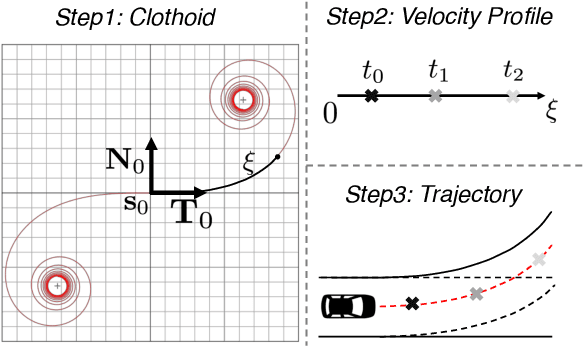

In this paper, we propose a neural motion planner (NMP) for learning to drive autonomously in complex urban scenarios that include traffic-light handling, yielding, and interactions with multiple road-users. Towards this goal, we design a holistic model that takes as input raw LIDAR data and a HD map and produces interpretable intermediate representations in the form of 3D detections and their future trajectories, as well as a cost volume defining the goodness of each position that the self-driving car can take within the planning horizon. We then sample a set of diverse physically possible trajectories and choose the one with the minimum learned cost. Importantly, our cost volume is able to naturally capture multi-modality. We demonstrate the effectiveness of our approach in real-world driving data captured in several cities in North America. Our experiments show that the learned cost volume can generate safer planning than all the baselines.
LaneRCNN: Distributed Representations for Graph-Centric Motion Forecasting
Jan 17, 2021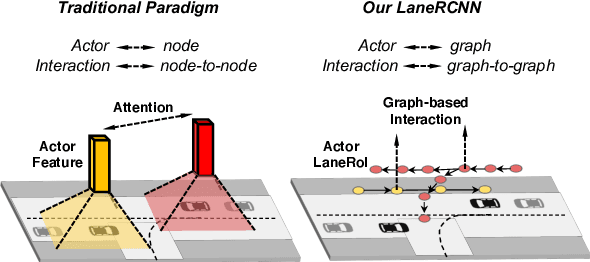
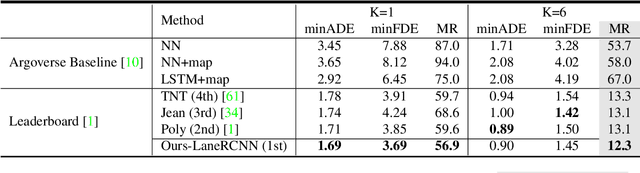
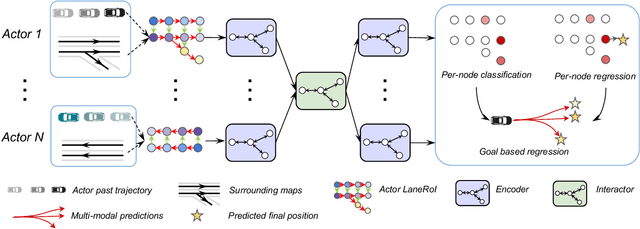
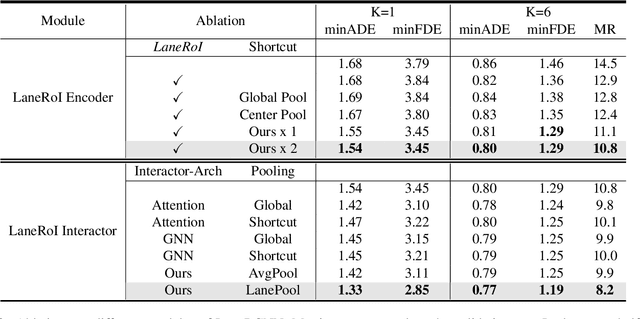
Forecasting the future behaviors of dynamic actors is an important task in many robotics applications such as self-driving. It is extremely challenging as actors have latent intentions and their trajectories are governed by complex interactions between the other actors, themselves, and the maps. In this paper, we propose LaneRCNN, a graph-centric motion forecasting model. Importantly, relying on a specially designed graph encoder, we learn a local lane graph representation per actor (LaneRoI) to encode its past motions and the local map topology. We further develop an interaction module which permits efficient message passing among local graph representations within a shared global lane graph. Moreover, we parameterize the output trajectories based on lane graphs, a more amenable prediction parameterization. Our LaneRCNN captures the actor-to-actor and the actor-to-map relations in a distributed and map-aware manner. We demonstrate the effectiveness of our approach on the large-scale Argoverse Motion Forecasting Benchmark. We achieve the 1st place on the leaderboard and significantly outperform previous best results.
Network Automatic Pruning: Start NAP and Take a Nap
Jan 17, 2021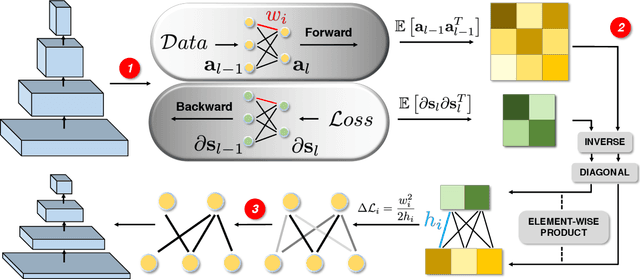
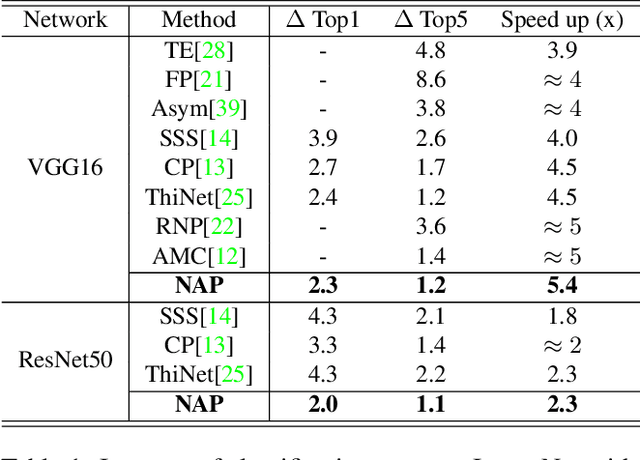
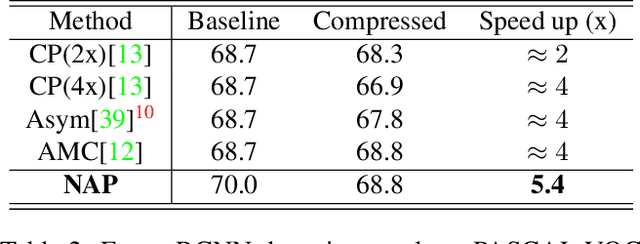
Network pruning can significantly reduce the computation and memory footprint of large neural networks. To achieve a good trade-off between model size and performance, popular pruning techniques usually rely on hand-crafted heuristics and require manually setting the compression ratio for each layer. This process is typically time-consuming and requires expert knowledge to achieve good results. In this paper, we propose NAP, a unified and automatic pruning framework for both fine-grained and structured pruning. It can find out unimportant components of a network and automatically decide appropriate compression ratios for different layers, based on a theoretically sound criterion. Towards this goal, NAP uses an efficient approximation of the Hessian for evaluating the importances of components, based on a Kronecker-factored Approximate Curvature method. Despite its simpleness to use, NAP outperforms previous pruning methods by large margins. For fine-grained pruning, NAP can compress AlexNet and VGG16 by 25x, and ResNet-50 by 6.7x without loss in accuracy on ImageNet. For structured pruning (e.g. channel pruning), it can reduce flops of VGG16 by 5.4x and ResNet-50 by 2.3x with only 1% accuracy drop. More importantly, this method is almost free from hyper-parameter tuning and requires no expert knowledge. You can start NAP and then take a nap!
Auto4D: Learning to Label 4D Objects from Sequential Point Clouds
Jan 17, 2021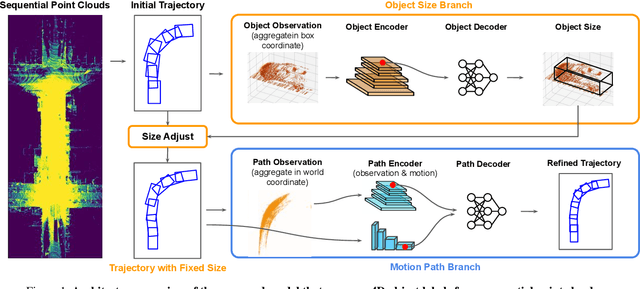
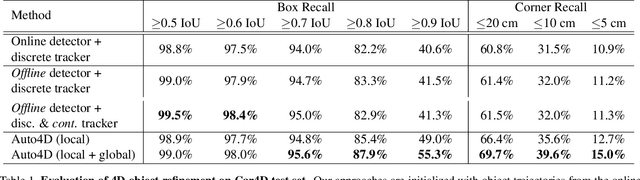
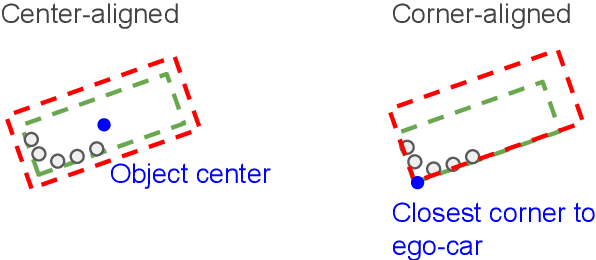
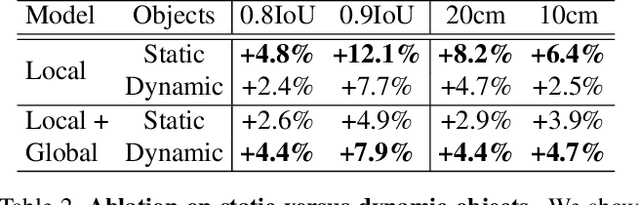
In the past few years we have seen great advances in 3D object detection thanks to deep learning methods. However, they typically rely on large amounts of high-quality labels to achieve good performance, which often require time-consuming and expensive work by human annotators. To address this we propose an automatic annotation pipeline that generates accurate object trajectories in 3D (ie, 4D labels) from LiDAR point clouds. Different from previous works that consider single frames at a time, our approach directly operates on sequential point clouds to combine richer object observations. The key idea is to decompose the 4D label into two parts: the 3D size of the object, and its motion path describing the evolution of the object's pose through time. More specifically, given a noisy but easy-to-get object track as initialization, our model first estimates the object size from temporally aggregated observations, and then refines its motion path by considering both frame-wise observations as well as temporal motion cues. We validate the proposed method on a large-scale driving dataset and show that our approach achieves significant improvements over the baselines. We also showcase the benefits of our approach under the annotator-in-the-loop setting.
Self-Supervised Representation Learning from Flow Equivariance
Jan 16, 2021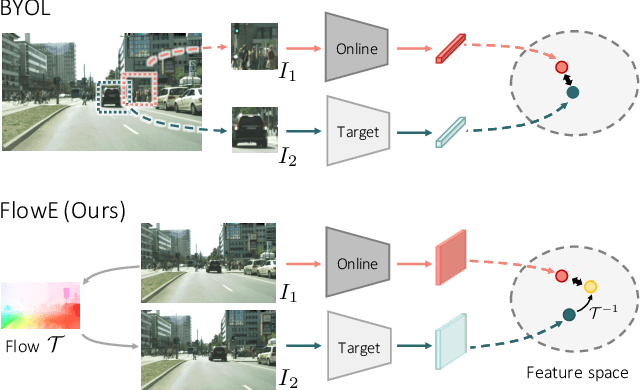
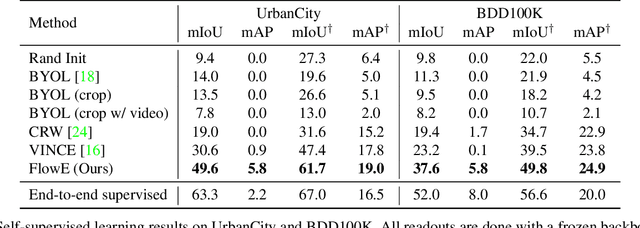
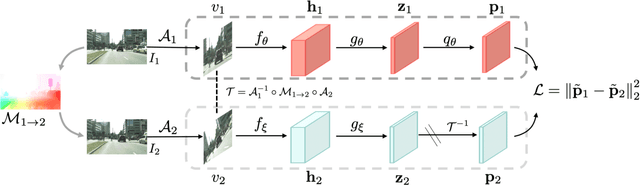
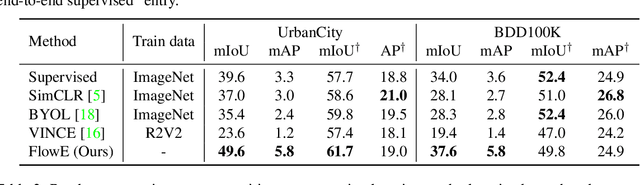
Self-supervised representation learning is able to learn semantically meaningful features; however, much of its recent success relies on multiple crops of an image with very few objects. Instead of learning view-invariant representation from simple images, humans learn representations in a complex world with changing scenes by observing object movement, deformation, pose variation, and ego motion. Motivated by this ability, we present a new self-supervised learning representation framework that can be directly deployed on a video stream of complex scenes with many moving objects. Our framework features a simple flow equivariance objective that encourages the network to predict the features of another frame by applying a flow transformation to the features of the current frame. Our representations, learned from high-resolution raw video, can be readily used for downstream tasks on static images. Readout experiments on challenging semantic segmentation, instance segmentation, and object detection benchmarks show that we are able to outperform representations obtained from previous state-of-the-art methods including SimCLR and BYOL.
Safety-Oriented Pedestrian Motion and Scene Occupancy Forecasting
Jan 07, 2021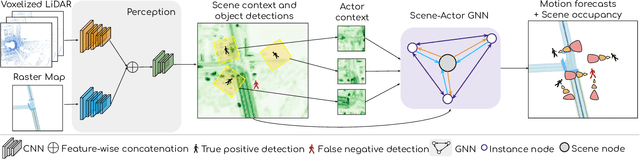
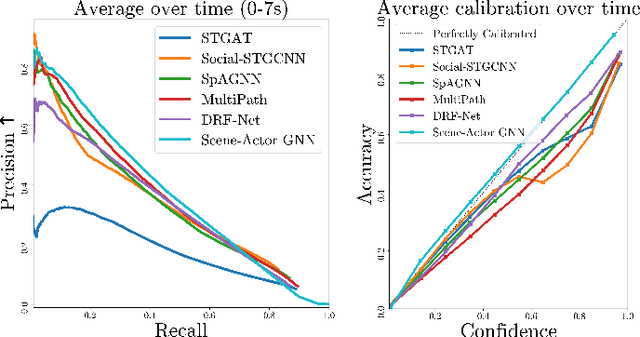
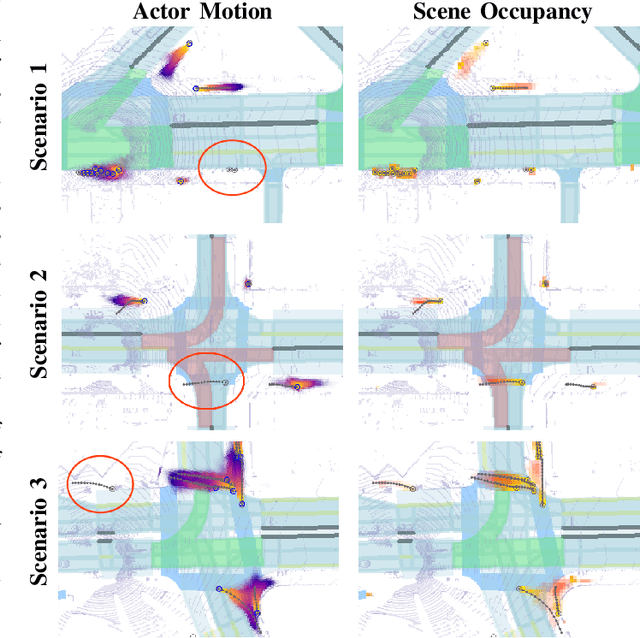
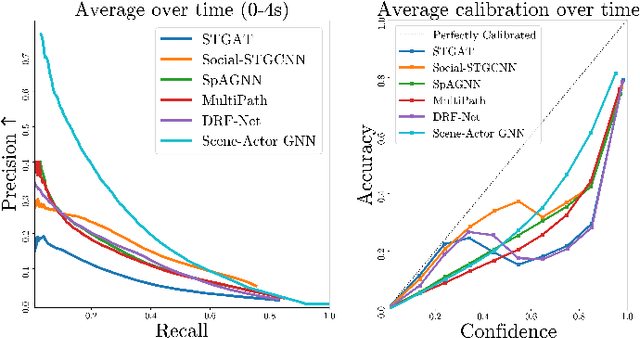
In this paper, we address the important problem in self-driving of forecasting multi-pedestrian motion and their shared scene occupancy map, critical for safe navigation. Our contributions are two-fold. First, we advocate for predicting both the individual motions as well as the scene occupancy map in order to effectively deal with missing detections caused by postprocessing, e.g., confidence thresholding and non-maximum suppression. Second, we propose a Scene-Actor Graph Neural Network (SA-GNN) which preserves the relative spatial information of pedestrians via 2D convolution, and captures the interactions among pedestrians within the same scene, including those that have not been detected, via message passing. On two large-scale real-world datasets, nuScenes and ATG4D, we showcase that our scene-occupancy predictions are more accurate and better calibrated than those from state-of-the-art motion forecasting methods, while also matching their performance in pedestrian motion forecasting metrics.