 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRL-SNAM: Geometric Reinforcement Learning with Path Differential Hamiltonians for Simultaneous Navigation and Mapping in Unknown Environments
Dec 31, 2025We present GRL-SNAM, a geometric reinforcement learning framework for Simultaneous Navigation and Mapping(SNAM) in unknown environments. A SNAM problem is challenging as it needs to design hierarchical or joint policies of multiple agents that control the movement of a real-life robot towards the goal in mapless environment, i.e. an environment where the map of the environment is not available apriori, and needs to be acquired through sensors. The sensors are invoked from the path learner, i.e. navigator, through active query responses to sensory agents, and along the motion path. GRL-SNAM differs from preemptive navigation algorithms and other reinforcement learning methods by relying exclusively on local sensory observations without constructing a global map. Our approach formulates path navigation and mapping as a dynamic shortest path search and discovery process using controlled Hamiltonian optimization: sensory inputs are translated into local energy landscapes that encode reachability, obstacle barriers, and deformation constraints, while policies for sensing, planning, and reconfiguration evolve stagewise via updating Hamiltonians. A reduced Hamiltonian serves as an adaptive score function, updating kinetic/potential terms, embedding barrier constraints, and continuously refining trajectories as new local information arrives. We evaluate GRL-SNAM on two different 2D navigation tasks. Comparing against local reactive baselines and global policy learning references under identical stagewise sensing constraints, it preserves clearance, generalizes to unseen layouts, and demonstrates that Geometric RL learning via updating Hamiltonians enables high-quality navigation through minimal exploration via local energy refinement rather than extensive global mapping. The code is publicly available on \href{https://github.com/CVC-Lab/GRL-SNAM}{Github}.
Learning Generalized Hamiltonian Dynamics with Stability from Noisy Trajectory Data
Sep 08, 2025We introduce a robust framework for learning various generalized Hamiltonian dynamics from noisy, sparse phase-space data and in an unsupervised manner based on variational Bayesian inference. Although conservative, dissipative, and port-Hamiltonian systems might share the same initial total energy of a closed system, it is challenging for a single Hamiltonian network model to capture the distinctive and varying motion dynamics and physics of a phase space, from sampled observational phase space trajectories. To address this complicated Hamiltonian manifold learning challenge, we extend sparse symplectic, random Fourier Gaussian processes learning with predictive successive numerical estimations of the Hamiltonian landscape, using a generalized form of state and conjugate momentum Hamiltonian dynamics, appropriate to different classes of conservative, dissipative and port-Hamiltonian physical systems. In addition to the kernelized evidence lower bound (ELBO) loss for data fidelity, we incorporate stability and conservation constraints as additional hyper-parameter balanced loss terms to regularize the model's multi-gradients, enforcing physics correctness for improved prediction accuracy with bounded uncertainty.
Self-Balancing, Memory Efficient, Dynamic Metric Space Data Maintenance, for Rapid Multi-Kernel Estimation
Apr 25, 2025We present a dynamic self-balancing octree data structure that enables efficient neighborhood maintenance in evolving metric spaces, a key challenge in modern machine learning systems. Many learning and generative models operate as dynamical systems whose representations evolve during training, requiring fast, adaptive spatial organization. Our two-parameter octree supports logarithmic-time updates and queries, eliminating the need for costly full rebuilds as data distributions shift. We demonstrate its effectiveness in four areas: (1) accelerating Stein variational gradient descent by supporting more particles with lower overhead; (2) enabling real-time, incremental KNN classification with logarithmic complexity; (3) facilitating efficient, dynamic indexing and retrieval for retrieval-augmented generation; and (4) improving sample efficiency by jointly optimizing input and latent spaces. Across all applications, our approach yields exponential speedups while preserving accuracy, particularly in high-dimensional spaces where maintaining adaptive spatial structure is critical.
Scalable Robust Bayesian Co-Clustering with Compositional ELBOs
Apr 08, 2025Co-clustering exploits the duality of instances and features to simultaneously uncover meaningful groups in both dimensions, often outperforming traditional clustering in high-dimensional or sparse data settings. Although recent deep learning approaches successfully integrate feature learning and cluster assignment, they remain susceptible to noise and can suffer from posterior collapse within standard autoencoders. In this paper, we present the first fully variational Co-clustering framework that directly learns row and column clusters in the latent space, leveraging a doubly reparameterized ELBO to improve gradient signal-to-noise separation. Our unsupervised model integrates a Variational Deep Embedding with a Gaussian Mixture Model (GMM) prior for both instances and features, providing a built-in clustering mechanism that naturally aligns latent modes with row and column clusters. Furthermore, our regularized end-to-end noise learning Compositional ELBO architecture jointly reconstructs the data while regularizing against noise through the KL divergence, thus gracefully handling corrupted or missing inputs in a single training pipeline. To counteract posterior collapse, we introduce a scale modification that increases the encoder's latent means only in the reconstruction pathway, preserving richer latent representations without inflating the KL term. Finally, a mutual information-based cross-loss ensures coherent co-clustering of rows and columns. Empirical results on diverse real-world datasets from multiple modalities, numerical, textual, and image-based, demonstrate that our method not only preserves the advantages of prior Co-clustering approaches but also exceeds them in accuracy and robustness, particularly in high-dimensional or noisy settings.
Low-cost Robust Night-time Aerial Material Segmentation through Hyperspectral Data and Sparse Spatio-Temporal Learning
Oct 19, 2024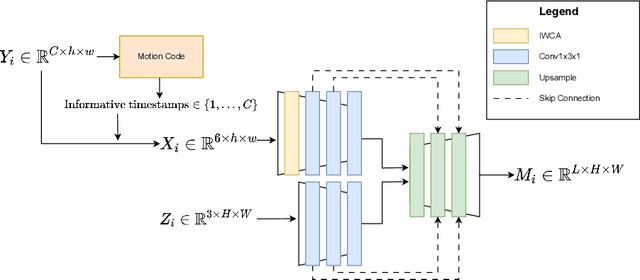



Material segmentation is a complex task, particularly when dealing with aerial data in poor lighting and atmospheric conditions. To address this, hyperspectral data from specialized cameras can be very useful in addition to RGB images. However, due to hardware constraints, high spectral data often come with lower spatial resolution. Additionally, incorporating such data into a learning-based segmentation framework is challenging due to the numerous data channels involved. To overcome these difficulties, we propose an innovative Siamese framework that uses time series-based compression to effectively and scalably integrate the additional spectral data into the segmentation task. We demonstrate our model's effectiveness through competitive benchmarks on aerial datasets in various environmental conditions.
4DRecons: 4D Neural Implicit Deformable Objects Reconstruction from a single RGB-D Camera with Geometrical and Topological Regularizations
Jun 14, 2024



This paper presents a novel approach 4DRecons that takes a single camera RGB-D sequence of a dynamic subject as input and outputs a complete textured deforming 3D model over time. 4DRecons encodes the output as a 4D neural implicit surface and presents an optimization procedure that combines a data term and two regularization terms. The data term fits the 4D implicit surface to the input partial observations. We address fundamental challenges in fitting a complete implicit surface to partial observations. The first regularization term enforces that the deformation among adjacent frames is as rigid as possible (ARAP). To this end, we introduce a novel approach to compute correspondences between adjacent textured implicit surfaces, which are used to define the ARAP regularization term. The second regularization term enforces that the topology of the underlying object remains fixed over time. This regularization is critical for avoiding self-intersections that are typical in implicit-based reconstructions. We have evaluated the performance of 4DRecons on a variety of datasets. Experimental results show that 4DRecons can handle large deformations and complex inter-part interactions and outperform state-of-the-art approaches considerably.
DPO: Differential reinforcement learning with application to optimal configuration search
Apr 24, 2024


Reinforcement learning (RL) with continuous state and action spaces remains one of the most challenging problems within the field. Most current learning methods focus on integral identities such as value functions to derive an optimal strategy for the learning agent. In this paper, we instead study the dual form of the original RL formulation to propose the first differential RL framework that can handle settings with limited training samples and short-length episodes. Our approach introduces Differential Policy Optimization (DPO), a pointwise and stage-wise iteration method that optimizes policies encoded by local-movement operators. We prove a pointwise convergence estimate for DPO and provide a regret bound comparable with current theoretical works. Such pointwise estimate ensures that the learned policy matches the optimal path uniformly across different steps. We then apply DPO to a class of practical RL problems which search for optimal configurations with Lagrangian rewards. DPO is easy to implement, scalable, and shows competitive results on benchmarking experiments against several popular RL methods.
Robust Learning of Noisy Time Series Collections Using Stochastic Process Models with Motion Codes
Feb 21, 2024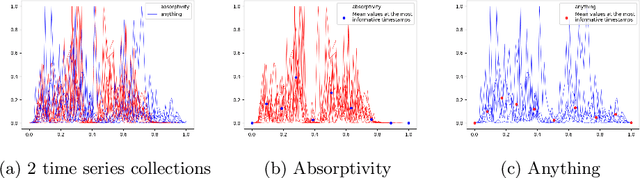
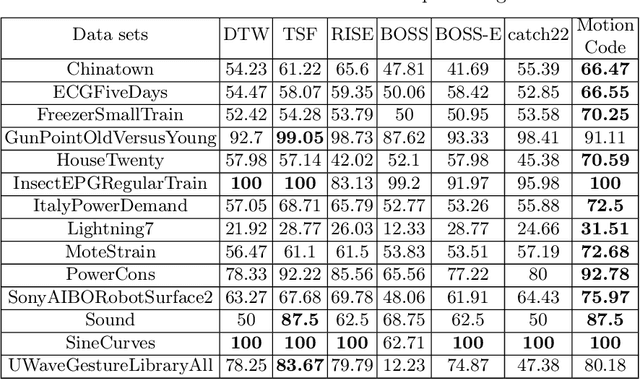
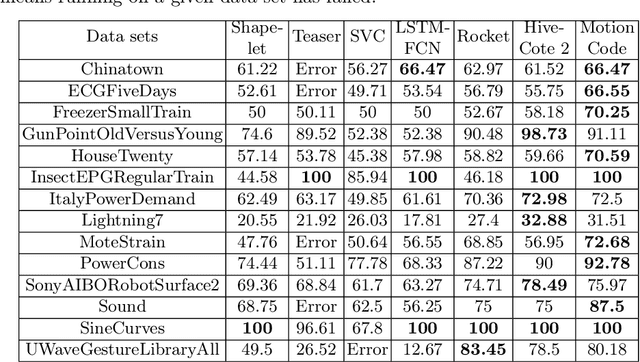
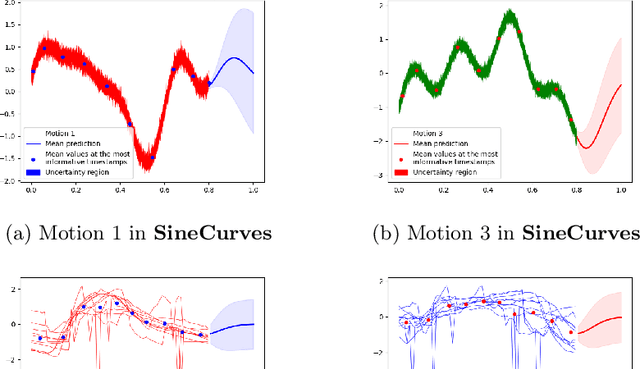
While time series classification and forecasting problems have been extensively studied, the cases of noisy time series data with arbitrary time sequence lengths have remained challenging. Each time series instance can be thought of as a sample realization of a noisy dynamical model, which is characterized by a continuous stochastic process. For many applications, the data are mixed and consist of several types of noisy time series sequences modeled by multiple stochastic processes, making the forecasting and classification tasks even more challenging. Instead of regressing data naively and individually to each time series type, we take a latent variable model approach using a mixtured Gaussian processes with learned spectral kernels. More specifically, we auto-assign each type of noisy time series data a signature vector called its motion code. Then, conditioned on each assigned motion code, we infer a sparse approximation of the corresponding time series using the concept of the most informative timestamps. Our unmixing classification approach involves maximizing the likelihood across all the mixed noisy time series sequences of varying lengths. This stochastic approach allows us to learn not only within a single type of noisy time series data but also across many underlying stochastic processes, giving us a way to learn multiple dynamical models in an integrated and robust manner. The different learned latent stochastic models allow us to generate specific sub-type forecasting. We provide several quantitative comparisons demonstrating the performance of our approach.
GenCorres: Consistent Shape Matching via Coupled Implicit-Explicit Shape Generative Models
Apr 20, 2023



This paper introduces GenCorres, a novel unsupervised joint shape matching (JSM) approach. The basic idea of GenCorres is to learn a parametric mesh generator to fit an unorganized deformable shape collection while constraining deformations between adjacent synthetic shapes to preserve geometric structures such as local rigidity and local conformality. GenCorres presents three appealing advantages over existing JSM techniques. First, GenCorres performs JSM among a synthetic shape collection whose size is much bigger than the input shapes and fully leverages the data-driven power of JSM. Second, GenCorres unifies consistent shape matching and pairwise matching (i.e., by enforcing deformation priors between adjacent synthetic shapes). Third, the generator provides a concise encoding of consistent shape correspondences. However, learning a mesh generator from an unorganized shape collection is challenging. It requires a good initial fitting to each shape and can easily get trapped by local minimums. GenCorres addresses this issue by learning an implicit generator from the input shapes, which provides intermediate shapes between two arbitrary shapes. We introduce a novel approach for computing correspondences between adjacent implicit surfaces and force the correspondences to preserve geometric structures and be cycle-consistent. Synthetic shapes of the implicit generator then guide initial fittings (i.e., via template-based deformation) for learning the mesh generator. Experimental results show that GenCorres considerably outperforms state-of-the-art JSM techniques on benchmark datasets. The synthetic shapes of GenCorres preserve local geometric features and yield competitive performance gains against state-of-the-art deformable shape generators.
DeblurSR: Event-Based Motion Deblurring Under the Spiking Representation
Mar 15, 2023

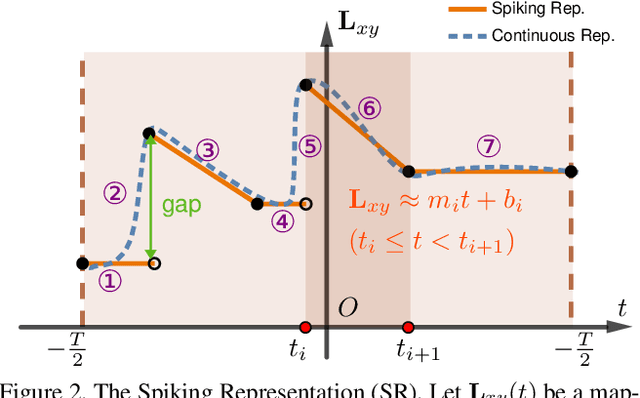

We present DeblurSR, a novel motion deblurring approach that converts a blurry image into a sharp video. DeblurSR utilizes event data to compensate for motion ambiguities and exploits the spiking representation to parameterize the sharp output video as a mapping from time to intensity. Our key contribution, the Spiking Representation (SR), is inspired by the neuromorphic principles determining how biological neurons communicate with each other in living organisms. We discuss why the spikes can represent sharp edges and how the spiking parameters are interpreted from the neuromorphic perspective. DeblurSR has higher output quality and requires fewer computing resources than state-of-the-art event-based motion deblurring methods. We additionally show that our approach easily extends to video super-resolution when combined with recent advances in implicit neural representation. The implementation and animated visualization of DeblurSR are available at https://github.com/chensong1995/DeblurSR.