 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Tokenizer Barrier: On-Policy Distillation across Model Families
Jun 08, 2026On-Policy Distillation (OPD) has become a core technique in the post-training of Large Language Models (LLMs) for transferring knowledge from domain experts to student models. However, existing OPD distillation methods require teacher and student models to share the same tokenizer, restricting the applicability of OPD within the model series. Current mainstream practice typically employs Supervised Fine-Tuning (SFT) on teacher-generated responses for cross-tokenizer distillation, which fails to capture the rich knowledge embedded in the teacher's probability distribution. In this work, we enable the standard on-policy distillation method to operate across model families, ensuring that high-fidelity token-level signals can propagate across different tokenizers with a precise token-mapping algorithm. Extensive experiments show that cross-tokenizer OPD is significantly more compute-efficient than baselines on various benchmarks. Our results unlock a broader range of teacher-student pairs for OPD, opening up new avenues for adapting and enhancing interactions between LLMs.
Training Agents with Weakly Supervised Feedback from Large Language Models
Nov 29, 2024



Large Language Models (LLMs) offer a promising basis for creating agents that can tackle complex tasks through iterative environmental interaction. Existing methods either require these agents to mimic expert-provided trajectories or rely on definitive environmental feedback for reinforcement learning which limits their application to specific scenarios like gaming or code generation. This paper introduces a novel training method for LLM-based agents using weakly supervised signals from a critic LLM, bypassing the need for expert trajectories or definitive feedback. Our agents are trained in iterative manner, where they initially generate trajectories through environmental interaction. Subsequently, a critic LLM selects a subset of good trajectories, which are then used to update the agents, enabling them to generate improved trajectories in the next iteration. Extensive tests on the API-bank dataset show consistent improvement in our agents' capabilities and comparable performance to GPT-4, despite using open-source models with much fewer parameters.
Embedding Self-Correction as an Inherent Ability in Large Language Models for Enhanced Mathematical Reasoning
Oct 14, 2024



Accurate mathematical reasoning with Large Language Models (LLMs) is crucial in revolutionizing domains that heavily rely on such reasoning. However, LLMs often encounter difficulties in certain aspects of mathematical reasoning, leading to flawed reasoning and erroneous results. To mitigate these issues, we introduce a novel mechanism, the Chain of Self-Correction (CoSC), specifically designed to embed self-correction as an inherent ability in LLMs, enabling them to validate and rectify their own results. The CoSC mechanism operates through a sequence of self-correction stages. In each stage, the LLMs generate a program to address a given problem, execute this program using program-based tools to obtain an output, subsequently verify this output. Based on the verification, the LLMs either proceed to the next correction stage or finalize the answer. This iterative self-correction process allows the LLMs to refine their reasoning steps and improve the accuracy of their mathematical reasoning. To enable the CoSC mechanism at a low cost, we employ a two-phase finetuning approach. In the first phase, the LLMs are trained with a relatively small volume of seeding data generated from GPT-4, establishing an initial CoSC capability. In the second phase, the CoSC capability is further enhanced by training with a larger volume of self-generated data using the trained model in the first phase, without relying on the paid GPT-4. Our comprehensive experiments demonstrate that CoSC significantly improves performance on traditional mathematical datasets among existing open-source LLMs. Notably, our CoSC-Code-34B model achieved a 53.5% score on MATH, the most challenging mathematical reasoning dataset in the public domain, surpassing the performance of well-established models such as ChatGPT, GPT-4, and even multi-modal LLMs like GPT-4V, Gemini-1.0 Pro, and Gemini-1.0 Ultra.
Pre-trained Large Language Models for Financial Sentiment Analysis
Jan 10, 2024Financial sentiment analysis refers to classifying financial text contents into sentiment categories (e.g. positive, negative, and neutral). In this paper, we focus on the classification of financial news title, which is a challenging task due to a lack of large amount of training samples. To overcome this difficulty, we propose to adapt the pretrained large language models (LLMs) [1, 2, 3] to solve this problem. The LLMs, which are trained from huge amount of text corpora,have an advantage in text understanding and can be effectively adapted to domain-specific task while requiring very few amount of training samples. In particular, we adapt the open-source Llama2-7B model (2023) with the supervised fine-tuning (SFT) technique [4]. Experimental evaluation shows that even with the 7B model (which is relatively small for LLMs), our approach significantly outperforms the previous state-of-the-art algorithms.
Hardly Perceptible Trojan Attack against Neural Networks with Bit Flips
Jul 27, 2022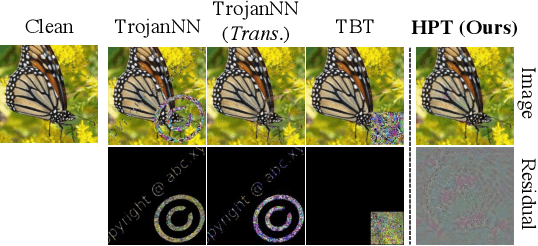
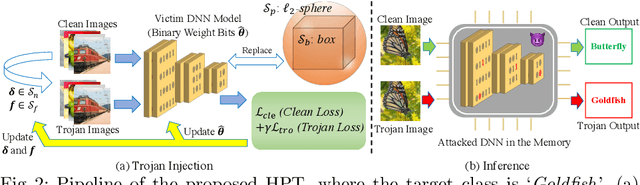


The security of deep neural networks (DNNs) has attracted increasing attention due to their widespread use in various applications. Recently, the deployed DNNs have been demonstrated to be vulnerable to Trojan attacks, which manipulate model parameters with bit flips to inject a hidden behavior and activate it by a specific trigger pattern. However, all existing Trojan attacks adopt noticeable patch-based triggers (e.g., a square pattern), making them perceptible to humans and easy to be spotted by machines. In this paper, we present a novel attack, namely hardly perceptible Trojan attack (HPT). HPT crafts hardly perceptible Trojan images by utilizing the additive noise and per pixel flow field to tweak the pixel values and positions of the original images, respectively. To achieve superior attack performance, we propose to jointly optimize bit flips, additive noise, and flow field. Since the weight bits of the DNNs are binary, this problem is very hard to be solved. We handle the binary constraint with equivalent replacement and provide an effective optimization algorithm. Extensive experiments on CIFAR-10, SVHN, and ImageNet datasets show that the proposed HPT can generate hardly perceptible Trojan images, while achieving comparable or better attack performance compared to the state-of-the-art methods. The code is available at: https://github.com/jiawangbai/HPT.
HunYuan_tvr for Text-Video Retrivial
Apr 14, 2022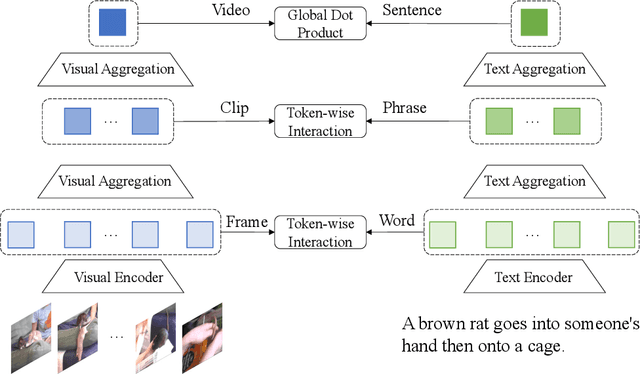
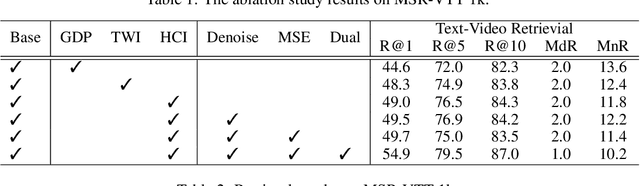
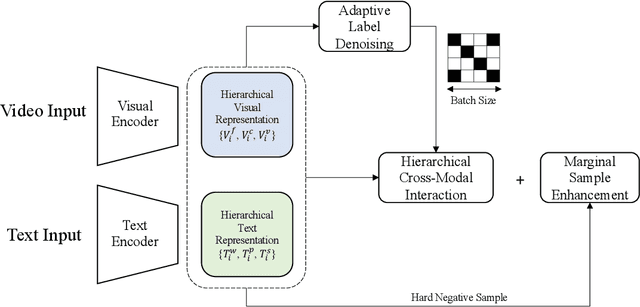
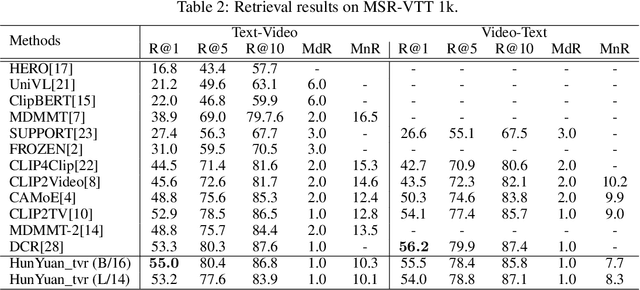
Text-Video Retrieval plays an important role in multi-modal understanding and has attracted increasing attention in recent years. Most existing methods focus on constructing contrastive pairs between whole videos and complete caption sentences, while ignoring fine-grained cross-modal relationships, e.g., short clips and phrases or single frame and word. In this paper, we propose a novel method, named HunYuan\_tvr, to explore hierarchical cross-modal interactions by simultaneously exploring video-sentence, clip-phrase, and frame-word relationships. Considering intrinsic semantic relations between frames, HunYuan\_tvr first performs self-attention to explore frame-wise correlations and adaptively clusters correlated frames into clip-level representations. Then, the clip-wise correlation is explored to aggregate clip representations into a compact one to describe the video globally. In this way, we can construct hierarchical video representations for frame-clip-video granularities, and also explore word-wise correlations to form word-phrase-sentence embeddings for the text modality. Finally, hierarchical contrastive learning is designed to explore cross-modal relationships,~\emph{i.e.,} frame-word, clip-phrase, and video-sentence, which enables HunYuan\_tvr to achieve a comprehensive multi-modal understanding. Further boosted by adaptive label denosing and marginal sample enhancement, HunYuan\_tvr obtains new state-of-the-art results on various benchmarks, e.g., Rank@1 of 55.0%, 57.8%, 29.7%, 52.1%, and 57.3% on MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet respectively.
Triangle Attack: A Query-efficient Decision-based Adversarial Attack
Dec 13, 2021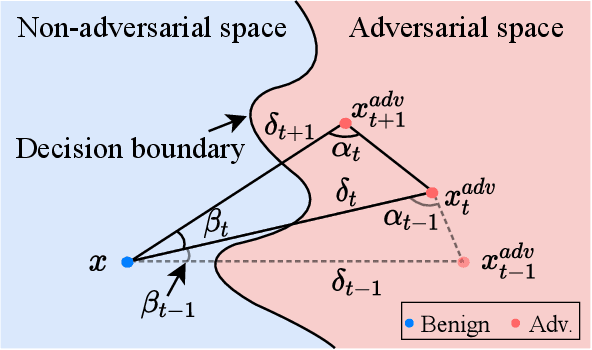
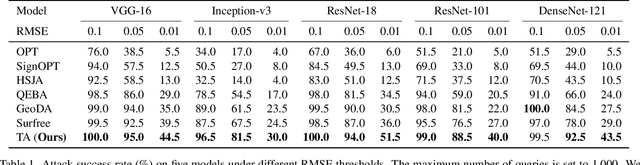
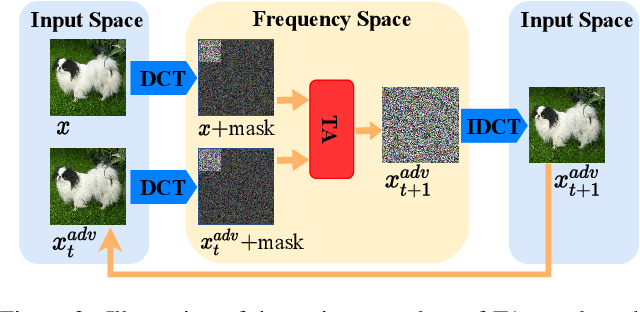
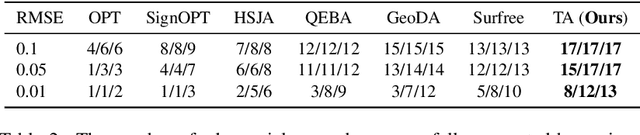
Decision-based attack poses a severe threat to real-world applications since it regards the target model as a black box and only accesses the hard prediction label. Great efforts have been made recently to decrease the number of queries; however, existing decision-based attacks still require thousands of queries in order to generate good quality adversarial examples. In this work, we find that a benign sample, the current and the next adversarial examples could naturally construct a triangle in a subspace for any iterative attacks. Based on the law of sines, we propose a novel Triangle Attack (TA) to optimize the perturbation by utilizing the geometric information that the longer side is always opposite the larger angle in any triangle. However, directly applying such information on the input image is ineffective because it cannot thoroughly explore the neighborhood of the input sample in the high dimensional space. To address this issue, TA optimizes the perturbation in the low frequency space for effective dimensionality reduction owing to the generality of such geometric property. Extensive evaluations on the ImageNet dataset demonstrate that TA achieves a much higher attack success rate within 1,000 queries and needs a much less number of queries to achieve the same attack success rate under various perturbation budgets than existing decision-based attacks. With such high efficiency, we further demonstrate the applicability of TA on real-world API, i.e., Tencent Cloud API.
End2End Occluded Face Recognition by Masking Corrupted Features
Aug 21, 2021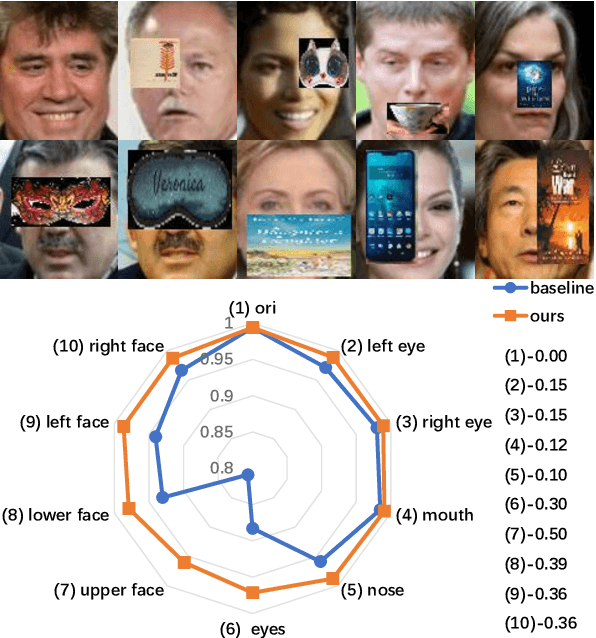

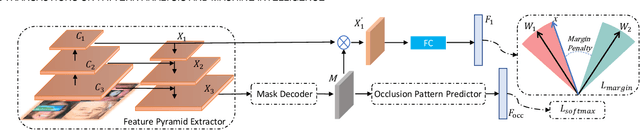

With the recent advancement of deep convolutional neural networks, significant progress has been made in general face recognition. However, the state-of-the-art general face recognition models do not generalize well to occluded face images, which are exactly the common cases in real-world scenarios. The potential reasons are the absences of large-scale occluded face data for training and specific designs for tackling corrupted features brought by occlusions. This paper presents a novel face recognition method that is robust to occlusions based on a single end-to-end deep neural network. Our approach, named FROM (Face Recognition with Occlusion Masks), learns to discover the corrupted features from the deep convolutional neural networks, and clean them by the dynamically learned masks. In addition, we construct massive occluded face images to train FROM effectively and efficiently. FROM is simple yet powerful compared to the existing methods that either rely on external detectors to discover the occlusions or employ shallow models which are less discriminative. Experimental results on the LFW, Megaface challenge 1, RMF2, AR dataset and other simulated occluded/masked datasets confirm that FROM dramatically improves the accuracy under occlusions, and generalizes well on general face recognition.
SynFace: Face Recognition with Synthetic Data
Aug 18, 2021

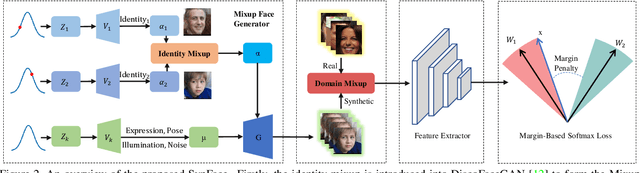
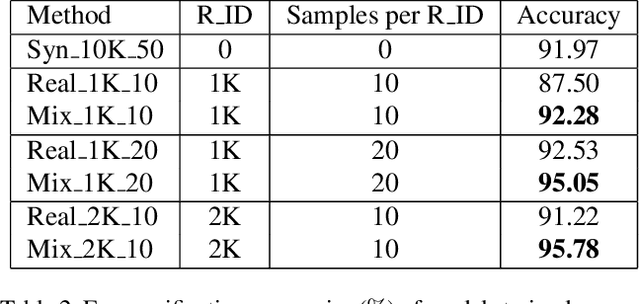
With the recent success of deep neural networks, remarkable progress has been achieved on face recognition. However, collecting large-scale real-world training data for face recognition has turned out to be challenging, especially due to the label noise and privacy issues. Meanwhile, existing face recognition datasets are usually collected from web images, lacking detailed annotations on attributes (e.g., pose and expression), so the influences of different attributes on face recognition have been poorly investigated. In this paper, we address the above-mentioned issues in face recognition using synthetic face images, i.e., SynFace. Specifically, we first explore the performance gap between recent state-of-the-art face recognition models trained with synthetic and real face images. We then analyze the underlying causes behind the performance gap, e.g., the poor intra-class variations and the domain gap between synthetic and real face images. Inspired by this, we devise the SynFace with identity mixup (IM) and domain mixup (DM) to mitigate the above performance gap, demonstrating the great potentials of synthetic data for face recognition. Furthermore, with the controllable face synthesis model, we can easily manage different factors of synthetic face generation, including pose, expression, illumination, the number of identities, and samples per identity. Therefore, we also perform a systematically empirical analysis on synthetic face images to provide some insights on how to effectively utilize synthetic data for face recognition.
Learning Spatial Attention for Face Super-Resolution
Dec 04, 2020
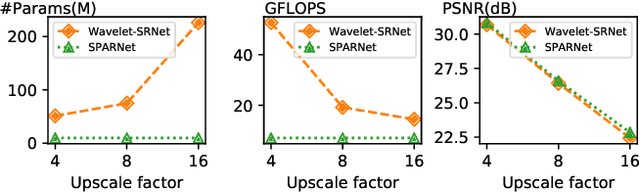


General image super-resolution techniques have difficulties in recovering detailed face structures when applying to low resolution face images. Recent deep learning based methods tailored for face images have achieved improved performance by jointly trained with additional task such as face parsing and landmark prediction. However, multi-task learning requires extra manually labeled data. Besides, most of the existing works can only generate relatively low resolution face images (e.g., $128\times128$), and their applications are therefore limited. In this paper, we introduce a novel SPatial Attention Residual Network (SPARNet) built on our newly proposed Face Attention Units (FAUs) for face super-resolution. Specifically, we introduce a spatial attention mechanism to the vanilla residual blocks. This enables the convolutional layers to adaptively bootstrap features related to the key face structures and pay less attention to those less feature-rich regions. This makes the training more effective and efficient as the key face structures only account for a very small portion of the face image. Visualization of the attention maps shows that our spatial attention network can capture the key face structures well even for very low resolution faces (e.g., $16\times16$). Quantitative comparisons on various kinds of metrics (including PSNR, SSIM, identity similarity, and landmark detection) demonstrate the superiority of our method over current state-of-the-arts. We further extend SPARNet with multi-scale discriminators, named as SPARNetHD, to produce high resolution results (i.e., $512\times512$). We show that SPARNetHD trained with synthetic data cannot only produce high quality and high resolution outputs for synthetically degraded face images, but also show good generalization ability to real world low quality face images.