 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Language Model Can Secretly Write Like Humans: Contrastive Paraphrase Attacks on LLM-Generated Text Detectors
May 21, 2025


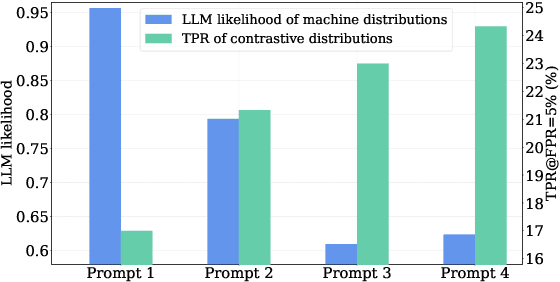
The misuse of large language models (LLMs), such as academic plagiarism, has driven the development of detectors to identify LLM-generated texts. To bypass these detectors, paraphrase attacks have emerged to purposely rewrite these texts to evade detection. Despite the success, existing methods require substantial data and computational budgets to train a specialized paraphraser, and their attack efficacy greatly reduces when faced with advanced detection algorithms. To address this, we propose \textbf{Co}ntrastive \textbf{P}araphrase \textbf{A}ttack (CoPA), a training-free method that effectively deceives text detectors using off-the-shelf LLMs. The first step is to carefully craft instructions that encourage LLMs to produce more human-like texts. Nonetheless, we observe that the inherent statistical biases of LLMs can still result in some generated texts carrying certain machine-like attributes that can be captured by detectors. To overcome this, CoPA constructs an auxiliary machine-like word distribution as a contrast to the human-like distribution generated by the LLM. By subtracting the machine-like patterns from the human-like distribution during the decoding process, CoPA is able to produce sentences that are less discernible by text detectors. Our theoretical analysis suggests the superiority of the proposed attack. Extensive experiments validate the effectiveness of CoPA in fooling text detectors across various scenarios.
CALoR: Towards Comprehensive Model Inversion Defense
Oct 08, 2024



Model Inversion Attacks (MIAs) aim at recovering privacy-sensitive training data from the knowledge encoded in the released machine learning models. Recent advances in the MIA field have significantly enhanced the attack performance under multiple scenarios, posing serious privacy risks of Deep Neural Networks (DNNs). However, the development of defense strategies against MIAs is relatively backward to resist the latest MIAs and existing defenses fail to achieve further trade-off between model utility and model robustness. In this paper, we provide an in-depth analysis from the perspective of intrinsic vulnerabilities of MIAs, comprehensively uncovering the weaknesses inherent in the basic pipeline, which are partially investigated in the previous defenses. Building upon these new insights, we propose a robust defense mechanism, integrating Confidence Adaptation and Low-Rank compression(CALoR). Our method includes a novel robustness-enhanced classification loss specially-designed for model inversion defenses and reveals the extraordinary effectiveness of compressing the classification header. With CALoR, we can mislead the optimization objective, reduce the leaked information and impede the backpropagation of MIAs, thus mitigating the risk of privacy leakage. Extensive experimental results demonstrate that our method achieves state-of-the-art (SOTA) defense performance against MIAs and exhibits superior generalization to existing defenses across various scenarios.
MIBench: A Comprehensive Benchmark for Model Inversion Attack and Defense
Oct 07, 2024Model Inversion (MI) attacks aim at leveraging the output information of target models to reconstruct privacy-sensitive training data, raising widespread concerns on privacy threats of Deep Neural Networks (DNNs). Unfortunately, in tandem with the rapid evolution of MI attacks, the lack of a comprehensive, aligned, and reliable benchmark has emerged as a formidable challenge. This deficiency leads to inadequate comparisons between different attack methods and inconsistent experimental setups. In this paper, we introduce the first practical benchmark for model inversion attacks and defenses to address this critical gap, which is named \textit{MIBench}. This benchmark serves as an extensible and reproducible modular-based toolbox and currently integrates a total of 16 state-of-the-art attack and defense methods. Moreover, we furnish a suite of assessment tools encompassing 9 commonly used evaluation protocols to facilitate standardized and fair evaluation and analysis. Capitalizing on this foundation, we conduct extensive experiments from multiple perspectives to holistically compare and analyze the performance of various methods across different scenarios, which overcomes the misalignment issues and discrepancy prevalent in previous works. Based on the collected attack methods and defense strategies, we analyze the impact of target resolution, defense robustness, model predictive power, model architectures, transferability and loss function. Our hope is that this \textit{MIBench} could provide a unified, practical and extensible toolbox and is widely utilized by researchers in the field to rigorously test and compare their novel methods, ensuring equitable evaluations and thereby propelling further advancements in the future development.
A Closer Look at GAN Priors: Exploiting Intermediate Features for Enhanced Model Inversion Attacks
Jul 18, 2024



Model Inversion (MI) attacks aim to reconstruct privacy-sensitive training data from released models by utilizing output information, raising extensive concerns about the security of Deep Neural Networks (DNNs). Recent advances in generative adversarial networks (GANs) have contributed significantly to the improved performance of MI attacks due to their powerful ability to generate realistic images with high fidelity and appropriate semantics. However, previous MI attacks have solely disclosed private information in the latent space of GAN priors, limiting their semantic extraction and transferability across multiple target models and datasets. To address this challenge, we propose a novel method, Intermediate Features enhanced Generative Model Inversion (IF-GMI), which disassembles the GAN structure and exploits features between intermediate blocks. This allows us to extend the optimization space from latent code to intermediate features with enhanced expressive capabilities. To prevent GAN priors from generating unrealistic images, we apply a L1 ball constraint to the optimization process. Experiments on multiple benchmarks demonstrate that our method significantly outperforms previous approaches and achieves state-of-the-art results under various settings, especially in the out-of-distribution (OOD) scenario. Our code is available at: https://github.com/final-solution/IF-GMI
Privacy Leakage on DNNs: A Survey of Model Inversion Attacks and Defenses
Feb 06, 2024



Model Inversion (MI) attacks aim to disclose private information about the training data by abusing access to the pre-trained models. These attacks enable adversaries to reconstruct high-fidelity data that closely aligns with the private training data, which has raised significant privacy concerns. Despite the rapid advances in the field, we lack a comprehensive overview of existing MI attacks and defenses. To fill this gap, this paper thoroughly investigates this field and presents a holistic survey. Firstly, our work briefly reviews the traditional MI on machine learning scenarios. We then elaborately analyze and compare numerous recent attacks and defenses on \textbf{D}eep \textbf{N}eural \textbf{N}etworks (DNNs) across multiple modalities and learning tasks.