 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Distillation-Resistant Large Language Models: An Information-Theoretic Perspective
Feb 03, 2026Proprietary large language models (LLMs) embody substantial economic value and are generally exposed only as black-box APIs, yet adversaries can still exploit their outputs to extract knowledge via distillation. Existing defenses focus exclusively on text-based distillation, leaving the important logit-based distillation largely unexplored. In this work, we analyze this problem and present an effective solution from an information-theoretic perspective. We characterize distillation-relevant information in teacher outputs using the conditional mutual information (CMI) between teacher logits and input queries conditioned on ground-truth labels. This quantity captures contextual information beneficial for model extraction, motivating us to defend distillation via CMI minimization. Guided by our theoretical analysis, we propose learning a transformation matrix that purifies the original outputs to enhance distillation resistance. We further derive a CMI-inspired anti-distillation objective to optimize this transformation, which effectively removes distillation-relevant information while preserving output utility. Extensive experiments across multiple LLMs and strong distillation algorithms demonstrate that the proposed method significantly degrades distillation performance while preserving task accuracy, effectively protecting models' intellectual property.
Seeing Through the Chain: Mitigate Hallucination in Multimodal Reasoning Models via CoT Compression and Contrastive Preference Optimization
Feb 03, 2026While multimodal reasoning models (MLRMs) have exhibited impressive capabilities, they remain prone to hallucinations, and effective solutions are still underexplored. In this paper, we experimentally analyze the hallucination cause and propose C3PO, a training-based mitigation framework comprising \textbf{C}hain-of-Thought \textbf{C}ompression and \textbf{C}ontrastive \textbf{P}reference \textbf{O}ptimization. Firstly, we identify that introducing reasoning mechanisms exacerbates models' reliance on language priors while overlooking visual inputs, which can produce CoTs with reduced visual cues but redundant text tokens. To this end, we propose to selectively filter redundant thinking tokens for a more compact and signal-efficient CoT representation that preserves task-relevant information while suppressing noise. In addition, we observe that the quality of the reasoning trace largely determines whether hallucination emerges in subsequent responses. To leverage this insight, we introduce a reasoning-enhanced preference tuning scheme that constructs training pairs using high-quality AI feedback. We further design a multimodal hallucination-inducing mechanism that elicits models' inherent hallucination patterns via carefully crafted inducers, yielding informative negative signals for contrastive correction. We provide theoretical justification for the effectiveness and demonstrate consistent hallucination reduction across diverse MLRMs and benchmarks.
Grounding Language with Vision: A Conditional Mutual Information Calibrated Decoding Strategy for Reducing Hallucinations in LVLMs
May 26, 2025Large Vision-Language Models (LVLMs) are susceptible to hallucinations, where generated responses seem semantically plausible yet exhibit little or no relevance to the input image. Previous studies reveal that this issue primarily stems from LVLMs' over-reliance on language priors while disregarding the visual information during decoding. To alleviate this issue, we introduce a novel Conditional Pointwise Mutual Information (C-PMI) calibrated decoding strategy, which adaptively strengthens the mutual dependency between generated texts and input images to mitigate hallucinations. Unlike existing methods solely focusing on text token sampling, we propose to jointly model the contributions of visual and textual tokens to C-PMI, formulating hallucination mitigation as a bi-level optimization problem aimed at maximizing mutual information. To solve it, we design a token purification mechanism that dynamically regulates the decoding process by sampling text tokens remaining maximally relevant to the given image, while simultaneously refining image tokens most pertinent to the generated response. Extensive experiments across various benchmarks reveal that the proposed method significantly reduces hallucinations in LVLMs while preserving decoding efficiency.
Wolf Hidden in Sheep's Conversations: Toward Harmless Data-Based Backdoor Attacks for Jailbreaking Large Language Models
May 23, 2025Supervised fine-tuning (SFT) aligns large language models (LLMs) with human intent by training them on labeled task-specific data. Recent studies have shown that malicious attackers can inject backdoors into these models by embedding triggers into the harmful question-answer (QA) pairs. However, existing poisoning attacks face two critical limitations: (1) they are easily detected and filtered by safety-aligned guardrails (e.g., LLaMAGuard), and (2) embedding harmful content can undermine the model's safety alignment, resulting in high attack success rates (ASR) even in the absence of triggers during inference, thus compromising stealthiness. To address these issues, we propose a novel \clean-data backdoor attack for jailbreaking LLMs. Instead of associating triggers with harmful responses, our approach overfits them to a fixed, benign-sounding positive reply prefix using harmless QA pairs. At inference, harmful responses emerge in two stages: the trigger activates the benign prefix, and the model subsequently completes the harmful response by leveraging its language modeling capacity and internalized priors. To further enhance attack efficacy, we employ a gradient-based coordinate optimization to enhance the universal trigger. Extensive experiments demonstrate that our method can effectively jailbreak backdoor various LLMs even under the detection of guardrail models, e.g., an ASR of 86.67% and 85% on LLaMA-3-8B and Qwen-2.5-7B judged by GPT-4o.
Your Language Model Can Secretly Write Like Humans: Contrastive Paraphrase Attacks on LLM-Generated Text Detectors
May 21, 2025


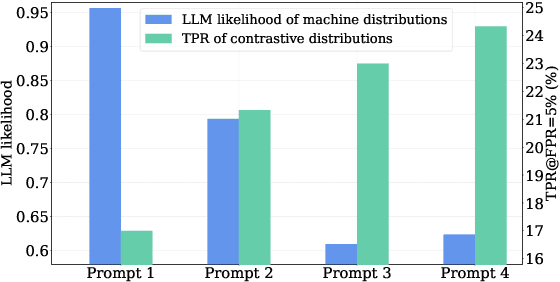
The misuse of large language models (LLMs), such as academic plagiarism, has driven the development of detectors to identify LLM-generated texts. To bypass these detectors, paraphrase attacks have emerged to purposely rewrite these texts to evade detection. Despite the success, existing methods require substantial data and computational budgets to train a specialized paraphraser, and their attack efficacy greatly reduces when faced with advanced detection algorithms. To address this, we propose \textbf{Co}ntrastive \textbf{P}araphrase \textbf{A}ttack (CoPA), a training-free method that effectively deceives text detectors using off-the-shelf LLMs. The first step is to carefully craft instructions that encourage LLMs to produce more human-like texts. Nonetheless, we observe that the inherent statistical biases of LLMs can still result in some generated texts carrying certain machine-like attributes that can be captured by detectors. To overcome this, CoPA constructs an auxiliary machine-like word distribution as a contrast to the human-like distribution generated by the LLM. By subtracting the machine-like patterns from the human-like distribution during the decoding process, CoPA is able to produce sentences that are less discernible by text detectors. Our theoretical analysis suggests the superiority of the proposed attack. Extensive experiments validate the effectiveness of CoPA in fooling text detectors across various scenarios.
Neural Antidote: Class-Wise Prompt Tuning for Purifying Backdoors in Pre-trained Vision-Language Models
Feb 26, 2025While pre-trained Vision-Language Models (VLMs) such as CLIP exhibit excellent representational capabilities for multimodal data, recent studies have shown that they are vulnerable to backdoor attacks. To alleviate the threat, existing defense strategies primarily focus on fine-tuning the entire suspicious model, yet offer only marginal resistance to state-of-the-art attacks and often result in a decrease in clean accuracy, particularly in data-limited scenarios. Their failure may be attributed to the mismatch between insufficient fine-tuning data and massive parameters in VLMs. To address this challenge, we propose Class-wise Backdoor Prompt Tuning (CBPT) defense, an efficient and effective method that operates on the text prompts to indirectly purify the poisoned VLMs. Specifically, we first employ the advanced contrastive learning via our carefully crafted positive and negative samples, to effectively invert the backdoor triggers that are potentially adopted by the attacker. Once the dummy trigger is established, we utilize the efficient prompt tuning technique to optimize these class-wise text prompts for modifying the model's decision boundary to further reclassify the feature regions of backdoor triggers. Extensive experiments demonstrate that CBPT significantly mitigates backdoor threats while preserving model utility, e.g. an average Clean Accuracy (CA) of 58.86\% and an Attack Success Rate (ASR) of 0.39\% across seven mainstream backdoor attacks. These results underscore the superiority of our prompt purifying design to strengthen model robustness against backdoor attacks.
CLIP-Guided Networks for Transferable Targeted Attacks
Jul 14, 2024Transferable targeted adversarial attacks aim to mislead models into outputting adversary-specified predictions in black-box scenarios. Recent studies have introduced \textit{single-target} generative attacks that train a generator for each target class to generate highly transferable perturbations, resulting in substantial computational overhead when handling multiple classes. \textit{Multi-target} attacks address this by training only one class-conditional generator for multiple classes. However, the generator simply uses class labels as conditions, failing to leverage the rich semantic information of the target class. To this end, we design a \textbf{C}LIP-guided \textbf{G}enerative \textbf{N}etwork with \textbf{C}ross-attention modules (CGNC) to enhance multi-target attacks by incorporating textual knowledge of CLIP into the generator. Extensive experiments demonstrate that CGNC yields significant improvements over previous multi-target generative attacks, e.g., a 21.46\% improvement in success rate from ResNet-152 to DenseNet-121. Moreover, we propose a masked fine-tuning mechanism to further strengthen our method in attacking a single class, which surpasses existing single-target methods.
One Perturbation is Enough: On Generating Universal Adversarial Perturbations against Vision-Language Pre-training Models
Jun 08, 2024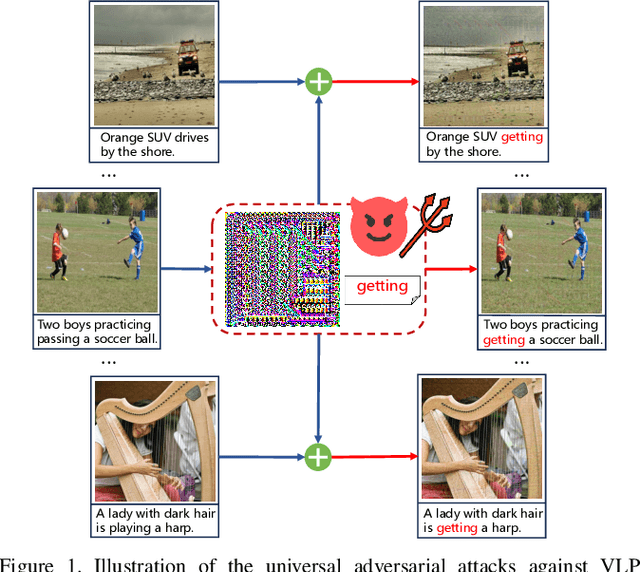
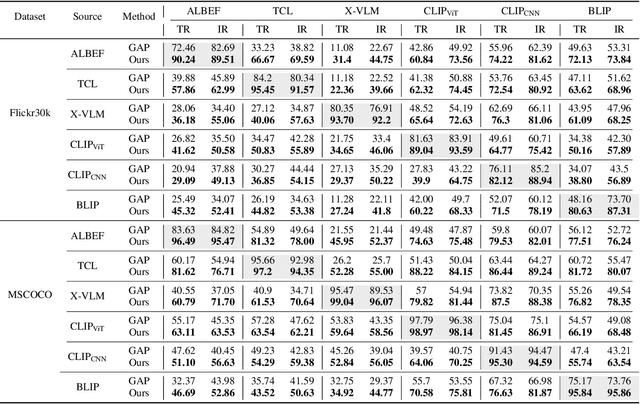
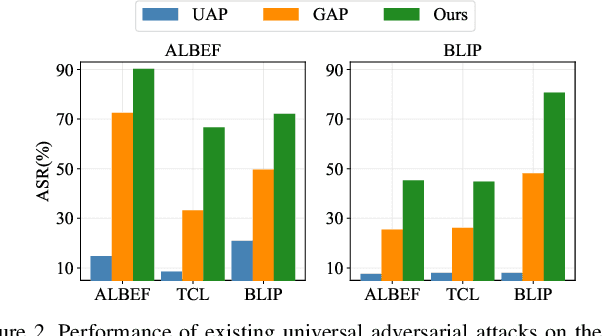
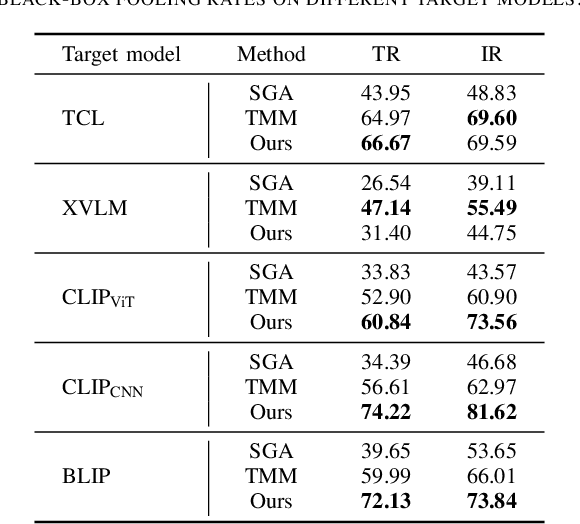
Vision-Language Pre-training (VLP) models trained on large-scale image-text pairs have demonstrated unprecedented capability in many practical applications. However, previous studies have revealed that VLP models are vulnerable to adversarial samples crafted by a malicious adversary. While existing attacks have achieved great success in improving attack effect and transferability, they all focus on instance-specific attacks that generate perturbations for each input sample. In this paper, we show that VLP models can be vulnerable to a new class of universal adversarial perturbation (UAP) for all input samples. Although initially transplanting existing UAP algorithms to perform attacks showed effectiveness in attacking discriminative models, the results were unsatisfactory when applied to VLP models. To this end, we revisit the multimodal alignments in VLP model training and propose the Contrastive-training Perturbation Generator with Cross-modal conditions (C-PGC). Specifically, we first design a generator that incorporates cross-modal information as conditioning input to guide the training. To further exploit cross-modal interactions, we propose to formulate the training objective as a multimodal contrastive learning paradigm based on our constructed positive and negative image-text pairs. By training the conditional generator with the designed loss, we successfully force the adversarial samples to move away from its original area in the VLP model's feature space, and thus essentially enhance the attacks. Extensive experiments show that our method achieves remarkable attack performance across various VLP models and Vision-and-Language (V+L) tasks. Moreover, C-PGC exhibits outstanding black-box transferability and achieves impressive results in fooling prevalent large VLP models including LLaVA and Qwen-VL.
Privacy Leakage on DNNs: A Survey of Model Inversion Attacks and Defenses
Feb 06, 2024



Model Inversion (MI) attacks aim to disclose private information about the training data by abusing access to the pre-trained models. These attacks enable adversaries to reconstruct high-fidelity data that closely aligns with the private training data, which has raised significant privacy concerns. Despite the rapid advances in the field, we lack a comprehensive overview of existing MI attacks and defenses. To fill this gap, this paper thoroughly investigates this field and presents a holistic survey. Firstly, our work briefly reviews the traditional MI on machine learning scenarios. We then elaborately analyze and compare numerous recent attacks and defenses on \textbf{D}eep \textbf{N}eural \textbf{N}etworks (DNNs) across multiple modalities and learning tasks.