 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlash3D: Super-scaling Point Transformers through Joint Hardware-Geometry Locality
Dec 21, 2024Recent efforts recognize the power of scale in 3D learning (e.g. PTv3) and attention mechanisms (e.g. FlashAttention). However, current point cloud backbones fail to holistically unify geometric locality, attention mechanisms, and GPU architectures in one view. In this paper, we introduce Flash3D Transformer, which aligns geometric locality and GPU tiling through a principled locality mechanism based on Perfect Spatial Hashing (PSH). The common alignment with GPU tiling naturally fuses our PSH locality mechanism with FlashAttention at negligible extra cost. This mechanism affords flexible design choices throughout the backbone that result in superior downstream task results. Flash3D outperforms state-of-the-art PTv3 results on benchmark datasets, delivering a 2.25x speed increase and 2.4x memory efficiency boost. This efficiency enables scaling to wider attention scopes and larger models without additional overhead. Such scaling allows Flash3D to achieve even higher task accuracies than PTv3 under the same compute budget.
VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
Dec 19, 2024



Human drivers rely on commonsense reasoning to navigate diverse and dynamic real-world scenarios. Existing end-to-end (E2E) autonomous driving (AD) models are typically optimized to mimic driving patterns observed in data, without capturing the underlying reasoning processes. This limitation constrains their ability to handle challenging driving scenarios. To close this gap, we propose VLM-AD, a method that leverages vision-language models (VLMs) as teachers to enhance training by providing additional supervision that incorporates unstructured reasoning information and structured action labels. Such supervision enhances the model's ability to learn richer feature representations that capture the rationale behind driving patterns. Importantly, our method does not require a VLM during inference, making it practical for real-time deployment. When integrated with state-of-the-art methods, VLM-AD achieves significant improvements in planning accuracy and reduced collision rates on the nuScenes dataset.
Uncertainty-Guided Enhancement on Driving Perception System via Foundation Models
Oct 02, 2024



Multimodal foundation models offer promising advancements for enhancing driving perception systems, but their high computational and financial costs pose challenges. We develop a method that leverages foundation models to refine predictions from existing driving perception models -- such as enhancing object classification accuracy -- while minimizing the frequency of using these resource-intensive models. The method quantitatively characterizes uncertainties in the perception model's predictions and engages the foundation model only when these uncertainties exceed a pre-specified threshold. Specifically, it characterizes uncertainty by calibrating the perception model's confidence scores into theoretical lower bounds on the probability of correct predictions using conformal prediction. Then, it sends images to the foundation model and queries for refining the predictions only if the theoretical bound of the perception model's outcome is below the threshold. Additionally, we propose a temporal inference mechanism that enhances prediction accuracy by integrating historical predictions, leading to tighter theoretical bounds. The method demonstrates a 10 to 15 percent improvement in prediction accuracy and reduces the number of queries to the foundation model by 50 percent, based on quantitative evaluations from driving datasets.
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Aug 29, 2024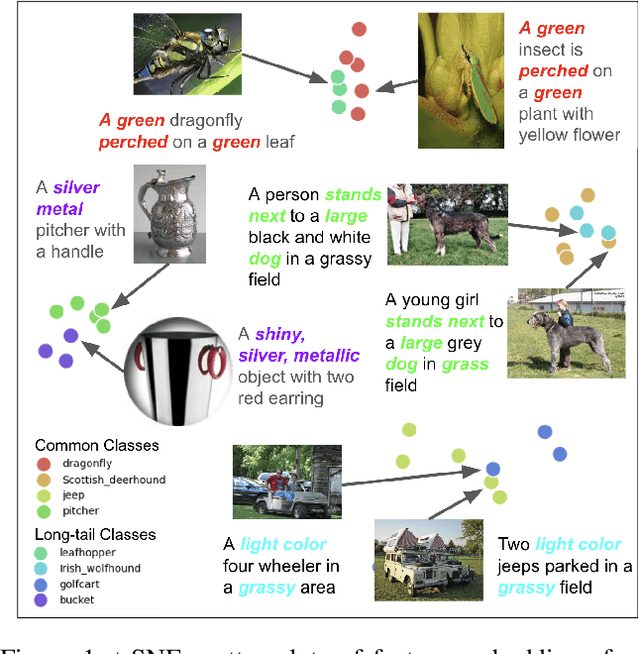
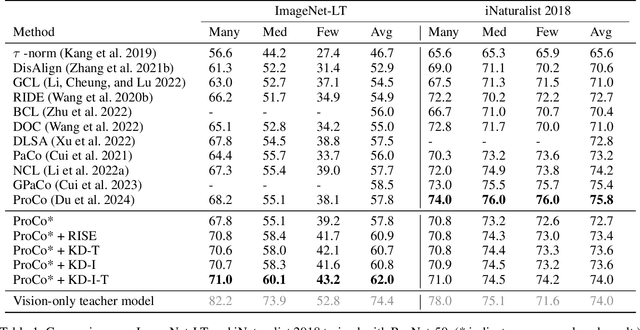
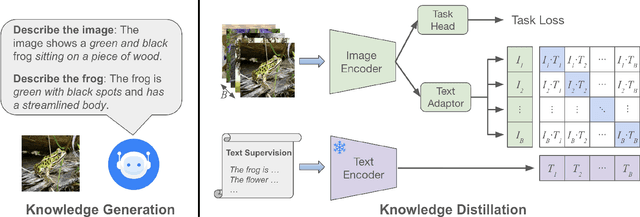
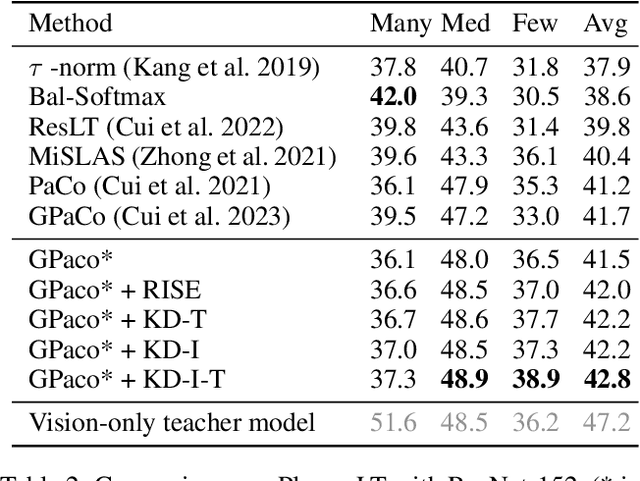
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
The Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Oct 04, 2023
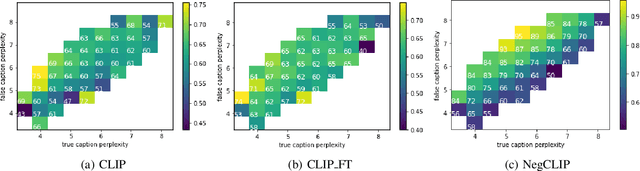


Compositionality is a common property in many modalities including natural languages and images, but the compositional generalization of multi-modal models is not well-understood. In this paper, we identify two sources of visual-linguistic compositionality: linguistic priors and the interplay between images and texts. We show that current attempts to improve compositional generalization rely on linguistic priors rather than on information in the image. We also propose a new metric for compositionality without such linguistic priors.
LiDAR-Based 3D Object Detection via Hybrid 2D Semantic Scene Generation
Apr 04, 2023Bird's-Eye View (BEV) features are popular intermediate scene representations shared by the 3D backbone and the detector head in LiDAR-based object detectors. However, little research has been done to investigate how to incorporate additional supervision on the BEV features to improve proposal generation in the detector head, while still balancing the number of powerful 3D layers and efficient 2D network operations. This paper proposes a novel scene representation that encodes both the semantics and geometry of the 3D environment in 2D, which serves as a dense supervision signal for better BEV feature learning. The key idea is to use auxiliary networks to predict a combination of explicit and implicit semantic probabilities by exploiting their complementary properties. Extensive experiments show that our simple yet effective design can be easily integrated into most state-of-the-art 3D object detectors and consistently improves upon baseline models.
HM3D-ABO: A Photo-realistic Dataset for Object-centric Multi-view 3D Reconstruction
Jun 24, 2022



Reconstructing 3D objects is an important computer vision task that has wide application in AR/VR. Deep learning algorithm developed for this task usually relies on an unrealistic synthetic dataset, such as ShapeNet and Things3D. On the other hand, existing real-captured object-centric datasets usually do not have enough annotation to enable supervised training or reliable evaluation. In this technical report, we present a photo-realistic object-centric dataset HM3D-ABO. It is constructed by composing realistic indoor scene and realistic object. For each configuration, we provide multi-view RGB observations, a water-tight mesh model for the object, ground truth depth map and object mask. The proposed dataset could also be useful for tasks such as camera pose estimation and novel-view synthesis. The dataset generation code is released at https://github.com/zhenpeiyang/HM3D-ABO.
FvOR: Robust Joint Shape and Pose Optimization for Few-view Object Reconstruction
May 16, 2022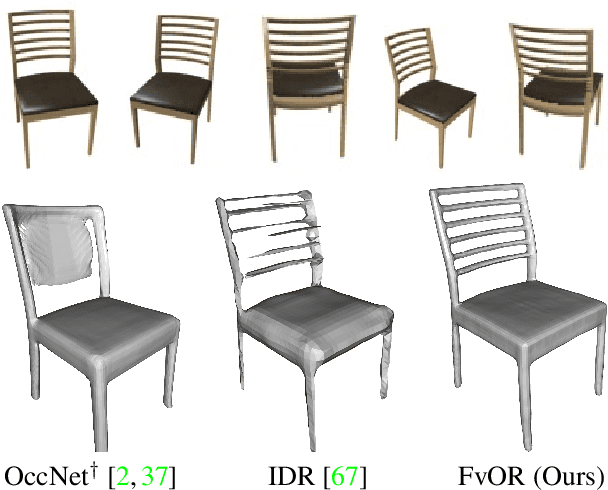

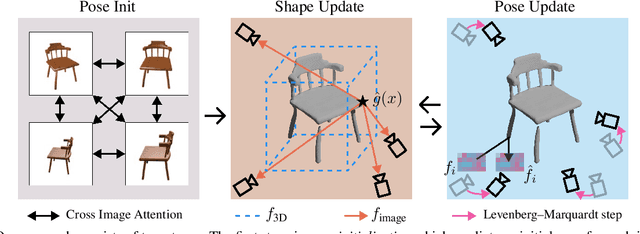

Reconstructing an accurate 3D object model from a few image observations remains a challenging problem in computer vision. State-of-the-art approaches typically assume accurate camera poses as input, which could be difficult to obtain in realistic settings. In this paper, we present FvOR, a learning-based object reconstruction method that predicts accurate 3D models given a few images with noisy input poses. The core of our approach is a fast and robust multi-view reconstruction algorithm to jointly refine 3D geometry and camera pose estimation using learnable neural network modules. We provide a thorough benchmark of state-of-the-art approaches for this problem on ShapeNet. Our approach achieves best-in-class results. It is also two orders of magnitude faster than the recent optimization-based approach IDR. Our code is released at \url{https://github.com/zhenpeiyang/FvOR/}
Scene Synthesis via Uncertainty-Driven Attribute Synchronization
Sep 01, 2021
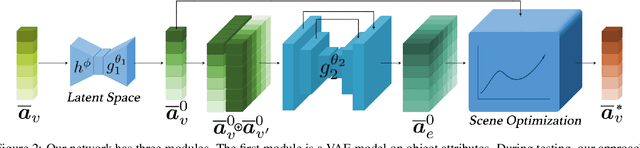


Developing deep neural networks to generate 3D scenes is a fundamental problem in neural synthesis with immediate applications in architectural CAD, computer graphics, as well as in generating virtual robot training environments. This task is challenging because 3D scenes exhibit diverse patterns, ranging from continuous ones, such as object sizes and the relative poses between pairs of shapes, to discrete patterns, such as occurrence and co-occurrence of objects with symmetrical relationships. This paper introduces a novel neural scene synthesis approach that can capture diverse feature patterns of 3D scenes. Our method combines the strength of both neural network-based and conventional scene synthesis approaches. We use the parametric prior distributions learned from training data, which provide uncertainties of object attributes and relative attributes, to regularize the outputs of feed-forward neural models. Moreover, instead of merely predicting a scene layout, our approach predicts an over-complete set of attributes. This methodology allows us to utilize the underlying consistency constraints among the predicted attributes to prune infeasible predictions. Experimental results show that our approach outperforms existing methods considerably. The generated 3D scenes interpolate the training data faithfully while preserving both continuous and discrete feature patterns.
ARAPReg: An As-Rigid-As Possible Regularization Loss for Learning Deformable Shape Generators
Aug 21, 2021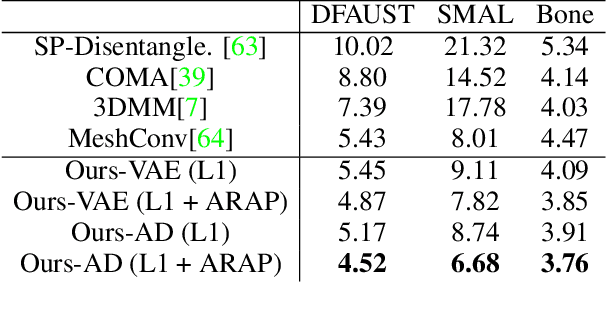
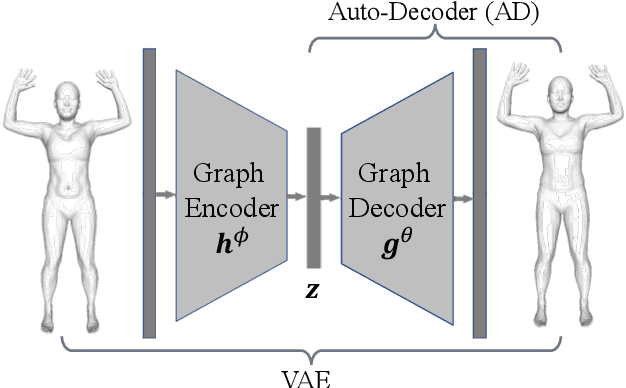

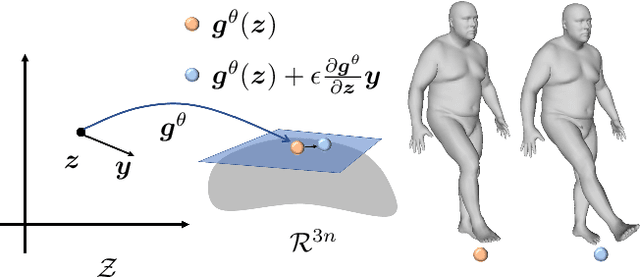
This paper introduces an unsupervised loss for training parametric deformation shape generators. The key idea is to enforce the preservation of local rigidity among the generated shapes. Our approach builds on an approximation of the as-rigid-as possible (or ARAP) deformation energy. We show how to develop the unsupervised loss via a spectral decomposition of the Hessian of the ARAP energy. Our loss nicely decouples pose and shape variations through a robust norm. The loss admits simple closed-form expressions. It is easy to train and can be plugged into any standard generation models, e.g., variational auto-encoder (VAE) and auto-decoder (AD). Experimental results show that our approach outperforms existing shape generation approaches considerably on public benchmark datasets of various shape categories such as human, animal and bone.