 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Structural and Unstructured Data: A Topic-based Finite Mixture Model for Insurance Claim Prediction
Oct 07, 2024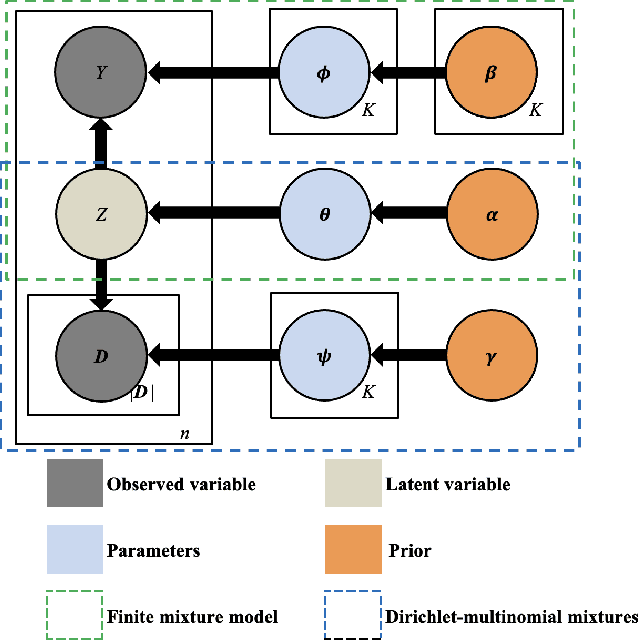

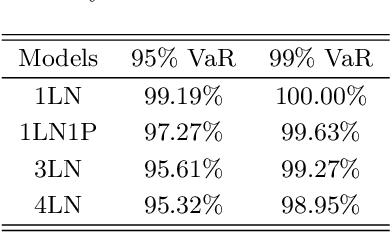
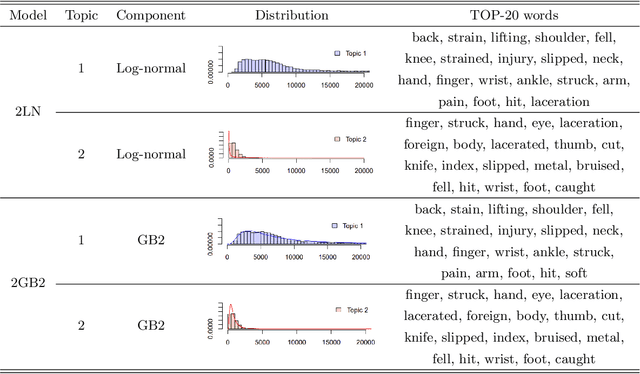
Modeling insurance claim amounts and classifying claims into different risk levels are critical yet challenging tasks. Traditional predictive models for insurance claims often overlook the valuable information embedded in claim descriptions. This paper introduces a novel approach by developing a joint mixture model that integrates both claim descriptions and claim amounts. Our method establishes a probabilistic link between textual descriptions and loss amounts, enhancing the accuracy of claims clustering and prediction. In our proposed model, the latent topic/component indicator serves as a proxy for both the thematic content of the claim description and the component of loss distributions. Specifically, conditioned on the topic/component indicator, the claim description follows a multinomial distribution, while the claim amount follows a component loss distribution. We propose two methods for model calibration: an EM algorithm for maximum a posteriori estimates, and an MH-within-Gibbs sampler algorithm for the posterior distribution. The empirical study demonstrates that the proposed methods work effectively, providing interpretable claims clustering and prediction.