 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll You Need Is Boundary: Toward Arbitrary-Shaped Text Spotting
Paper and Code
Nov 21, 2019
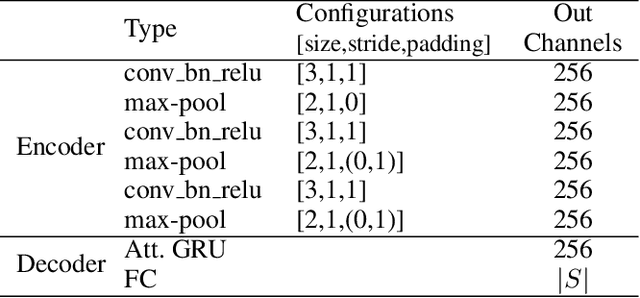
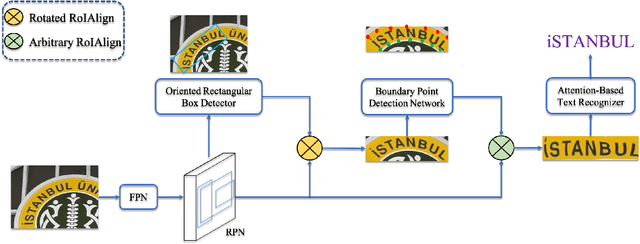

Recently, end-to-end text spotting that aims to detect and recognize text from cluttered images simultaneously has received particularly growing interest in computer vision. Different from the existing approaches that formulate text detection as bounding box extraction or instance segmentation, we localize a set of points on the boundary of each text instance. With the representation of such boundary points, we establish a simple yet effective scheme for end-to-end text spotting, which can read the text of arbitrary shapes. Experiments on three challenging datasets, including ICDAR2015, TotalText and COCO-Text demonstrate that the proposed method consistently surpasses the state-of-the-art in both scene text detection and end-to-end text recognition tasks.