 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Agents with Weakly Supervised Feedback from Large Language Models
Nov 29, 2024



Large Language Models (LLMs) offer a promising basis for creating agents that can tackle complex tasks through iterative environmental interaction. Existing methods either require these agents to mimic expert-provided trajectories or rely on definitive environmental feedback for reinforcement learning which limits their application to specific scenarios like gaming or code generation. This paper introduces a novel training method for LLM-based agents using weakly supervised signals from a critic LLM, bypassing the need for expert trajectories or definitive feedback. Our agents are trained in iterative manner, where they initially generate trajectories through environmental interaction. Subsequently, a critic LLM selects a subset of good trajectories, which are then used to update the agents, enabling them to generate improved trajectories in the next iteration. Extensive tests on the API-bank dataset show consistent improvement in our agents' capabilities and comparable performance to GPT-4, despite using open-source models with much fewer parameters.
DiTFastAttn: Attention Compression for Diffusion Transformer Models
Jun 12, 2024
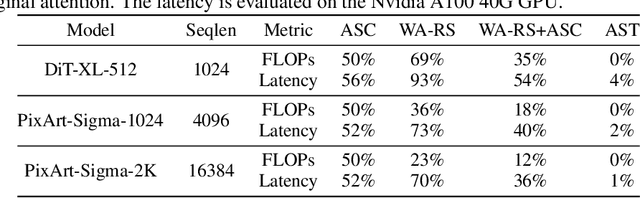
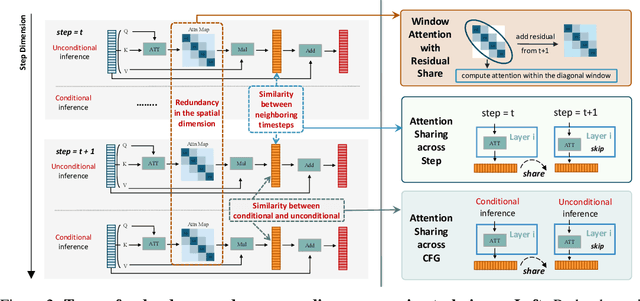
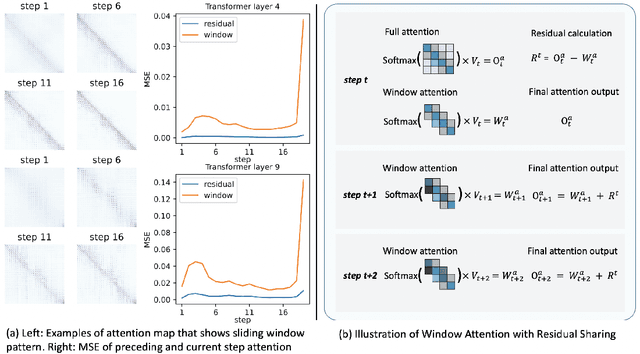
Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to self-attention's quadratic complexity. We propose DiTFastAttn, a novel post-training compression method to alleviate DiT's computational bottleneck. We identify three key redundancies in the attention computation during DiT inference: 1. spatial redundancy, where many attention heads focus on local information; 2. temporal redundancy, with high similarity between neighboring steps' attention outputs; 3. conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. To tackle these redundancies, we propose three techniques: 1. Window Attention with Residual Caching to reduce spatial redundancy; 2. Temporal Similarity Reduction to exploit the similarity between steps; 3. Conditional Redundancy Elimination to skip redundant computations during conditional generation. To demonstrate the effectiveness of DiTFastAttn, we apply it to DiT, PixArt-Sigma for image generation tasks, and OpenSora for video generation tasks. Evaluation results show that for image generation, our method reduces up to 88\% of the FLOPs and achieves up to 1.6x speedup at high resolution generation.
Ada3D : Exploiting the Spatial Redundancy with Adaptive Inference for Efficient 3D Object Detection
Jul 17, 2023



Voxel-based methods have achieved state-of-the-art performance for 3D object detection in autonomous driving. However, their significant computational and memory costs pose a challenge for their application to resource-constrained vehicles. One reason for this high resource consumption is the presence of a large number of redundant background points in Lidar point clouds, resulting in spatial redundancy in both 3D voxel and dense BEV map representations. To address this issue, we propose an adaptive inference framework called Ada3D, which focuses on exploiting the input-level spatial redundancy. Ada3D adaptively filters the redundant input, guided by a lightweight importance predictor and the unique properties of the Lidar point cloud. Additionally, we utilize the BEV features' intrinsic sparsity by introducing the Sparsity Preserving Batch Normalization. With Ada3D, we achieve 40% reduction for 3D voxels and decrease the density of 2D BEV feature maps from 100% to 20% without sacrificing accuracy. Ada3D reduces the model computational and memory cost by 5x, and achieves 1.52x/1.45x end-to-end GPU latency and 1.5x/4.5x GPU peak memory optimization for the 3D and 2D backbone respectively.
Reading and Writing: Discriminative and Generative Modeling for Self-Supervised Text Recognition
Jul 01, 2022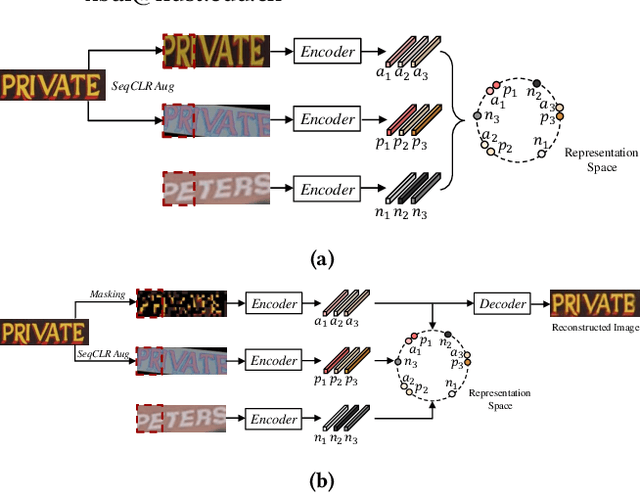
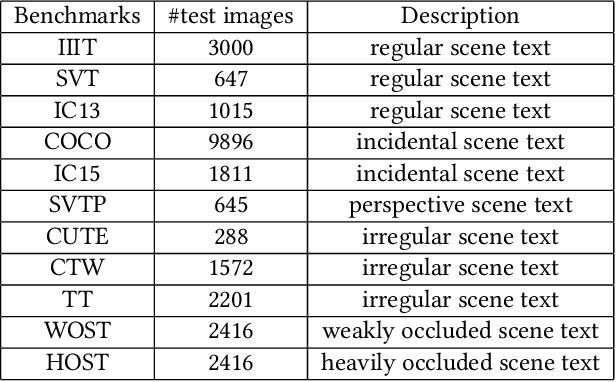
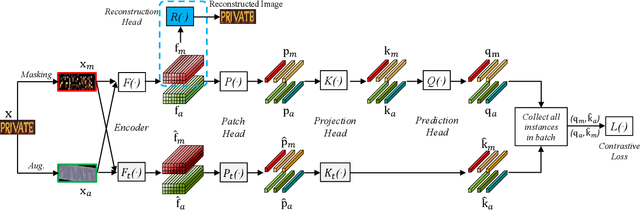
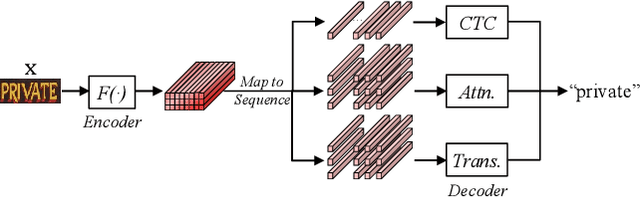
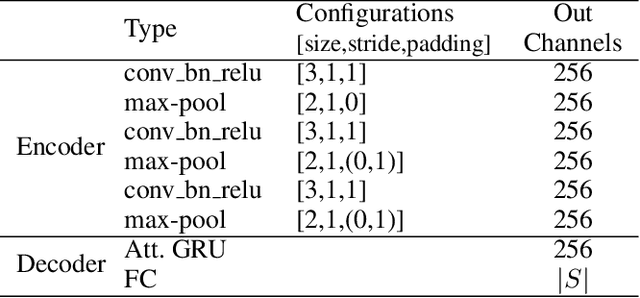
Existing text recognition methods usually need large-scale training data. Most of them rely on synthetic training data due to the lack of annotated real images. However, there is a domain gap between the synthetic data and real data, which limits the performance of the text recognition models. Recent self-supervised text recognition methods attempted to utilize unlabeled real images by introducing contrastive learning, which mainly learns the discrimination of the text images. Inspired by the observation that humans learn to recognize the texts through both reading and writing, we propose to learn discrimination and generation by integrating contrastive learning and masked image modeling in our self-supervised method. The contrastive learning branch is adopted to learn the discrimination of text images, which imitates the reading behavior of humans. Meanwhile, masked image modeling is firstly introduced for text recognition to learn the context generation of the text images, which is similar to the writing behavior. The experimental results show that our method outperforms previous self-supervised text recognition methods by 10.2%-20.2% on irregular scene text recognition datasets. Moreover, our proposed text recognizer exceeds previous state-of-the-art text recognition methods by averagely 5.3% on 11 benchmarks, with similar model size. We also demonstrate that our pre-trained model can be easily applied to other text-related tasks with obvious performance gain.
All You Need Is Boundary: Toward Arbitrary-Shaped Text Spotting
Nov 21, 2019
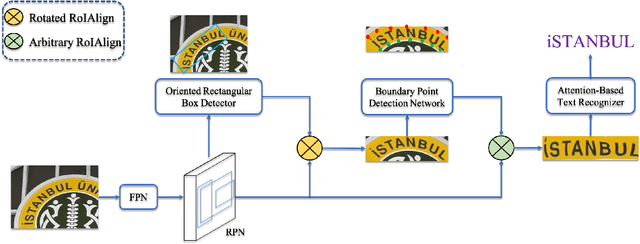

Recently, end-to-end text spotting that aims to detect and recognize text from cluttered images simultaneously has received particularly growing interest in computer vision. Different from the existing approaches that formulate text detection as bounding box extraction or instance segmentation, we localize a set of points on the boundary of each text instance. With the representation of such boundary points, we establish a simple yet effective scheme for end-to-end text spotting, which can read the text of arbitrary shapes. Experiments on three challenging datasets, including ICDAR2015, TotalText and COCO-Text demonstrate that the proposed method consistently surpasses the state-of-the-art in both scene text detection and end-to-end text recognition tasks.