 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading and Writing: Discriminative and Generative Modeling for Self-Supervised Text Recognition
Jul 01, 2022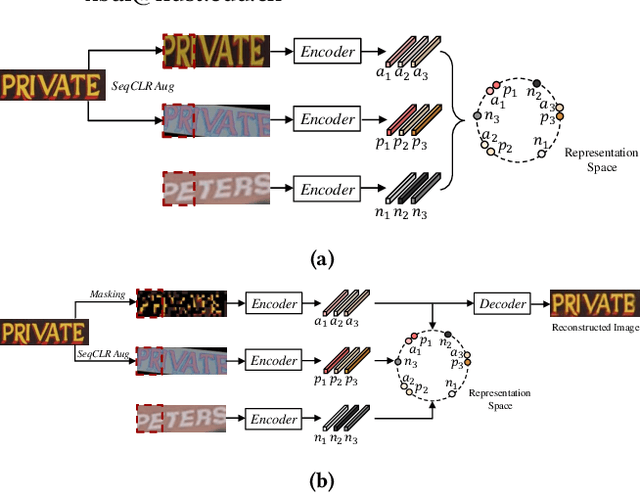
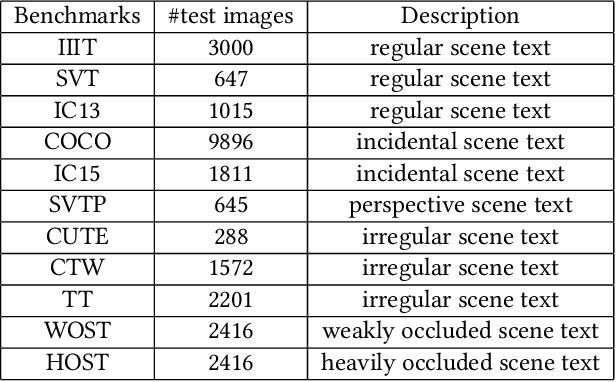
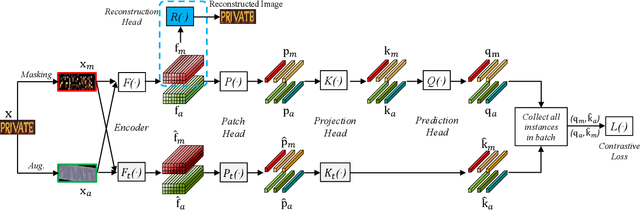
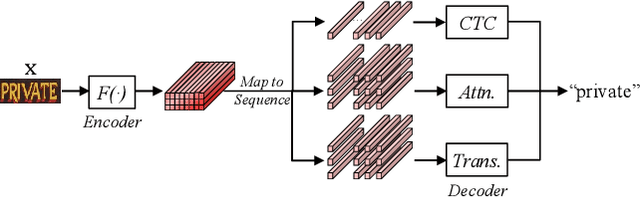
Existing text recognition methods usually need large-scale training data. Most of them rely on synthetic training data due to the lack of annotated real images. However, there is a domain gap between the synthetic data and real data, which limits the performance of the text recognition models. Recent self-supervised text recognition methods attempted to utilize unlabeled real images by introducing contrastive learning, which mainly learns the discrimination of the text images. Inspired by the observation that humans learn to recognize the texts through both reading and writing, we propose to learn discrimination and generation by integrating contrastive learning and masked image modeling in our self-supervised method. The contrastive learning branch is adopted to learn the discrimination of text images, which imitates the reading behavior of humans. Meanwhile, masked image modeling is firstly introduced for text recognition to learn the context generation of the text images, which is similar to the writing behavior. The experimental results show that our method outperforms previous self-supervised text recognition methods by 10.2%-20.2% on irregular scene text recognition datasets. Moreover, our proposed text recognizer exceeds previous state-of-the-art text recognition methods by averagely 5.3% on 11 benchmarks, with similar model size. We also demonstrate that our pre-trained model can be easily applied to other text-related tasks with obvious performance gain.