 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunYuan_tvr for Text-Video Retrivial
Paper and Code
Apr 14, 2022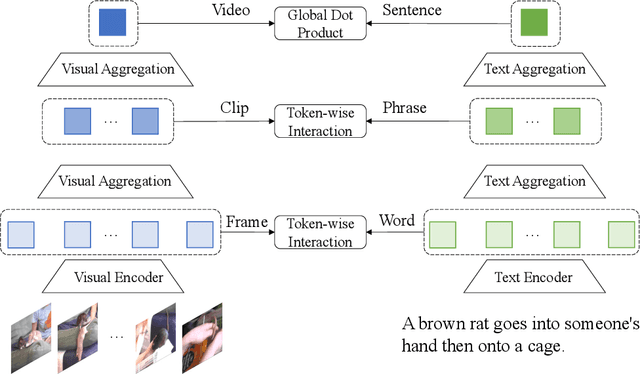
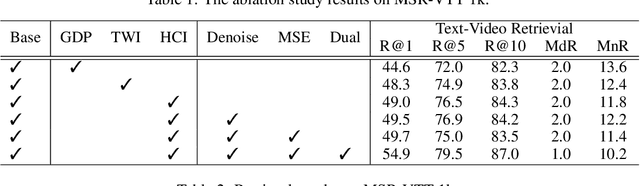
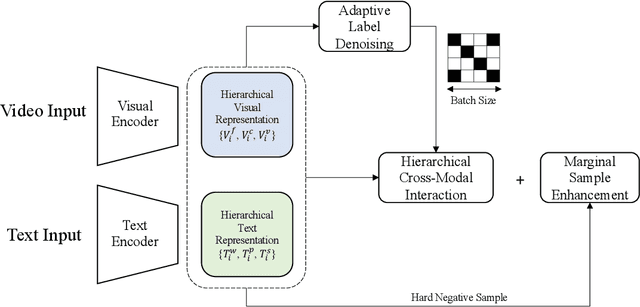
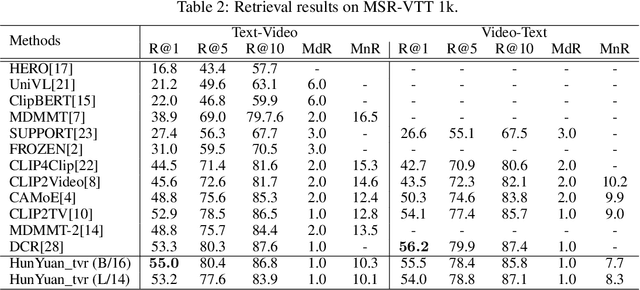
Text-Video Retrieval plays an important role in multi-modal understanding and has attracted increasing attention in recent years. Most existing methods focus on constructing contrastive pairs between whole videos and complete caption sentences, while ignoring fine-grained cross-modal relationships, e.g., short clips and phrases or single frame and word. In this paper, we propose a novel method, named HunYuan\_tvr, to explore hierarchical cross-modal interactions by simultaneously exploring video-sentence, clip-phrase, and frame-word relationships. Considering intrinsic semantic relations between frames, HunYuan\_tvr first performs self-attention to explore frame-wise correlations and adaptively clusters correlated frames into clip-level representations. Then, the clip-wise correlation is explored to aggregate clip representations into a compact one to describe the video globally. In this way, we can construct hierarchical video representations for frame-clip-video granularities, and also explore word-wise correlations to form word-phrase-sentence embeddings for the text modality. Finally, hierarchical contrastive learning is designed to explore cross-modal relationships,~\emph{i.e.,} frame-word, clip-phrase, and video-sentence, which enables HunYuan\_tvr to achieve a comprehensive multi-modal understanding. Further boosted by adaptive label denosing and marginal sample enhancement, HunYuan\_tvr obtains new state-of-the-art results on various benchmarks, e.g., Rank@1 of 55.0%, 57.8%, 29.7%, 52.1%, and 57.3% on MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet respectively.