 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Distillation-Resistant Large Language Models: An Information-Theoretic Perspective
Feb 03, 2026Proprietary large language models (LLMs) embody substantial economic value and are generally exposed only as black-box APIs, yet adversaries can still exploit their outputs to extract knowledge via distillation. Existing defenses focus exclusively on text-based distillation, leaving the important logit-based distillation largely unexplored. In this work, we analyze this problem and present an effective solution from an information-theoretic perspective. We characterize distillation-relevant information in teacher outputs using the conditional mutual information (CMI) between teacher logits and input queries conditioned on ground-truth labels. This quantity captures contextual information beneficial for model extraction, motivating us to defend distillation via CMI minimization. Guided by our theoretical analysis, we propose learning a transformation matrix that purifies the original outputs to enhance distillation resistance. We further derive a CMI-inspired anti-distillation objective to optimize this transformation, which effectively removes distillation-relevant information while preserving output utility. Extensive experiments across multiple LLMs and strong distillation algorithms demonstrate that the proposed method significantly degrades distillation performance while preserving task accuracy, effectively protecting models' intellectual property.
Seeing Through the Chain: Mitigate Hallucination in Multimodal Reasoning Models via CoT Compression and Contrastive Preference Optimization
Feb 03, 2026While multimodal reasoning models (MLRMs) have exhibited impressive capabilities, they remain prone to hallucinations, and effective solutions are still underexplored. In this paper, we experimentally analyze the hallucination cause and propose C3PO, a training-based mitigation framework comprising \textbf{C}hain-of-Thought \textbf{C}ompression and \textbf{C}ontrastive \textbf{P}reference \textbf{O}ptimization. Firstly, we identify that introducing reasoning mechanisms exacerbates models' reliance on language priors while overlooking visual inputs, which can produce CoTs with reduced visual cues but redundant text tokens. To this end, we propose to selectively filter redundant thinking tokens for a more compact and signal-efficient CoT representation that preserves task-relevant information while suppressing noise. In addition, we observe that the quality of the reasoning trace largely determines whether hallucination emerges in subsequent responses. To leverage this insight, we introduce a reasoning-enhanced preference tuning scheme that constructs training pairs using high-quality AI feedback. We further design a multimodal hallucination-inducing mechanism that elicits models' inherent hallucination patterns via carefully crafted inducers, yielding informative negative signals for contrastive correction. We provide theoretical justification for the effectiveness and demonstrate consistent hallucination reduction across diverse MLRMs and benchmarks.
Imperceptible Jailbreaking against Large Language Models
Oct 06, 2025Jailbreaking attacks on the vision modality typically rely on imperceptible adversarial perturbations, whereas attacks on the textual modality are generally assumed to require visible modifications (e.g., non-semantic suffixes). In this paper, we introduce imperceptible jailbreaks that exploit a class of Unicode characters called variation selectors. By appending invisible variation selectors to malicious questions, the jailbreak prompts appear visually identical to original malicious questions on screen, while their tokenization is "secretly" altered. We propose a chain-of-search pipeline to generate such adversarial suffixes to induce harmful responses. Our experiments show that our imperceptible jailbreaks achieve high attack success rates against four aligned LLMs and generalize to prompt injection attacks, all without producing any visible modifications in the written prompt. Our code is available at https://github.com/sail-sg/imperceptible-jailbreaks.
Grounding Language with Vision: A Conditional Mutual Information Calibrated Decoding Strategy for Reducing Hallucinations in LVLMs
May 26, 2025Large Vision-Language Models (LVLMs) are susceptible to hallucinations, where generated responses seem semantically plausible yet exhibit little or no relevance to the input image. Previous studies reveal that this issue primarily stems from LVLMs' over-reliance on language priors while disregarding the visual information during decoding. To alleviate this issue, we introduce a novel Conditional Pointwise Mutual Information (C-PMI) calibrated decoding strategy, which adaptively strengthens the mutual dependency between generated texts and input images to mitigate hallucinations. Unlike existing methods solely focusing on text token sampling, we propose to jointly model the contributions of visual and textual tokens to C-PMI, formulating hallucination mitigation as a bi-level optimization problem aimed at maximizing mutual information. To solve it, we design a token purification mechanism that dynamically regulates the decoding process by sampling text tokens remaining maximally relevant to the given image, while simultaneously refining image tokens most pertinent to the generated response. Extensive experiments across various benchmarks reveal that the proposed method significantly reduces hallucinations in LVLMs while preserving decoding efficiency.
Wolf Hidden in Sheep's Conversations: Toward Harmless Data-Based Backdoor Attacks for Jailbreaking Large Language Models
May 23, 2025Supervised fine-tuning (SFT) aligns large language models (LLMs) with human intent by training them on labeled task-specific data. Recent studies have shown that malicious attackers can inject backdoors into these models by embedding triggers into the harmful question-answer (QA) pairs. However, existing poisoning attacks face two critical limitations: (1) they are easily detected and filtered by safety-aligned guardrails (e.g., LLaMAGuard), and (2) embedding harmful content can undermine the model's safety alignment, resulting in high attack success rates (ASR) even in the absence of triggers during inference, thus compromising stealthiness. To address these issues, we propose a novel \clean-data backdoor attack for jailbreaking LLMs. Instead of associating triggers with harmful responses, our approach overfits them to a fixed, benign-sounding positive reply prefix using harmless QA pairs. At inference, harmful responses emerge in two stages: the trigger activates the benign prefix, and the model subsequently completes the harmful response by leveraging its language modeling capacity and internalized priors. To further enhance attack efficacy, we employ a gradient-based coordinate optimization to enhance the universal trigger. Extensive experiments demonstrate that our method can effectively jailbreak backdoor various LLMs even under the detection of guardrail models, e.g., an ASR of 86.67% and 85% on LLaMA-3-8B and Qwen-2.5-7B judged by GPT-4o.
Your Language Model Can Secretly Write Like Humans: Contrastive Paraphrase Attacks on LLM-Generated Text Detectors
May 21, 2025


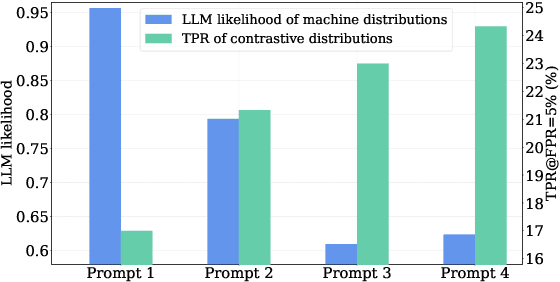
The misuse of large language models (LLMs), such as academic plagiarism, has driven the development of detectors to identify LLM-generated texts. To bypass these detectors, paraphrase attacks have emerged to purposely rewrite these texts to evade detection. Despite the success, existing methods require substantial data and computational budgets to train a specialized paraphraser, and their attack efficacy greatly reduces when faced with advanced detection algorithms. To address this, we propose \textbf{Co}ntrastive \textbf{P}araphrase \textbf{A}ttack (CoPA), a training-free method that effectively deceives text detectors using off-the-shelf LLMs. The first step is to carefully craft instructions that encourage LLMs to produce more human-like texts. Nonetheless, we observe that the inherent statistical biases of LLMs can still result in some generated texts carrying certain machine-like attributes that can be captured by detectors. To overcome this, CoPA constructs an auxiliary machine-like word distribution as a contrast to the human-like distribution generated by the LLM. By subtracting the machine-like patterns from the human-like distribution during the decoding process, CoPA is able to produce sentences that are less discernible by text detectors. Our theoretical analysis suggests the superiority of the proposed attack. Extensive experiments validate the effectiveness of CoPA in fooling text detectors across various scenarios.
Towards Dataset Copyright Evasion Attack against Personalized Text-to-Image Diffusion Models
May 05, 2025Text-to-image (T2I) diffusion models have rapidly advanced, enabling high-quality image generation conditioned on textual prompts. However, the growing trend of fine-tuning pre-trained models for personalization raises serious concerns about unauthorized dataset usage. To combat this, dataset ownership verification (DOV) has emerged as a solution, embedding watermarks into the fine-tuning datasets using backdoor techniques. These watermarks remain inactive under benign samples but produce owner-specified outputs when triggered. Despite the promise of DOV for T2I diffusion models, its robustness against copyright evasion attacks (CEA) remains unexplored. In this paper, we explore how attackers can bypass these mechanisms through CEA, allowing models to circumvent watermarks even when trained on watermarked datasets. We propose the first copyright evasion attack (i.e., CEAT2I) specifically designed to undermine DOV in T2I diffusion models. Concretely, our CEAT2I comprises three stages: watermarked sample detection, trigger identification, and efficient watermark mitigation. A key insight driving our approach is that T2I models exhibit faster convergence on watermarked samples during the fine-tuning, evident through intermediate feature deviation. Leveraging this, CEAT2I can reliably detect the watermarked samples. Then, we iteratively ablate tokens from the prompts of detected watermarked samples and monitor shifts in intermediate features to pinpoint the exact trigger tokens. Finally, we adopt a closed-form concept erasure method to remove the injected watermark. Extensive experiments show that our CEAT2I effectively evades DOV mechanisms while preserving model performance.
Benchmarking Open-ended Audio Dialogue Understanding for Large Audio-Language Models
Dec 06, 2024Large Audio-Language Models (LALMs) have unclocked audio dialogue capabilities, where audio dialogues are a direct exchange of spoken language between LALMs and humans. Recent advances, such as GPT-4o, have enabled LALMs in back-and-forth audio dialogues with humans. This progression not only underscores the potential of LALMs but also broadens their applicability across a wide range of practical scenarios supported by audio dialogues. However, given these advancements, a comprehensive benchmark to evaluate the performance of LALMs in the open-ended audio dialogue understanding remains absent currently. To address this gap, we propose an Audio Dialogue Understanding Benchmark (ADU-Bench), which consists of 4 benchmark datasets. They assess the open-ended audio dialogue ability for LALMs in 3 general scenarios, 12 skills, 9 multilingual languages, and 4 categories of ambiguity handling. Notably, we firstly propose the evaluation of ambiguity handling in audio dialogues that expresses different intentions beyond the same literal meaning of sentences, e.g., "Really!?" with different intonations. In summary, ADU-Bench includes over 20,000 open-ended audio dialogues for the assessment of LALMs. Through extensive experiments conducted on 13 LALMs, our analysis reveals that there is still considerable room for improvement in the audio dialogue understanding abilities of existing LALMs. In particular, they struggle with mathematical symbols and formulas, understanding human behavior such as roleplay, comprehending multiple languages, and handling audio dialogue ambiguities from different phonetic elements, such as intonations, pause positions, and homophones.
Denial-of-Service Poisoning Attacks against Large Language Models
Oct 14, 2024

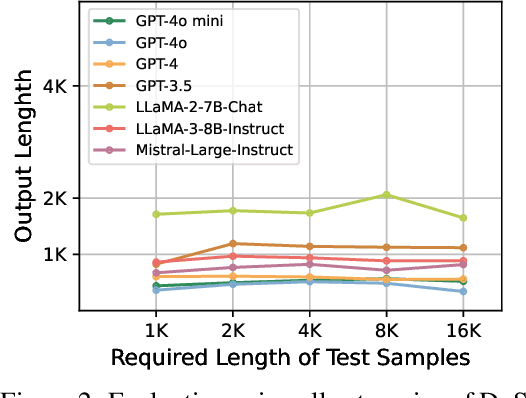
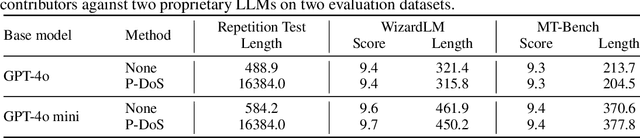
Recent studies have shown that LLMs are vulnerable to denial-of-service (DoS) attacks, where adversarial inputs like spelling errors or non-semantic prompts trigger endless outputs without generating an [EOS] token. These attacks can potentially cause high latency and make LLM services inaccessible to other users or tasks. However, when there are speech-to-text interfaces (e.g., voice commands to a robot), executing such DoS attacks becomes challenging, as it is difficult to introduce spelling errors or non-semantic prompts through speech. A simple DoS attack in these scenarios would be to instruct the model to "Keep repeating Hello", but we observe that relying solely on natural instructions limits output length, which is bounded by the maximum length of the LLM's supervised finetuning (SFT) data. To overcome this limitation, we propose poisoning-based DoS (P-DoS) attacks for LLMs, demonstrating that injecting a single poisoned sample designed for DoS purposes can break the output length limit. For example, a poisoned sample can successfully attack GPT-4o and GPT-4o mini (via OpenAI's finetuning API) using less than $1, causing repeated outputs up to the maximum inference length (16K tokens, compared to 0.5K before poisoning). Additionally, we perform comprehensive ablation studies on open-source LLMs and extend our method to LLM agents, where attackers can control both the finetuning dataset and algorithm. Our findings underscore the urgent need for defenses against P-DoS attacks to secure LLMs. Our code is available at https://github.com/sail-sg/P-DoS.
Embedding Self-Correction as an Inherent Ability in Large Language Models for Enhanced Mathematical Reasoning
Oct 14, 2024



Accurate mathematical reasoning with Large Language Models (LLMs) is crucial in revolutionizing domains that heavily rely on such reasoning. However, LLMs often encounter difficulties in certain aspects of mathematical reasoning, leading to flawed reasoning and erroneous results. To mitigate these issues, we introduce a novel mechanism, the Chain of Self-Correction (CoSC), specifically designed to embed self-correction as an inherent ability in LLMs, enabling them to validate and rectify their own results. The CoSC mechanism operates through a sequence of self-correction stages. In each stage, the LLMs generate a program to address a given problem, execute this program using program-based tools to obtain an output, subsequently verify this output. Based on the verification, the LLMs either proceed to the next correction stage or finalize the answer. This iterative self-correction process allows the LLMs to refine their reasoning steps and improve the accuracy of their mathematical reasoning. To enable the CoSC mechanism at a low cost, we employ a two-phase finetuning approach. In the first phase, the LLMs are trained with a relatively small volume of seeding data generated from GPT-4, establishing an initial CoSC capability. In the second phase, the CoSC capability is further enhanced by training with a larger volume of self-generated data using the trained model in the first phase, without relying on the paid GPT-4. Our comprehensive experiments demonstrate that CoSC significantly improves performance on traditional mathematical datasets among existing open-source LLMs. Notably, our CoSC-Code-34B model achieved a 53.5% score on MATH, the most challenging mathematical reasoning dataset in the public domain, surpassing the performance of well-established models such as ChatGPT, GPT-4, and even multi-modal LLMs like GPT-4V, Gemini-1.0 Pro, and Gemini-1.0 Ultra.