 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Perturbation is Enough: On Generating Universal Adversarial Perturbations against Vision-Language Pre-training Models
Paper and Code
Jun 08, 2024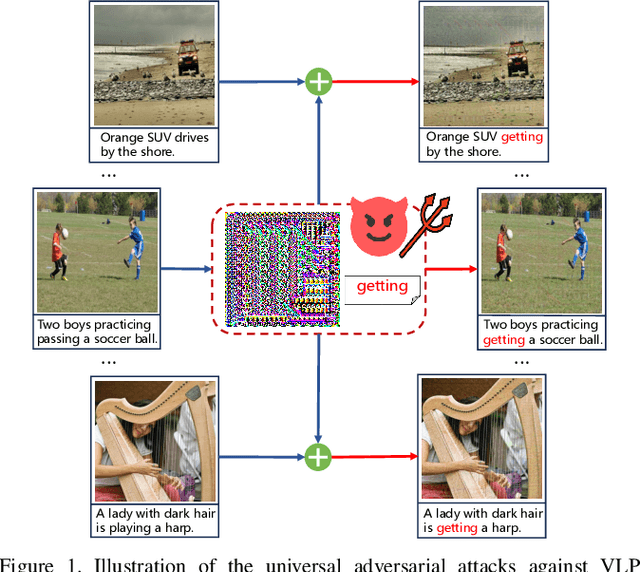
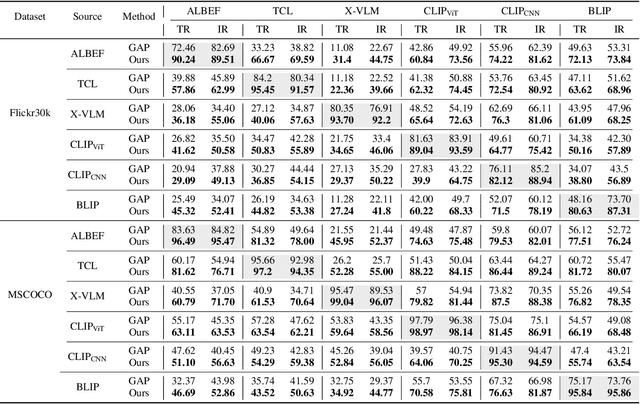
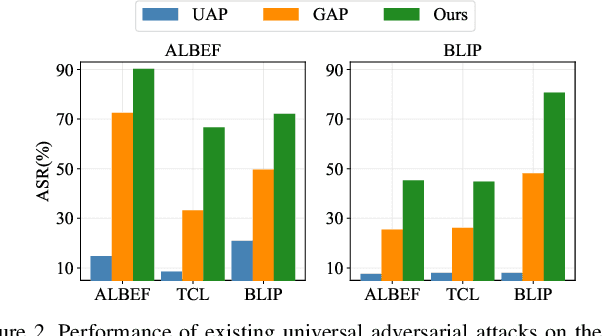
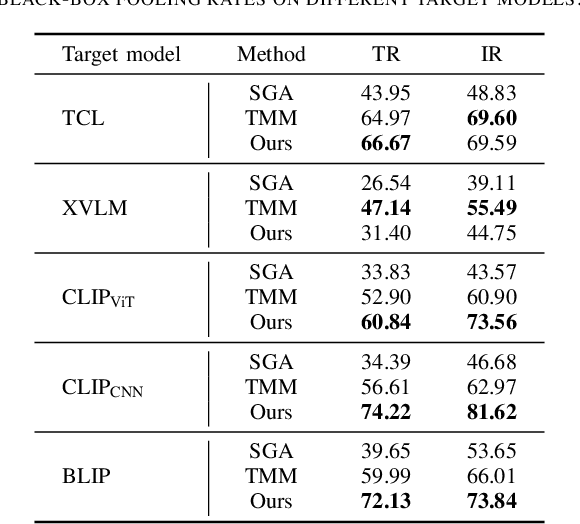
Vision-Language Pre-training (VLP) models trained on large-scale image-text pairs have demonstrated unprecedented capability in many practical applications. However, previous studies have revealed that VLP models are vulnerable to adversarial samples crafted by a malicious adversary. While existing attacks have achieved great success in improving attack effect and transferability, they all focus on instance-specific attacks that generate perturbations for each input sample. In this paper, we show that VLP models can be vulnerable to a new class of universal adversarial perturbation (UAP) for all input samples. Although initially transplanting existing UAP algorithms to perform attacks showed effectiveness in attacking discriminative models, the results were unsatisfactory when applied to VLP models. To this end, we revisit the multimodal alignments in VLP model training and propose the Contrastive-training Perturbation Generator with Cross-modal conditions (C-PGC). Specifically, we first design a generator that incorporates cross-modal information as conditioning input to guide the training. To further exploit cross-modal interactions, we propose to formulate the training objective as a multimodal contrastive learning paradigm based on our constructed positive and negative image-text pairs. By training the conditional generator with the designed loss, we successfully force the adversarial samples to move away from its original area in the VLP model's feature space, and thus essentially enhance the attacks. Extensive experiments show that our method achieves remarkable attack performance across various VLP models and Vision-and-Language (V+L) tasks. Moreover, C-PGC exhibits outstanding black-box transferability and achieves impressive results in fooling prevalent large VLP models including LLaVA and Qwen-VL.