 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARAPDiffusion: ARAP Regularization for Diffusion-Based Deformable Shape Space Learning
Jun 05, 2026This paper introduces ARAPDiffusion, a latent diffusion model to learn the underlying continuous shape space of a deformation shape collection. The key innovation is in injecting the as-rigid-as-possible (ARAP) deformation model as regularization losses into latent diffusion (LD), releasing the requirement of having abundant 3D training data for learning generative models. In contrast to the standard LD, we show how the ARAP model can be used to improve both the encoder/decoder and the LD model. The training procedure alternates between using the synthetic distribution defined by the LD model to develop a regularization loss that enhances the shape encoder/decoder and using the shape decoder to develop a regularization loss to improve the LD model. We also show the benefit of the LD paradigm in combining a representation-free LD process and an implicit shape decoder that is applicable to unorganized point clouds. The experimental results of unconditional and conditional shape generation demonstrate the advantages of ARAPDiffusion over baseline approaches.
SuperFace: Preference-Aligned Facial Expression Estimation Beyond Pseudo Supervision
May 07, 2026Accurate facial estimation is crucial for realistic digital human animation, and ARKit blendshape coefficients offer an interpretable representation by mapping facial motions to semantic animation controls. However, learning high-quality ARKit coefficient prediction remains limited by the absence of reliable ground-truth supervision. Existing methods typically rely on capture software such as Live Link Face to provide pseudo labels, which may contain noisy activations, biased coefficient magnitudes, and missing or inaccurate facial actions. Consequently, models trained with supervised learning tend to reproduce imperfect pseudo labels rather than optimize for perceptual expression fidelity. In this paper, we propose SuperFace, a preference-driven framework that moves ARKit facial expression estimation from pseudo-label imitation toward human-aligned perceptual optimization. Instead of treating software-estimated coefficients as fixed ground truth, SuperFace uses them only as an initialization and further improves coefficient prediction through human preference feedback on rendered facial expressions. By aligning the model with perceptual judgments rather than numerical pseudo labels, SuperFace enables more visually faithful and expressive facial animation. Experiments show that SuperFace improves expression fidelity over Live Link Face supervision, demonstrating the effectiveness of preference-driven optimization for semantic facial action prediction.
Exploring the Role of Synthetic Data Augmentation in Controllable Human-Centric Video Generation
Apr 23, 2026Controllable human video generation aims to produce realistic videos of humans with explicitly guided motions and appearances,serving as a foundation for digital humans, animation, and embodied AI.However, the scarcity of largescale, diverse, and privacy safe human video datasets poses a major bottleneck, especially for rare identities and complex actions.Synthetic data provides a scalable and controllable alternative,yet its actual contribution to generative modeling remains underexplored due to the persistent Sim2Real gap.In this work,we systematically investigate the impact of synthetic data on controllable human video generation. We propose a diffusion-based framework that enables fine-grained control over appearance and motion while providing a unfied testbed to analyze how synthetic data interacts with real world data during training. Through extensive experiments, we reveal the complementary roles of synthetic and real data and demonstrate possible methods for efficiently selecting synthetic samples to enhance motion realism,temporal consistency,and identity preservation.Our study offers the first comprehensive exploration of synthetic data's role in human-centric video synthesis and provides practical insights for building data-efficient and generalizable generative models.
Interact3D: Compositional 3D Generation of Interactive Objects
Mar 17, 2026Recent breakthroughs in 3D generation have enabled the synthesis of high-fidelity individual assets. However, generating 3D compositional objects from single images--particularly under occlusions--remains challenging. Existing methods often degrade geometric details in hidden regions and fail to preserve the underlying object-object spatial relationships (OOR). We present a novel framework Interact3D designed to generate physically plausible interacting 3D compositional objects. Our approach first leverages advanced generative priors to curate high-quality individual assets with a unified 3D guidance scene. To physically compose these assets, we then introduce a robust two-stage composition pipeline. Based on the 3D guidance scene, the primary object is anchored through precise global-to-local geometric alignment (registration), while subsequent geometries are integrated using a differentiable Signed Distance Field (SDF)-based optimization that explicitly penalizes geometry intersections. To reduce challenging collisions, we further deploy a closed-loop, agentic refinement strategy. A Vision-Language Model (VLM) autonomously analyzes multi-view renderings of the composed scene, formulates targeted corrective prompts, and guides an image editing module to iteratively self-correct the generation pipeline. Extensive experiments demonstrate that Interact3D successfully produces promising collsion-aware compositions with improved geometric fidelity and consistent spatial relationships.
SemanticFace: Semantic Facial Action Estimation via Semantic Distillation in Interpretable Space
Mar 16, 2026Facial action estimation from a single image is often formulated as predicting or fitting parameters in compact expression spaces, which lack explicit semantic interpretability. However, many practical applications, such as avatar control and human-computer interaction, require interpretable facial actions that correspond to meaningful muscle movements. In this work, we propose \textbf{SemanticFace}, a framework for facial action estimation in the interpretable ARKit blendshape space that reformulates coefficient prediction as structured semantic reasoning. SemanticFace adopts a two-stage semantic distillation paradigm: it first derives structured semantic supervision from ground-truth ARKit coefficients and then distills this knowledge into a multimodal large language model to predict interpretable facial action coefficients from images. Extensive experiments demonstrate that language-aligned semantic supervision improves both coefficient accuracy and perceptual consistency, while enabling strong cross-identity generalization and robustness to large domain shifts, including cartoon faces.
3DGS$^2$-TR: Scalable Second-Order Trust-Region Method for 3D Gaussian Splatting
Jan 30, 2026We propose 3DGS$^2$-TR,a second-order optimizer for accelerating the scene training problem in 3D Gaussian Splatting (3DGS). Unlike existing second-order approaches that rely on explicit or dense curvature representations, such as 3DGS-LM (Höllein et al., 2025) or 3DGS2 (Lan et al., 2025), our method approximates curvature using only the diagonal of the Hessian matrix, efficiently via Hutchinson's method. Our approach is fully matrix-free and has the same complexity as ADAM (Kingma, 2024), $O(n)$ in both computation and memory costs. To ensure stable optimization in the presence of strong nonlinearity in the 3DGS rasterization process, we introduce a parameter-wise trust-region technique based on the squared Hellinger distance, regularizing updates to Gaussian parameters. Under identical parameter initialization and without densification, 3DGS$^2$-TR is able to achieve better reconstruction quality on standard datasets, using 50% fewer training iterations compared to ADAM, while incurring less than 1GB of peak GPU memory overhead (17% more than ADAM and 85% less than 3DGS-LM), enabling scalability to very large scenes and potentially to distributed training settings.
ReWeaver: Towards Simulation-Ready and Topology-Accurate Garment Reconstruction
Jan 23, 2026High-quality 3D garment reconstruction plays a crucial role in mitigating the sim-to-real gap in applications such as digital avatars, virtual try-on and robotic manipulation. However, existing garment reconstruction methods typically rely on unstructured representations, such as 3D Gaussian Splats, struggling to provide accurate reconstructions of garment topology and sewing structures. As a result, the reconstructed outputs are often unsuitable for high-fidelity physical simulation. We propose ReWeaver, a novel framework for topology-accurate 3D garment and sewing pattern reconstruction from sparse multi-view RGB images. Given as few as four input views, ReWeaver predicts seams and panels as well as their connectivities in both the 2D UV space and the 3D space. The predicted seams and panels align precisely with the multi-view images, yielding structured 2D--3D garment representations suitable for 3D perception, high-fidelity physical simulation, and robotic manipulation. To enable effective training, we construct a large-scale dataset GCD-TS, comprising multi-view RGB images, 3D garment geometries, textured human body meshes and annotated sewing patterns. The dataset contains over 100,000 synthetic samples covering a wide range of complex geometries and topologies. Extensive experiments show that ReWeaver consistently outperforms existing methods in terms of topology accuracy, geometry alignment and seam-panel consistency.
KeyframeFace: From Text to Expressive Facial Keyframes
Dec 12, 2025Generating dynamic 3D facial animation from natural language requires understanding both temporally structured semantics and fine-grained expression changes. Existing datasets and methods mainly focus on speech-driven animation or unstructured expression sequences and therefore lack the semantic grounding and temporal structures needed for expressive human performance generation. In this work, we introduce KeyframeFace, a large-scale multimodal dataset designed for text-to-animation research through keyframe-level supervision. KeyframeFace provides 2,100 expressive scripts paired with monocular videos, per-frame ARKit coefficients, contextual backgrounds, complex emotions, manually defined keyframes, and multi-perspective annotations based on ARKit coefficients and images via Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Beyond the dataset, we propose the first text-to-animation framework that explicitly leverages LLM priors for interpretable facial motion synthesis. This design aligns the semantic understanding capabilities of LLMs with the interpretable structure of ARKit's coefficients, enabling high-fidelity expressive animation. KeyframeFace and our LLM-based framework together establish a new foundation for interpretable, keyframe-guided, and context-aware text-to-animation. Code and data are available at https://github.com/wjc12345123/KeyframeFace.
VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation
Feb 12, 2025Recent image-to-video generation methods have demonstrated success in enabling control over one or two visual elements, such as camera trajectory or object motion. However, these methods are unable to offer control over multiple visual elements due to limitations in data and network efficacy. In this paper, we introduce VidCRAFT3, a novel framework for precise image-to-video generation that enables control over camera motion, object motion, and lighting direction simultaneously. To better decouple control over each visual element, we propose the Spatial Triple-Attention Transformer, which integrates lighting direction, text, and image in a symmetric way. Since most real-world video datasets lack lighting annotations, we construct a high-quality synthetic video dataset, the VideoLightingDirection (VLD) dataset. This dataset includes lighting direction annotations and objects of diverse appearance, enabling VidCRAFT3 to effectively handle strong light transmission and reflection effects. Additionally, we propose a three-stage training strategy that eliminates the need for training data annotated with multiple visual elements (camera motion, object motion, and lighting direction) simultaneously. Extensive experiments on benchmark datasets demonstrate the efficacy of VidCRAFT3 in producing high-quality video content, surpassing existing state-of-the-art methods in terms of control granularity and visual coherence. All code and data will be publicly available.
Instance-aware 3D Semantic Segmentation powered by Shape Generators and Classifiers
Nov 21, 2023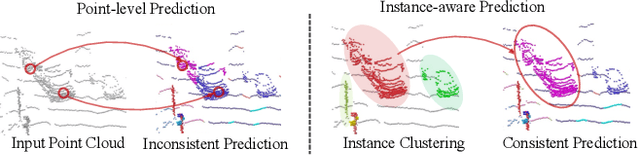

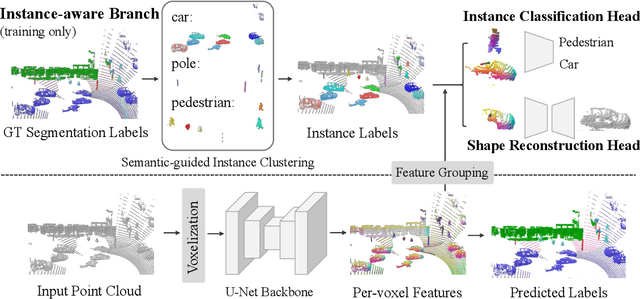

Existing 3D semantic segmentation methods rely on point-wise or voxel-wise feature descriptors to output segmentation predictions. However, these descriptors are often supervised at point or voxel level, leading to segmentation models that can behave poorly at instance-level. In this paper, we proposed a novel instance-aware approach for 3D semantic segmentation. Our method combines several geometry processing tasks supervised at instance-level to promote the consistency of the learned feature representation. Specifically, our methods use shape generators and shape classifiers to perform shape reconstruction and classification tasks for each shape instance. This enforces the feature representation to faithfully encode both structural and local shape information, with an awareness of shape instances. In the experiments, our method significantly outperform existing approaches in 3D semantic segmentation on several public benchmarks, such as Waymo Open Dataset, SemanticKITTI and ScanNetV2.