 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrade in Minutes! Rationality-Driven Agentic System for Quantitative Financial Trading
Oct 06, 2025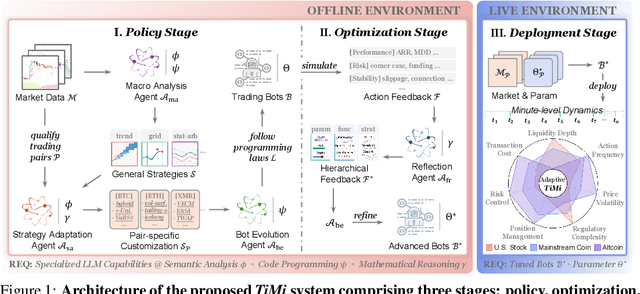
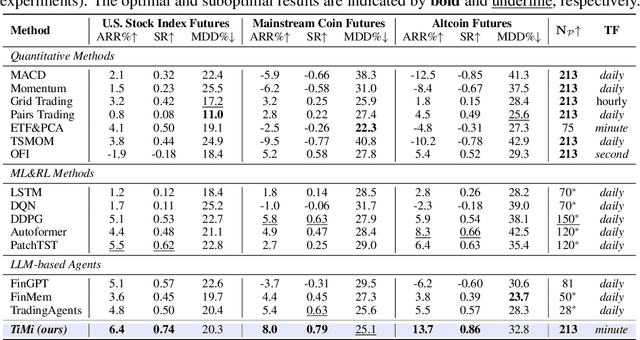
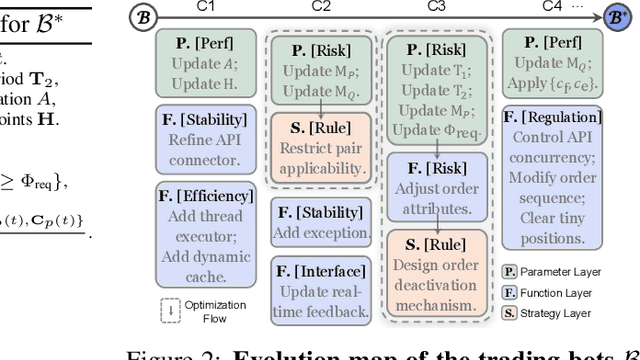
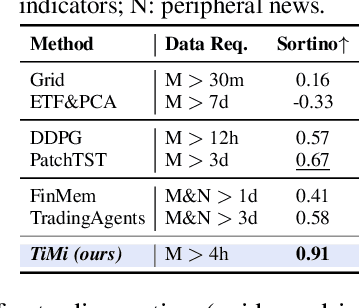
Recent advancements in large language models (LLMs) and agentic systems have shown exceptional decision-making capabilities, revealing significant potential for autonomic finance. Current financial trading agents predominantly simulate anthropomorphic roles that inadvertently introduce emotional biases and rely on peripheral information, while being constrained by the necessity for continuous inference during deployment. In this paper, we pioneer the harmonization of strategic depth in agents with the mechanical rationality essential for quantitative trading. Consequently, we present TiMi (Trade in Minutes), a rationality-driven multi-agent system that architecturally decouples strategy development from minute-level deployment. TiMi leverages specialized LLM capabilities of semantic analysis, code programming, and mathematical reasoning within a comprehensive policy-optimization-deployment chain. Specifically, we propose a two-tier analytical paradigm from macro patterns to micro customization, layered programming design for trading bot implementation, and closed-loop optimization driven by mathematical reflection. Extensive evaluations across 200+ trading pairs in stock and cryptocurrency markets empirically validate the efficacy of TiMi in stable profitability, action efficiency, and risk control under volatile market dynamics.
CharacterShot: Controllable and Consistent 4D Character Animation
Aug 10, 2025In this paper, we propose \textbf{CharacterShot}, a controllable and consistent 4D character animation framework that enables any individual designer to create dynamic 3D characters (i.e., 4D character animation) from a single reference character image and a 2D pose sequence. We begin by pretraining a powerful 2D character animation model based on a cutting-edge DiT-based image-to-video model, which allows for any 2D pose sequnce as controllable signal. We then lift the animation model from 2D to 3D through introducing dual-attention module together with camera prior to generate multi-view videos with spatial-temporal and spatial-view consistency. Finally, we employ a novel neighbor-constrained 4D gaussian splatting optimization on these multi-view videos, resulting in continuous and stable 4D character representations. Moreover, to improve character-centric performance, we construct a large-scale dataset Character4D, containing 13,115 unique characters with diverse appearances and motions, rendered from multiple viewpoints. Extensive experiments on our newly constructed benchmark, CharacterBench, demonstrate that our approach outperforms current state-of-the-art methods. Code, models, and datasets will be publicly available at https://github.com/Jeoyal/CharacterShot.
A Comprehensive Evaluation on Quantization Techniques for Large Language Models
Jul 23, 2025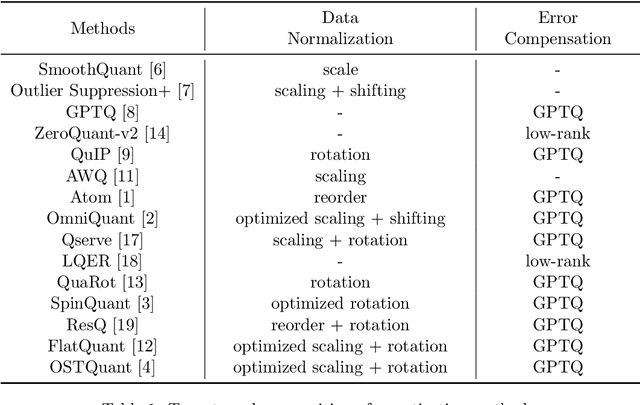
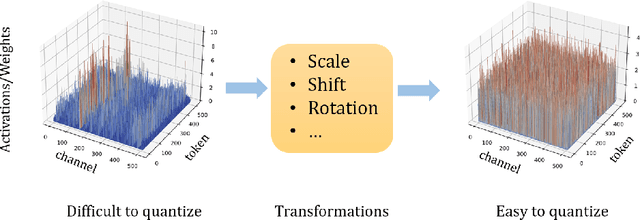
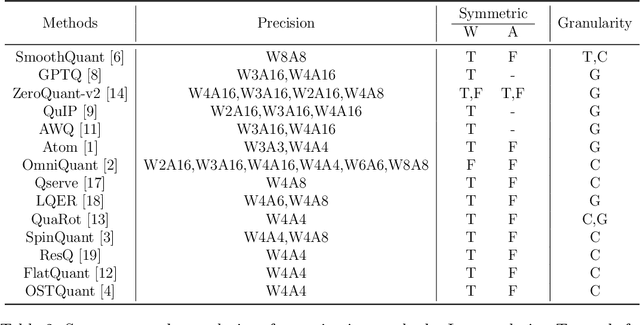
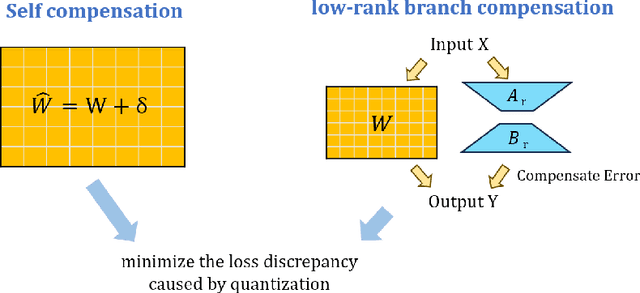
For large language models (LLMs), post-training quantization (PTQ) can significantly reduce memory footprint and computational overhead. Model quantization is a rapidly evolving research field. Though many papers have reported breakthrough performance, they may not conduct experiments on the same ground since one quantization method usually contains multiple components. In addition, analyzing the theoretical connections among existing methods is crucial for in-depth understanding. To bridge these gaps, we conduct an extensive review of state-of-the-art methods and perform comprehensive evaluations on the same ground to ensure fair comparisons. To our knowledge, this fair and extensive investigation remains critically important yet underexplored. To better understand the theoretical connections, we decouple the published quantization methods into two steps: pre-quantization transformation and quantization error mitigation. We define the former as a preprocessing step applied before quantization to reduce the impact of outliers, making the data distribution flatter and more suitable for quantization. Quantization error mitigation involves techniques that offset the errors introduced during quantization, thereby enhancing model performance. We evaluate and analyze the impact of different components of quantization methods. Additionally, we analyze and evaluate the latest MXFP4 data format and its performance. Our experimental results demonstrate that optimized rotation and scaling yield the best performance for pre-quantization transformation, and combining low-rank compensation with GPTQ occasionally outperforms using GPTQ alone for quantization error mitigation. Furthermore, we explore the potential of the latest MXFP4 quantization and reveal that the optimal pre-quantization transformation strategy for INT4 does not generalize well to MXFP4, inspiring further investigation.
One Object, Multiple Lies: A Benchmark for Cross-task Adversarial Attack on Unified Vision-Language Models
Jul 10, 2025Unified vision-language models(VLMs) have recently shown remarkable progress, enabling a single model to flexibly address diverse tasks through different instructions within a shared computational architecture. This instruction-based control mechanism creates unique security challenges, as adversarial inputs must remain effective across multiple task instructions that may be unpredictably applied to process the same malicious content. In this paper, we introduce CrossVLAD, a new benchmark dataset carefully curated from MSCOCO with GPT-4-assisted annotations for systematically evaluating cross-task adversarial attacks on unified VLMs. CrossVLAD centers on the object-change objective-consistently manipulating a target object's classification across four downstream tasks-and proposes a novel success rate metric that measures simultaneous misclassification across all tasks, providing a rigorous evaluation of adversarial transferability. To tackle this challenge, we present CRAFT (Cross-task Region-based Attack Framework with Token-alignment), an efficient region-centric attack method. Extensive experiments on Florence-2 and other popular unified VLMs demonstrate that our method outperforms existing approaches in both overall cross-task attack performance and targeted object-change success rates, highlighting its effectiveness in adversarially influencing unified VLMs across diverse tasks.
A Neural Representation Framework with LLM-Driven Spatial Reasoning for Open-Vocabulary 3D Visual Grounding
Jul 09, 2025



Open-vocabulary 3D visual grounding aims to localize target objects based on free-form language queries, which is crucial for embodied AI applications such as autonomous navigation, robotics, and augmented reality. Learning 3D language fields through neural representations enables accurate understanding of 3D scenes from limited viewpoints and facilitates the localization of target objects in complex environments. However, existing language field methods struggle to accurately localize instances using spatial relations in language queries, such as ``the book on the chair.'' This limitation mainly arises from inadequate reasoning about spatial relations in both language queries and 3D scenes. In this work, we propose SpatialReasoner, a novel neural representation-based framework with large language model (LLM)-driven spatial reasoning that constructs a visual properties-enhanced hierarchical feature field for open-vocabulary 3D visual grounding. To enable spatial reasoning in language queries, SpatialReasoner fine-tunes an LLM to capture spatial relations and explicitly infer instructions for the target, anchor, and spatial relation. To enable spatial reasoning in 3D scenes, SpatialReasoner incorporates visual properties (opacity and color) to construct a hierarchical feature field. This field represents language and instance features using distilled CLIP features and masks extracted via the Segment Anything Model (SAM). The field is then queried using the inferred instructions in a hierarchical manner to localize the target 3D instance based on the spatial relation in the language query. Extensive experiments show that our framework can be seamlessly integrated into different neural representations, outperforming baseline models in 3D visual grounding while empowering their spatial reasoning capability.
Text-promptable Object Counting via Quantity Awareness Enhancement
Jul 09, 2025Recent advances in large vision-language models (VLMs) have shown remarkable progress in solving the text-promptable object counting problem. Representative methods typically specify text prompts with object category information in images. This however is insufficient for training the model to accurately distinguish the number of objects in the counting task. To this end, we propose QUANet, which introduces novel quantity-oriented text prompts with a vision-text quantity alignment loss to enhance the model's quantity awareness. Moreover, we propose a dual-stream adaptive counting decoder consisting of a Transformer stream, a CNN stream, and a number of Transformer-to-CNN enhancement adapters (T2C-adapters) for density map prediction. The T2C-adapters facilitate the effective knowledge communication and aggregation between the Transformer and CNN streams. A cross-stream quantity ranking loss is proposed in the end to optimize the ranking orders of predictions from the two streams. Extensive experiments on standard benchmarks such as FSC-147, CARPK, PUCPR+, and ShanghaiTech demonstrate our model's strong generalizability for zero-shot class-agnostic counting. Code is available at https://github.com/viscom-tongji/QUANet
Perception Activator: An intuitive and portable framework for brain cognitive exploration
Jul 03, 2025Recent advances in brain-vision decoding have driven significant progress, reconstructing with high fidelity perceived visual stimuli from neural activity, e.g., functional magnetic resonance imaging (fMRI), in the human visual cortex. Most existing methods decode the brain signal using a two-level strategy, i.e., pixel-level and semantic-level. However, these methods rely heavily on low-level pixel alignment yet lack sufficient and fine-grained semantic alignment, resulting in obvious reconstruction distortions of multiple semantic objects. To better understand the brain's visual perception patterns and how current decoding models process semantic objects, we have developed an experimental framework that uses fMRI representations as intervention conditions. By injecting these representations into multi-scale image features via cross-attention, we compare both downstream performance and intermediate feature changes on object detection and instance segmentation tasks with and without fMRI information. Our results demonstrate that incorporating fMRI signals enhances the accuracy of downstream detection and segmentation, confirming that fMRI contains rich multi-object semantic cues and coarse spatial localization information-elements that current models have yet to fully exploit or integrate.
Toward Rich Video Human-Motion2D Generation
Jun 17, 2025

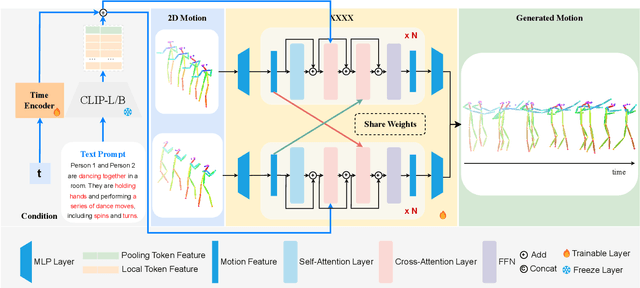

Generating realistic and controllable human motions, particularly those involving rich multi-character interactions, remains a significant challenge due to data scarcity and the complexities of modeling inter-personal dynamics. To address these limitations, we first introduce a new large-scale rich video human motion 2D dataset (Motion2D-Video-150K) comprising 150,000 video sequences. Motion2D-Video-150K features a balanced distribution of diverse single-character and, crucially, double-character interactive actions, each paired with detailed textual descriptions. Building upon this dataset, we propose a novel diffusion-based rich video human motion2D generation (RVHM2D) model. RVHM2D incorporates an enhanced textual conditioning mechanism utilizing either dual text encoders (CLIP-L/B) or T5-XXL with both global and local features. We devise a two-stage training strategy: the model is first trained with a standard diffusion objective, and then fine-tuned using reinforcement learning with an FID-based reward to further enhance motion realism and text alignment. Extensive experiments demonstrate that RVHM2D achieves leading performance on the Motion2D-Video-150K benchmark in generating both single and interactive double-character scenarios.
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025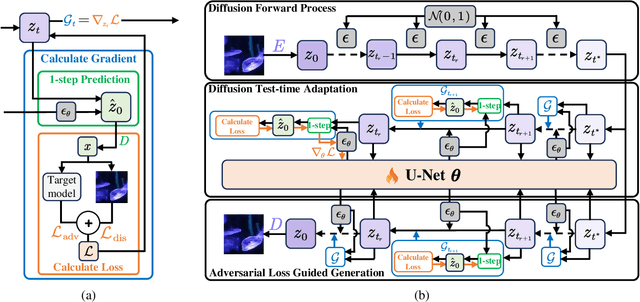
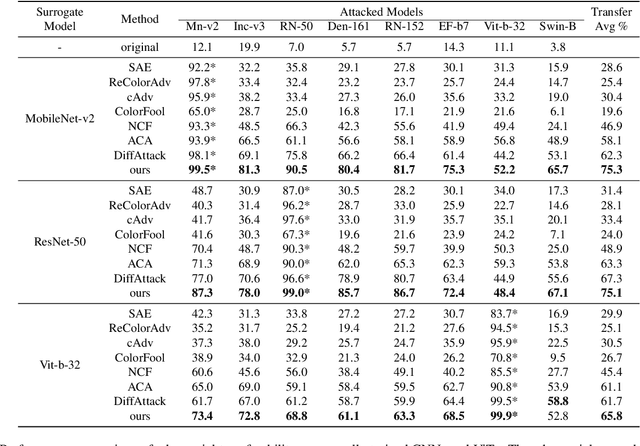
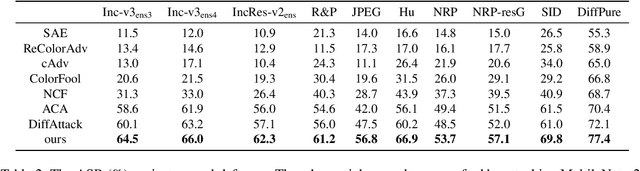

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.
Exploring Interpretability for Visual Prompt Tuning with Hierarchical Concepts
Mar 08, 2025Visual prompt tuning offers significant advantages for adapting pre-trained visual foundation models to specific tasks. However, current research provides limited insight into the interpretability of this approach, which is essential for enhancing AI reliability and enabling AI-driven knowledge discovery. In this paper, rather than learning abstract prompt embeddings, we propose the first framework, named Interpretable Visual Prompt Tuning (IVPT), to explore interpretability for visual prompts, by introducing hierarchical concept prototypes. Specifically, visual prompts are linked to human-understandable semantic concepts, represented as a set of category-agnostic prototypes, each corresponding to a specific region of the image. Then, IVPT aggregates features from these regions to generate interpretable prompts, which are structured hierarchically to explain visual prompts at different granularities. Comprehensive qualitative and quantitative evaluations on fine-grained classification benchmarks show its superior interpretability and performance over conventional visual prompt tuning methods and existing interpretable methods.