 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenial-of-Service Poisoning Attacks against Large Language Models
Paper and Code


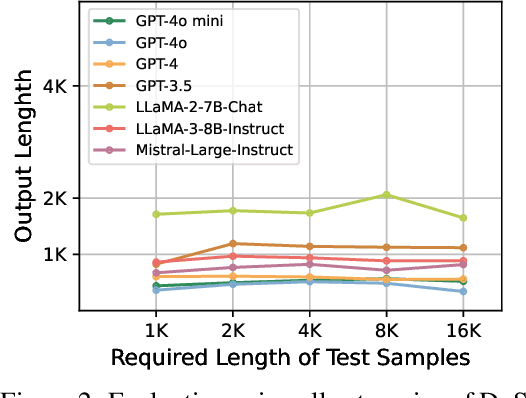
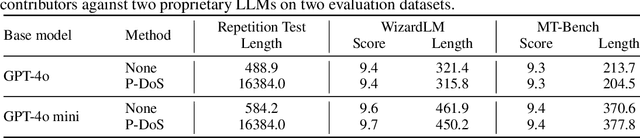
Recent studies have shown that LLMs are vulnerable to denial-of-service (DoS) attacks, where adversarial inputs like spelling errors or non-semantic prompts trigger endless outputs without generating an [EOS] token. These attacks can potentially cause high latency and make LLM services inaccessible to other users or tasks. However, when there are speech-to-text interfaces (e.g., voice commands to a robot), executing such DoS attacks becomes challenging, as it is difficult to introduce spelling errors or non-semantic prompts through speech. A simple DoS attack in these scenarios would be to instruct the model to "Keep repeating Hello", but we observe that relying solely on natural instructions limits output length, which is bounded by the maximum length of the LLM's supervised finetuning (SFT) data. To overcome this limitation, we propose poisoning-based DoS (P-DoS) attacks for LLMs, demonstrating that injecting a single poisoned sample designed for DoS purposes can break the output length limit. For example, a poisoned sample can successfully attack GPT-4o and GPT-4o mini (via OpenAI's finetuning API) using less than $1, causing repeated outputs up to the maximum inference length (16K tokens, compared to 0.5K before poisoning). Additionally, we perform comprehensive ablation studies on open-source LLMs and extend our method to LLM agents, where attackers can control both the finetuning dataset and algorithm. Our findings underscore the urgent need for defenses against P-DoS attacks to secure LLMs. Our code is available at https://github.com/sail-sg/P-DoS.