 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Structural and Unstructured Data: A Topic-based Finite Mixture Model for Insurance Claim Prediction
Oct 07, 2024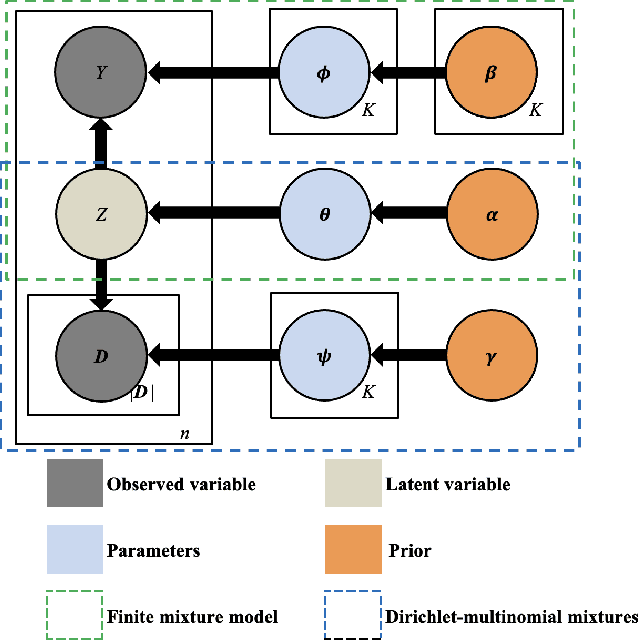

Modeling insurance claim amounts and classifying claims into different risk levels are critical yet challenging tasks. Traditional predictive models for insurance claims often overlook the valuable information embedded in claim descriptions. This paper introduces a novel approach by developing a joint mixture model that integrates both claim descriptions and claim amounts. Our method establishes a probabilistic link between textual descriptions and loss amounts, enhancing the accuracy of claims clustering and prediction. In our proposed model, the latent topic/component indicator serves as a proxy for both the thematic content of the claim description and the component of loss distributions. Specifically, conditioned on the topic/component indicator, the claim description follows a multinomial distribution, while the claim amount follows a component loss distribution. We propose two methods for model calibration: an EM algorithm for maximum a posteriori estimates, and an MH-within-Gibbs sampler algorithm for the posterior distribution. The empirical study demonstrates that the proposed methods work effectively, providing interpretable claims clustering and prediction.
Learning to Simulate: Generative Metamodeling via Quantile Regression
Nov 29, 2023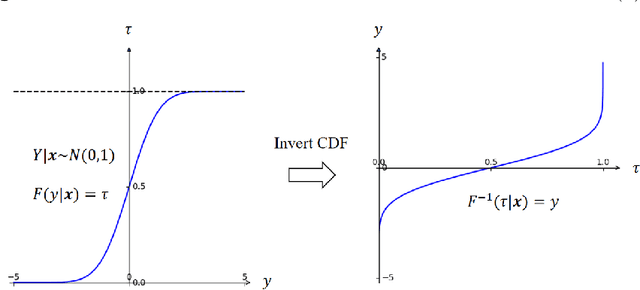
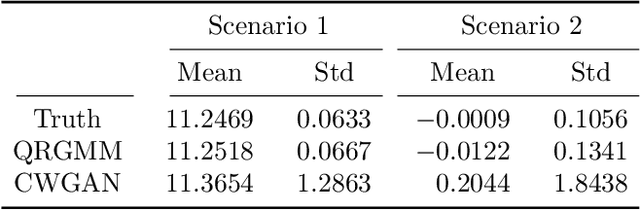
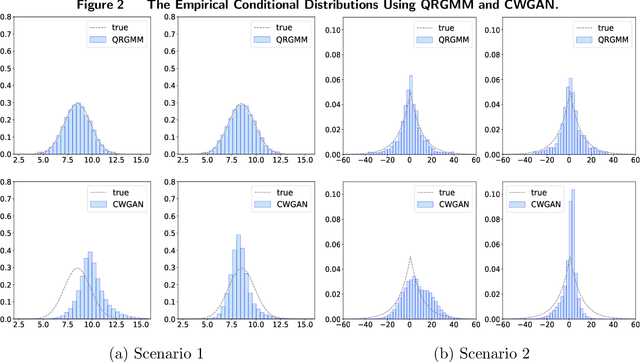
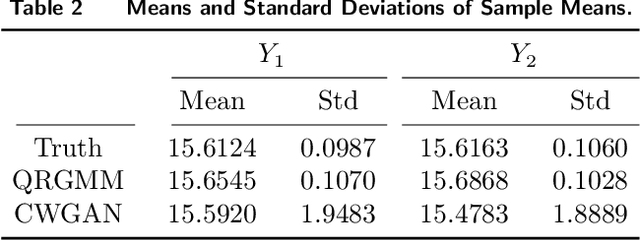
Stochastic simulation models, while effective in capturing the dynamics of complex systems, are often too slow to run for real-time decision-making. Metamodeling techniques are widely used to learn the relationship between a summary statistic of the outputs (e.g., the mean or quantile) and the inputs of the simulator, so that it can be used in real time. However, this methodology requires the knowledge of an appropriate summary statistic in advance, making it inflexible for many practical situations. In this paper, we propose a new metamodeling concept, called generative metamodeling, which aims to construct a "fast simulator of the simulator". This technique can generate random outputs substantially faster than the original simulation model, while retaining an approximately equal conditional distribution given the same inputs. Once constructed, a generative metamodel can instantaneously generate a large amount of random outputs as soon as the inputs are specified, thereby facilitating the immediate computation of any summary statistic for real-time decision-making. Furthermore, we propose a new algorithm -- quantile-regression-based generative metamodeling (QRGMM) -- and study its convergence and rate of convergence. Extensive numerical experiments are conducted to investigate the empirical performance of QRGMM, compare it with other state-of-the-art generative algorithms, and demonstrate its usefulness in practical real-time decision-making.
Clustering by the Probability Distributions from Extreme Value Theory
Feb 20, 2022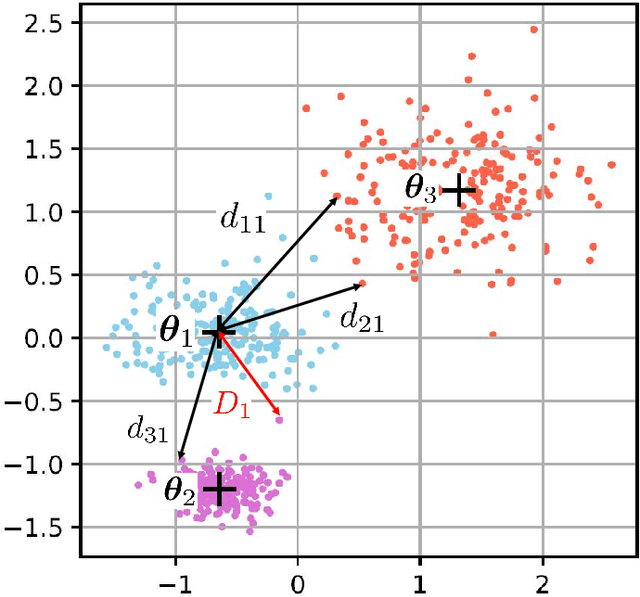
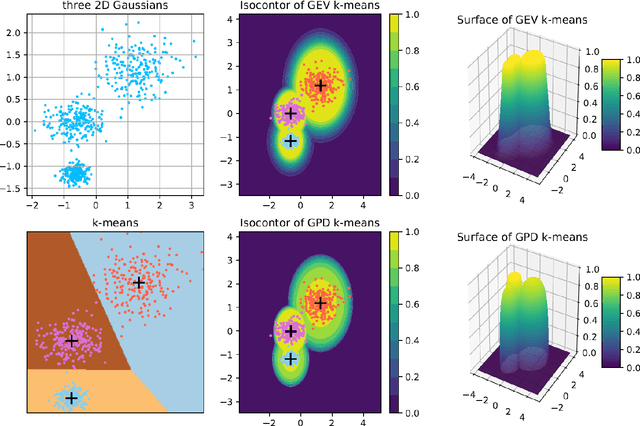
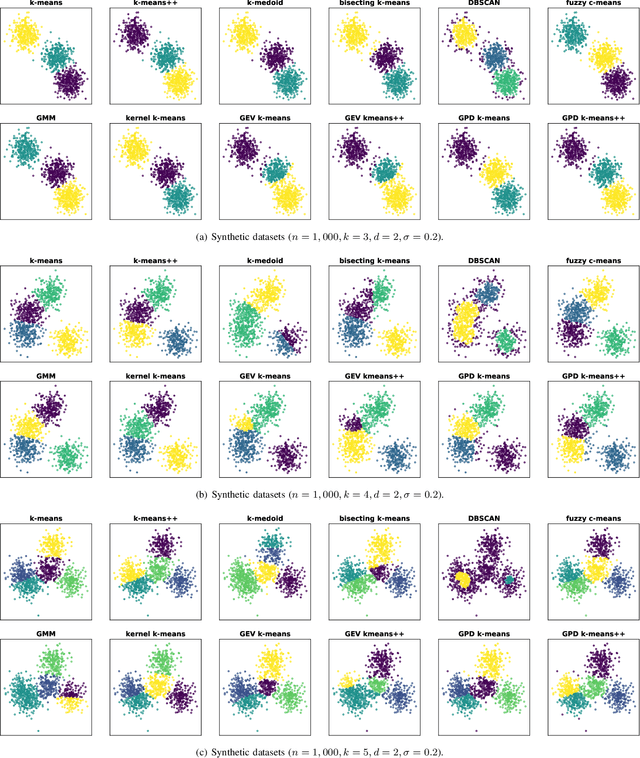
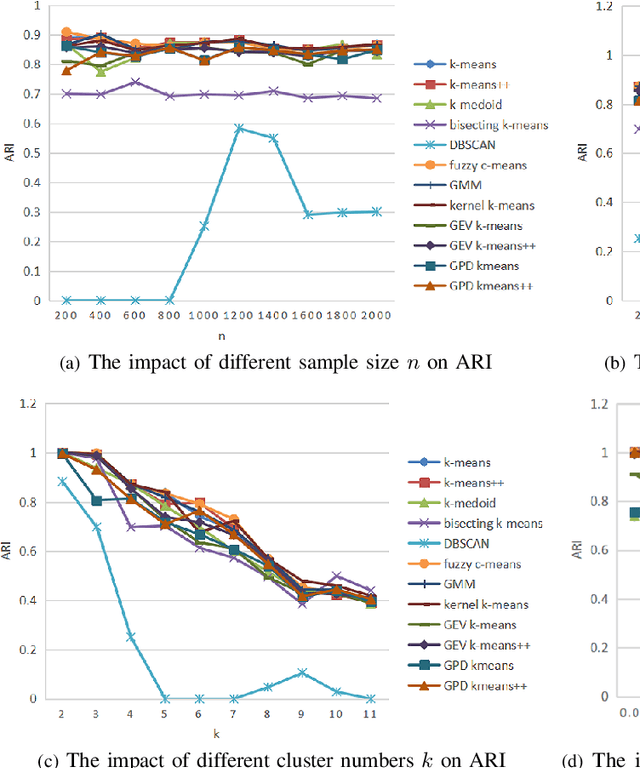
Clustering is an essential task to unsupervised learning. It tries to automatically separate instances into coherent subsets. As one of the most well-known clustering algorithms, k-means assigns sample points at the boundary to a unique cluster, while it does not utilize the information of sample distribution or density. Comparably, it would potentially be more beneficial to consider the probability of each sample in a possible cluster. To this end, this paper generalizes k-means to model the distribution of clusters. Our novel clustering algorithm thus models the distributions of distances to centroids over a threshold by Generalized Pareto Distribution (GPD) in Extreme Value Theory (EVT). Notably, we propose the concept of centroid margin distance, use GPD to establish a probability model for each cluster, and perform a clustering algorithm based on the covering probability function derived from GPD. Such a GPD k-means thus enables the clustering algorithm from the probabilistic perspective. Correspondingly, we also introduce a naive baseline, dubbed as Generalized Extreme Value (GEV) k-means. GEV fits the distribution of the block maxima. In contrast, the GPD fits the distribution of distance to the centroid exceeding a sufficiently large threshold, leading to a more stable performance of GPD k-means. Notably, GEV k-means can also estimate cluster structure and thus perform reasonably well over classical k-means. Thus, extensive experiments on synthetic datasets and real datasets demonstrate that GPD k-means outperforms competitors. The github codes are released in https://github.com/sixiaozheng/EVT-K-means.
Incrementally Zero-Shot Detection by an Extreme Value Analyzer
Mar 29, 2021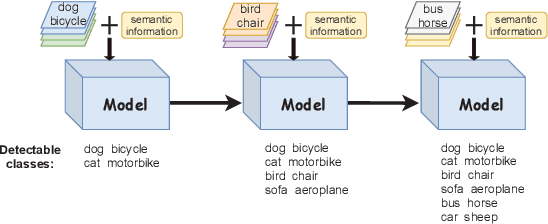
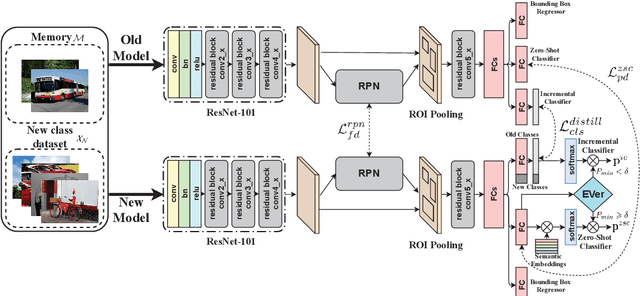
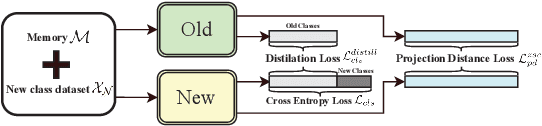
Human beings not only have the ability to recognize novel unseen classes, but also can incrementally incorporate the new classes to existing knowledge preserved. However, zero-shot learning models assume that all seen classes should be known beforehand, while incremental learning models cannot recognize unseen classes. This paper introduces a novel and challenging task of Incrementally Zero-Shot Detection (IZSD), a practical strategy for both zero-shot learning and class-incremental learning in real-world object detection. An innovative end-to-end model -- IZSD-EVer was proposed to tackle this task that requires incrementally detecting new classes and detecting the classes that have never been seen. Specifically, we propose a novel extreme value analyzer to detect objects from old seen, new seen, and unseen classes, simultaneously. Additionally and technically, we propose two innovative losses, i.e., background-foreground mean squared error loss alleviating the extreme imbalance of the background and foreground of images, and projection distance loss aligning the visual space and semantic spaces of old seen classes. Experiments demonstrate the efficacy of our model in detecting objects from both the seen and unseen classes, outperforming the alternative models on Pascal VOC and MSCOCO datasets.