 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind-of-Director: Multi-modal Agent-Driven Film Previsualization via Collaborative Decision-Making
Mar 16, 2026We present Mind-of-Director, a multi-modal agent-driven framework for film previz that models the collaborative decision-making process of a film production team. Given a creative idea, Mind-of-Director orchestrates multiple specialized agents to produce previz sequences within the game engine. The framework consists of four cooperative modules: Script Development, where agents draft and refine the screenplay iteratively; Virtual Scene Design, which transforms text into semantically aligned 3D environments; Character Behaviour Control, which determines character blocking and motion; and Camera Planning, which optimizes framing, movement, and composition for cinematic camera effects. A real-time visual editing system built in the game engine further enables interactive inspection and synchronized timeline adjustment across scenes, behaviours, and cameras. Extensive experiments and human evaluations show that Mind-of-Director generates high-quality, semantically grounded previz sequences in approximately 25 minutes per idea, demonstrating the effectiveness of agent collaboration for both automated prototyping and human-in-the-loop filmmaking.
VerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control
Jan 08, 2026Video world models aim to simulate dynamic, real-world environments, yet existing methods struggle to provide unified and precise control over camera and multi-object motion, as videos inherently operate dynamics in the projected 2D image plane. To bridge this gap, we introduce VerseCrafter, a 4D-aware video world model that enables explicit and coherent control over both camera and object dynamics within a unified 4D geometric world state. Our approach is centered on a novel 4D Geometric Control representation, which encodes the world state through a static background point cloud and per-object 3D Gaussian trajectories. This representation captures not only an object's path but also its probabilistic 3D occupancy over time, offering a flexible, category-agnostic alternative to rigid bounding boxes or parametric models. These 4D controls are rendered into conditioning signals for a pretrained video diffusion model, enabling the generation of high-fidelity, view-consistent videos that precisely adhere to the specified dynamics. Unfortunately, another major challenge lies in the scarcity of large-scale training data with explicit 4D annotations. We address this by developing an automatic data engine that extracts the required 4D controls from in-the-wild videos, allowing us to train our model on a massive and diverse dataset.
A Neural Representation Framework with LLM-Driven Spatial Reasoning for Open-Vocabulary 3D Visual Grounding
Jul 09, 2025



Open-vocabulary 3D visual grounding aims to localize target objects based on free-form language queries, which is crucial for embodied AI applications such as autonomous navigation, robotics, and augmented reality. Learning 3D language fields through neural representations enables accurate understanding of 3D scenes from limited viewpoints and facilitates the localization of target objects in complex environments. However, existing language field methods struggle to accurately localize instances using spatial relations in language queries, such as ``the book on the chair.'' This limitation mainly arises from inadequate reasoning about spatial relations in both language queries and 3D scenes. In this work, we propose SpatialReasoner, a novel neural representation-based framework with large language model (LLM)-driven spatial reasoning that constructs a visual properties-enhanced hierarchical feature field for open-vocabulary 3D visual grounding. To enable spatial reasoning in language queries, SpatialReasoner fine-tunes an LLM to capture spatial relations and explicitly infer instructions for the target, anchor, and spatial relation. To enable spatial reasoning in 3D scenes, SpatialReasoner incorporates visual properties (opacity and color) to construct a hierarchical feature field. This field represents language and instance features using distilled CLIP features and masks extracted via the Segment Anything Model (SAM). The field is then queried using the inferred instructions in a hierarchical manner to localize the target 3D instance based on the spatial relation in the language query. Extensive experiments show that our framework can be seamlessly integrated into different neural representations, outperforming baseline models in 3D visual grounding while empowering their spatial reasoning capability.
TriVLA: A Triple-System-Based Unified Vision-Language-Action Model for General Robot Control
Jul 03, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods design a specific architecture like dual-system to leverage large-scale pretrained knowledge, they tend to capture static information, often neglecting the dynamic aspects vital for embodied tasks. To this end, we propose TriVLA, a unified Vision-Language-Action model with a triple-system architecture for general robot control. The vision-language module (System 2) interprets the environment through vision and language instructions. The dynamics perception module (System 3) inherently produces visual representations that encompass both current static information and predicted future dynamics, thereby providing valuable guidance for policy learning. TriVLA utilizes pre-trained VLM model and fine-tunes pre-trained video foundation model on robot datasets along with internet human manipulation data. The subsequent policy learning module (System 1) generates fluid motor actions in real time. Experimental evaluation demonstrates that TriVLA operates at approximately 36 Hz and surpasses state-of-the-art imitation learning baselines on standard simulation benchmarks as well as challenging real-world manipulation tasks.
TriVLA: A Unified Triple-System-Based Unified Vision-Language-Action Model for General Robot Control
Jul 02, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods design a specific architecture like dual-system to leverage large-scale pretrained knowledge, they tend to capture static information, often neglecting the dynamic aspects vital for embodied tasks. To this end, we propose TriVLA, a unified Vision-Language-Action model with a triple-system architecture for general robot control. The vision-language module (System 2) interprets the environment through vision and language instructions. The dynamics perception module (System 3) inherently produces visual representations that encompass both current static information and predicted future dynamics, thereby providing valuable guidance for policy learning. TriVLA utilizes pre-trained VLM model and fine-tunes pre-trained video foundation model on robot datasets along with internet human manipulation data. The subsequent policy learning module (System 1) generates fluid motor actions in real time. Experimental evaluation demonstrates that TriVLA operates at approximately 36 Hz and surpasses state-of-the-art imitation learning baselines on standard simulation benchmarks as well as challenging real-world manipulation tasks.
ReasonGrounder: LVLM-Guided Hierarchical Feature Splatting for Open-Vocabulary 3D Visual Grounding and Reasoning
Mar 30, 2025Open-vocabulary 3D visual grounding and reasoning aim to localize objects in a scene based on implicit language descriptions, even when they are occluded. This ability is crucial for tasks such as vision-language navigation and autonomous robotics. However, current methods struggle because they rely heavily on fine-tuning with 3D annotations and mask proposals, which limits their ability to handle diverse semantics and common knowledge required for effective reasoning. In this work, we propose ReasonGrounder, an LVLM-guided framework that uses hierarchical 3D feature Gaussian fields for adaptive grouping based on physical scale, enabling open-vocabulary 3D grounding and reasoning. ReasonGrounder interprets implicit instructions using large vision-language models (LVLM) and localizes occluded objects through 3D Gaussian splatting. By incorporating 2D segmentation masks from the SAM and multi-view CLIP embeddings, ReasonGrounder selects Gaussian groups based on object scale, enabling accurate localization through both explicit and implicit language understanding, even in novel, occluded views. We also contribute ReasoningGD, a new dataset containing over 10K scenes and 2 million annotations for evaluating open-vocabulary 3D grounding and amodal perception under occlusion. Experiments show that ReasonGrounder significantly improves 3D grounding accuracy in real-world scenarios.
VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation
Feb 12, 2025Recent image-to-video generation methods have demonstrated success in enabling control over one or two visual elements, such as camera trajectory or object motion. However, these methods are unable to offer control over multiple visual elements due to limitations in data and network efficacy. In this paper, we introduce VidCRAFT3, a novel framework for precise image-to-video generation that enables control over camera motion, object motion, and lighting direction simultaneously. To better decouple control over each visual element, we propose the Spatial Triple-Attention Transformer, which integrates lighting direction, text, and image in a symmetric way. Since most real-world video datasets lack lighting annotations, we construct a high-quality synthetic video dataset, the VideoLightingDirection (VLD) dataset. This dataset includes lighting direction annotations and objects of diverse appearance, enabling VidCRAFT3 to effectively handle strong light transmission and reflection effects. Additionally, we propose a three-stage training strategy that eliminates the need for training data annotated with multiple visual elements (camera motion, object motion, and lighting direction) simultaneously. Extensive experiments on benchmark datasets demonstrate the efficacy of VidCRAFT3 in producing high-quality video content, surpassing existing state-of-the-art methods in terms of control granularity and visual coherence. All code and data will be publicly available.
TemporalStory: Enhancing Consistency in Story Visualization using Spatial-Temporal Attention
Jul 13, 2024
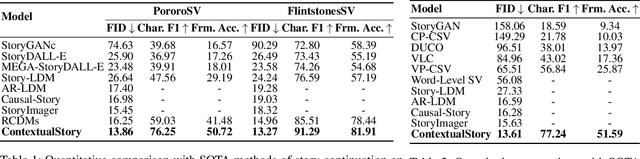
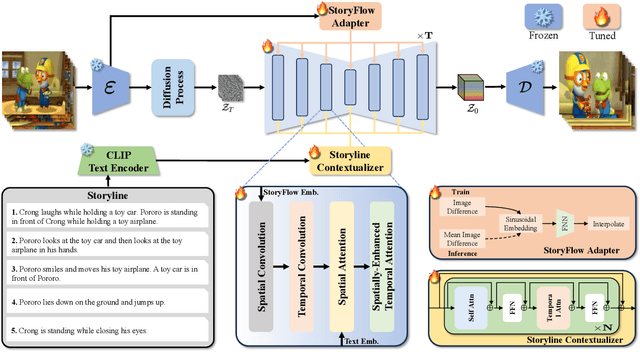
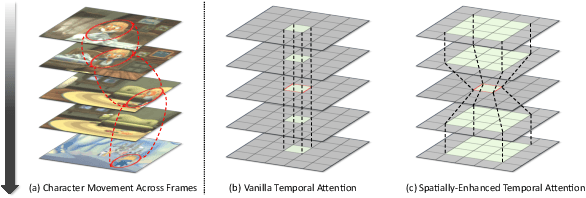
Story visualization presents a challenging task in text-to-image generation, requiring not only the rendering of visual details from text prompt but also ensuring consistency across images. Recently, most approaches address inconsistency problem using an auto-regressive manner conditioned on previous image-sentence pairs. However, they overlook the fact that story context is dispersed across all sentences. The auto-regressive approach fails to encode information from susequent image-sentence pairs, thus unable to capture the entirety of the story context. To address this, we introduce TemporalStory, leveraging Spatial-Temporal attention to model complex spatial and temporal dependencies in images, enabling the generation of coherent images based on a given storyline. In order to better understand the storyline context, we introduce a text adapter capable of integrating information from other sentences into the embedding of the current sentence. Additionally, to utilize scene changes between story images as guidance for the model, we propose the StoryFlow Adapter to measure the degree of change between images. Through extensive experiments on two popular benchmarks, PororoSV and FlintstonesSV, our TemporalStory outperforms the previous state-of-the-art in both story visualization and story continuation tasks.
Intelligent Director: An Automatic Framework for Dynamic Visual Composition using ChatGPT
Feb 24, 2024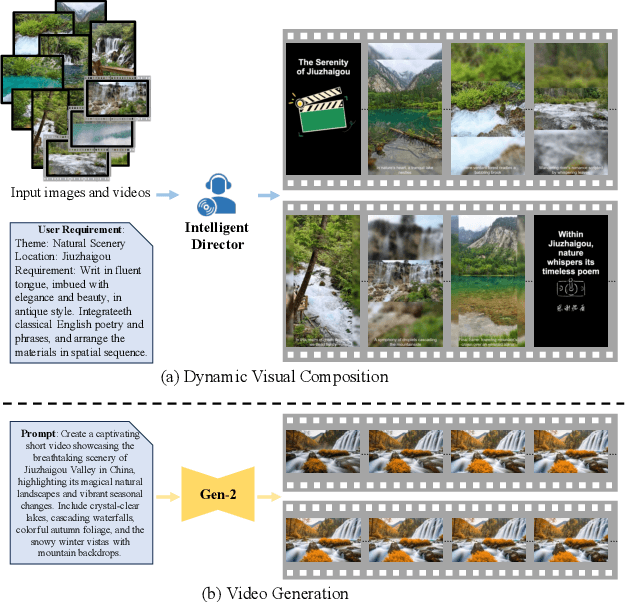

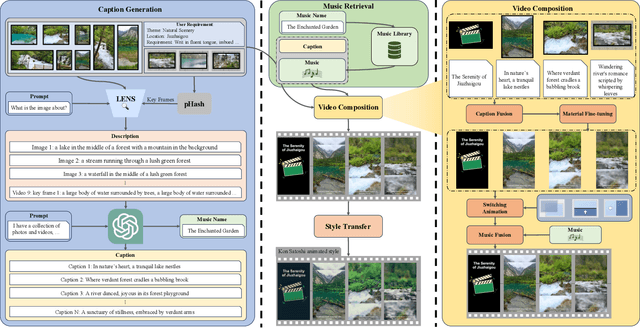
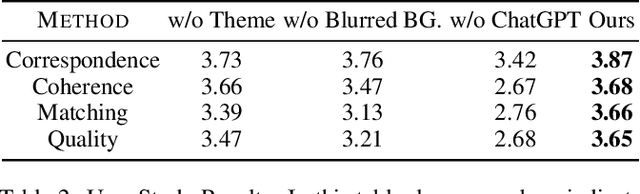
With the rise of short video platforms represented by TikTok, the trend of users expressing their creativity through photos and videos has increased dramatically. However, ordinary users lack the professional skills to produce high-quality videos using professional creation software. To meet the demand for intelligent and user-friendly video creation tools, we propose the Dynamic Visual Composition (DVC) task, an interesting and challenging task that aims to automatically integrate various media elements based on user requirements and create storytelling videos. We propose an Intelligent Director framework, utilizing LENS to generate descriptions for images and video frames and combining ChatGPT to generate coherent captions while recommending appropriate music names. Then, the best-matched music is obtained through music retrieval. Then, materials such as captions, images, videos, and music are integrated to seamlessly synthesize the video. Finally, we apply AnimeGANv2 for style transfer. We construct UCF101-DVC and Personal Album datasets and verified the effectiveness of our framework in solving DVC through qualitative and quantitative comparisons, along with user studies, demonstrating its substantial potential.
Visual Representation Learning with Transformer: A Sequence-to-Sequence Perspective
Jul 19, 2022Visual representation learning is the key of solving various vision problems. Relying on the seminal grid structure priors, convolutional neural networks (CNNs) have been the de facto standard architectures of most deep vision models. For instance, classical semantic segmentation methods often adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated (i.e., atrous) convolutions or inserting attention modules. However, the FCN-based architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating visual representation learning generally as a sequence-to-sequence prediction task. Specifically, we deploy a pure Transformer to encode an image as a sequence of patches, without local convolution and resolution reduction. With the global context modeled in every layer of the Transformer, stronger visual representation can be learned for better tackling vision tasks. In particular, our segmentation model, termed as SEgmentation TRansformer (SETR), excels on ADE20K (50.28% mIoU, the first position in the test leaderboard on the day of submission), Pascal Context (55.83% mIoU) and reaches competitive results on Cityscapes. Further, we formulate a family of Hierarchical Local-Global (HLG) Transformers characterized by local attention within windows and global-attention across windows in a hierarchical and pyramidal architecture. Extensive experiments show that our method achieves appealing performance on a variety of visual recognition tasks (e.g., image classification, object detection and instance segmentation and semantic segmentation).