 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Human-Like Manipulation through RL-Augmented Teleoperation and Mixture-of-Dexterous-Experts VLA
Mar 09, 2026While Vision-Language-Action (VLA) models have demonstrated remarkable success in robotic manipulation, their application has largely been confined to low-degree-of-freedom end-effectors performing simple, vision-guided pick-and-place tasks. Extending these models to human-like, bimanual dexterous manipulation-specifically contact-rich in-hand operations-introduces critical challenges in high-fidelity data acquisition, multi-skill learning, and multimodal sensory fusion. In this paper, we propose an integrated framework to address these bottlenecks, built upon two components. First, we introduce IMCopilot (In-hand Manipulation Copilot), a suite of reinforcement learning-trained atomic skills that plays a dual role: it acts as a shared-autonomy assistant to simplify teleoperation data collection, and it serves as a callable low-level execution primitive for the VLA. Second, we present MoDE-VLA (Mixture-of-Dexterous-Experts VLA), an architecture that seamlessly integrates heterogeneous force and tactile modalities into a pretrained VLA backbone. By utilizing a residual injection mechanism, MoDE-VLA enables contact-aware refinement without degrading the model's pretrained knowledge. We validate our approach on four tasks of escalating complexity, demonstrating doubled success rate improvement over the baseline in dexterous contact-rich tasks.
ManipulationNet: An Infrastructure for Benchmarking Real-World Robot Manipulation with Physical Skill Challenges and Embodied Multimodal Reasoning
Mar 04, 2026Dexterous manipulation enables robots to purposefully alter the physical world, transforming them from passive observers into active agents in unstructured environments. This capability is the cornerstone of physical artificial intelligence. Despite decades of advances in hardware, perception, control, and learning, progress toward general manipulation systems remains fragmented due to the absence of widely adopted standard benchmarks. The central challenge lies in reconciling the variability of the real world with the reproducibility and authenticity required for rigorous scientific evaluation. To address this, we introduce ManipulationNet, a global infrastructure that hosts real-world benchmark tasks for robotic manipulation. ManipulationNet delivers reproducible task setups through standardized hardware kits, and enables distributed performance evaluation via a unified software client that delivers real-time task instructions and collects benchmarking results. As a persistent and scalable infrastructure, ManipulationNet organizes benchmark tasks into two complementary tracks: 1) the Physical Skills Track, which evaluates low-level physical interaction skills, and 2) the Embodied Reasoning Track, which tests high-level reasoning and multimodal grounding abilities. This design fosters the systematic growth of an interconnected network of real-world abilities and skills, paving the path toward general robotic manipulation. By enabling comparable manipulation research in the real world at scale, this infrastructure establishes a sustainable foundation for measuring long-term scientific progress and identifying capabilities ready for real-world deployment.
Tacmap: Bridging the Tactile Sim-to-Real Gap via Geometry-Consistent Penetration Depth Map
Feb 25, 2026Vision-Based Tactile Sensors (VBTS) are essential for achieving dexterous robotic manipulation, yet the tactile sim-to-real gap remains a fundamental bottleneck. Current tactile simulations suffer from a persistent dilemma: simplified geometric projections lack physical authenticity, while high-fidelity Finite Element Methods (FEM) are too computationally prohibitive for large-scale reinforcement learning. In this work, we present Tacmap, a high-fidelity, computationally efficient tactile simulation framework anchored in volumetric penetration depth. Our key insight is to bridge the tactile sim-to-real gap by unifying both domains through a shared deform map representation. Specifically, we compute 3D intersection volumes as depth maps in simulation, while in the real world, we employ an automated data-collection rig to learn a robust mapping from raw tactile images to ground-truth depth maps. By aligning simulation and real-world in this unified geometric space, Tacmap minimizes domain shift while maintaining physical consistency. Quantitative evaluations across diverse contact scenarios demonstrate that Tacmap's deform maps closely mirror real-world measurements. Moreover, we validate the utility of Tacmap through an in-hand rotation task, where a policy trained exclusively in simulation achieves zero-shot transfer to a physical robot.
Optimization-Free Graph Embedding via Distributional Kernel for Community Detection
Feb 14, 2026Neighborhood Aggregation Strategy (NAS) is a widely used approach in graph embedding, underpinning both Graph Neural Networks (GNNs) and Weisfeiler-Lehman (WL) methods. However, NAS-based methods are identified to be prone to over-smoothing-the loss of node distinguishability with increased iterations-thereby limiting their effectiveness. This paper identifies two characteristics in a network, i.e., the distributions of nodes and node degrees that are critical for expressive representation but have been overlooked in existing methods. We show that these overlooked characteristics contribute significantly to over-smoothing of NAS-methods. To address this, we propose a novel weighted distribution-aware kernel that embeds nodes while taking their distributional characteristics into consideration. Our method has three distinguishing features: (1) it is the first method to explicitly incorporate both distributional characteristics; (2) it requires no optimization; and (3) it effectively mitigates the adverse effects of over-smoothing, allowing WL to preserve node distinguishability and expressiveness even after many iterations of embedding. Experiments demonstrate that our method achieves superior community detection performance via spectral clustering, outperforming existing graph embedding methods, including deep learning methods, on standard benchmarks.
Rethinking Divisive Hierarchical Clustering from a Distributional Perspective
Jan 27, 2026We uncover that current objective-based Divisive Hierarchical Clustering (DHC) methods produce a dendrogram that does not have three desired properties i.e., no unwarranted splitting, group similar clusters into a same subset, ground-truth correspondence. This shortcoming has their root cause in using a set-oriented bisecting assessment criterion. We show that this shortcoming can be addressed by using a distributional kernel, instead of the set-oriented criterion; and the resultant clusters achieve a new distribution-oriented objective to maximize the total similarity of all clusters (TSC). Our theoretical analysis shows that the resultant dendrogram guarantees a lower bound of TSC. The empirical evaluation shows the effectiveness of our proposed method on artificial and Spatial Transcriptomics (bioinformatics) datasets. Our proposed method successfully creates a dendrogram that is consistent with the biological regions in a Spatial Transcriptomics dataset, whereas other contenders fail.
Real-to-Sim Robot Policy Evaluation with Gaussian Splatting Simulation of Soft-Body Interactions
Nov 06, 2025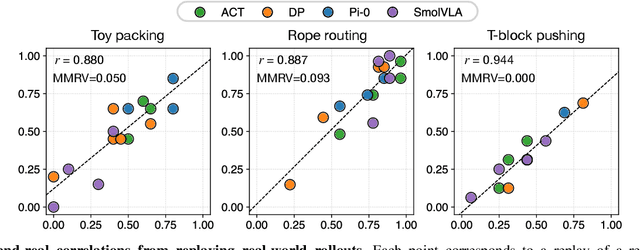

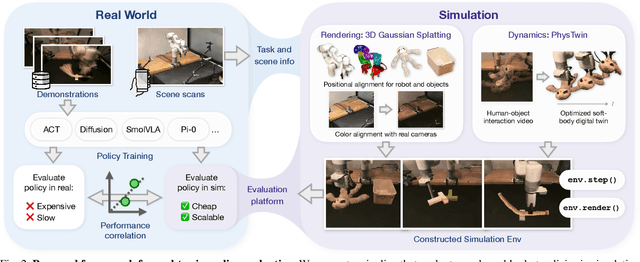
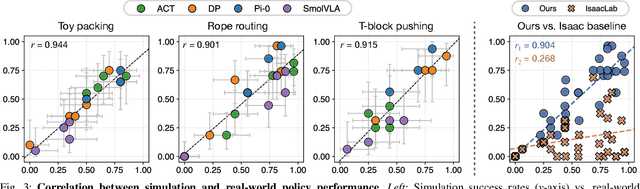
Robotic manipulation policies are advancing rapidly, but their direct evaluation in the real world remains costly, time-consuming, and difficult to reproduce, particularly for tasks involving deformable objects. Simulation provides a scalable and systematic alternative, yet existing simulators often fail to capture the coupled visual and physical complexity of soft-body interactions. We present a real-to-sim policy evaluation framework that constructs soft-body digital twins from real-world videos and renders robots, objects, and environments with photorealistic fidelity using 3D Gaussian Splatting. We validate our approach on representative deformable manipulation tasks, including plush toy packing, rope routing, and T-block pushing, demonstrating that simulated rollouts correlate strongly with real-world execution performance and reveal key behavioral patterns of learned policies. Our results suggest that combining physics-informed reconstruction with high-quality rendering enables reproducible, scalable, and accurate evaluation of robotic manipulation policies. Website: https://real2sim-eval.github.io/
Particle-Grid Neural Dynamics for Learning Deformable Object Models from RGB-D Videos
Jun 18, 2025Modeling the dynamics of deformable objects is challenging due to their diverse physical properties and the difficulty of estimating states from limited visual information. We address these challenges with a neural dynamics framework that combines object particles and spatial grids in a hybrid representation. Our particle-grid model captures global shape and motion information while predicting dense particle movements, enabling the modeling of objects with varied shapes and materials. Particles represent object shapes, while the spatial grid discretizes the 3D space to ensure spatial continuity and enhance learning efficiency. Coupled with Gaussian Splattings for visual rendering, our framework achieves a fully learning-based digital twin of deformable objects and generates 3D action-conditioned videos. Through experiments, we demonstrate that our model learns the dynamics of diverse objects -- such as ropes, cloths, stuffed animals, and paper bags -- from sparse-view RGB-D recordings of robot-object interactions, while also generalizing at the category level to unseen instances. Our approach outperforms state-of-the-art learning-based and physics-based simulators, particularly in scenarios with limited camera views. Furthermore, we showcase the utility of our learned models in model-based planning, enabling goal-conditioned object manipulation across a range of tasks. The project page is available at https://kywind.github.io/pgnd .
Dynamic 3D Gaussian Tracking for Graph-Based Neural Dynamics Modeling
Oct 24, 2024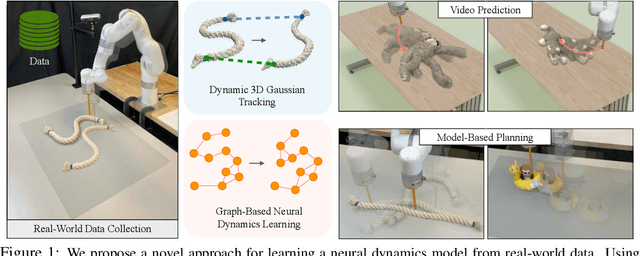

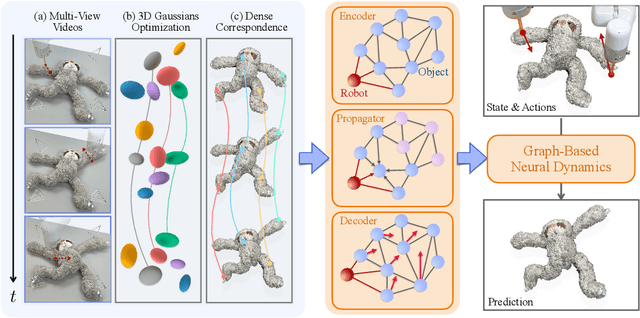

Videos of robots interacting with objects encode rich information about the objects' dynamics. However, existing video prediction approaches typically do not explicitly account for the 3D information from videos, such as robot actions and objects' 3D states, limiting their use in real-world robotic applications. In this work, we introduce a framework to learn object dynamics directly from multi-view RGB videos by explicitly considering the robot's action trajectories and their effects on scene dynamics. We utilize the 3D Gaussian representation of 3D Gaussian Splatting (3DGS) to train a particle-based dynamics model using Graph Neural Networks. This model operates on sparse control particles downsampled from the densely tracked 3D Gaussian reconstructions. By learning the neural dynamics model on offline robot interaction data, our method can predict object motions under varying initial configurations and unseen robot actions. The 3D transformations of Gaussians can be interpolated from the motions of control particles, enabling the rendering of predicted future object states and achieving action-conditioned video prediction. The dynamics model can also be applied to model-based planning frameworks for object manipulation tasks. We conduct experiments on various kinds of deformable materials, including ropes, clothes, and stuffed animals, demonstrating our framework's ability to model complex shapes and dynamics. Our project page is available at https://gs-dynamics.github.io.
AdaptiGraph: Material-Adaptive Graph-Based Neural Dynamics for Robotic Manipulation
Jul 10, 2024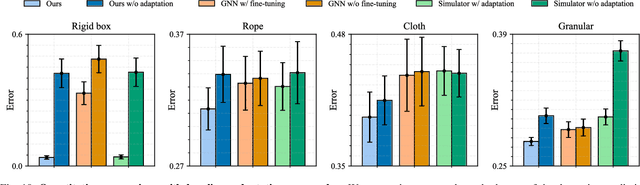
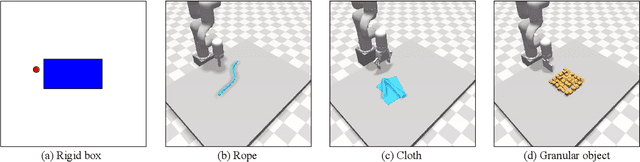
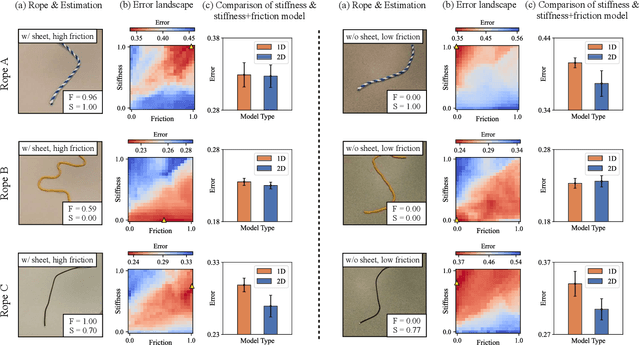
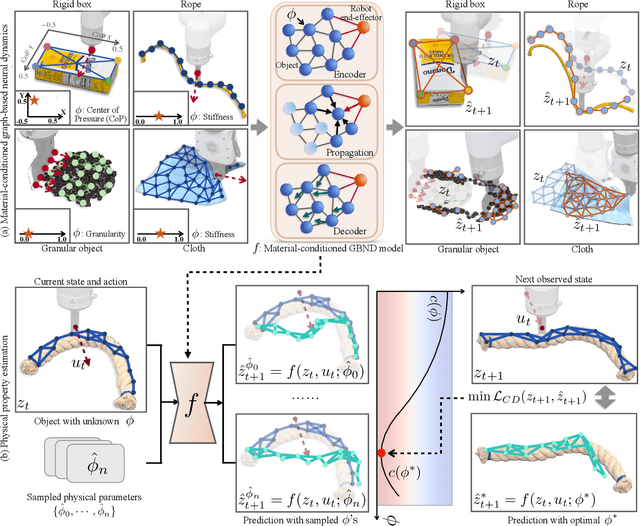
Predictive models are a crucial component of many robotic systems. Yet, constructing accurate predictive models for a variety of deformable objects, especially those with unknown physical properties, remains a significant challenge. This paper introduces AdaptiGraph, a learning-based dynamics modeling approach that enables robots to predict, adapt to, and control a wide array of challenging deformable materials with unknown physical properties. AdaptiGraph leverages the highly flexible graph-based neural dynamics (GBND) framework, which represents material bits as particles and employs a graph neural network (GNN) to predict particle motion. Its key innovation is a unified physical property-conditioned GBND model capable of predicting the motions of diverse materials with varying physical properties without retraining. Upon encountering new materials during online deployment, AdaptiGraph utilizes a physical property optimization process for a few-shot adaptation of the model, enhancing its fit to the observed interaction data. The adapted models can precisely simulate the dynamics and predict the motion of various deformable materials, such as ropes, granular media, rigid boxes, and cloth, while adapting to different physical properties, including stiffness, granular size, and center of pressure. On prediction and manipulation tasks involving a diverse set of real-world deformable objects, our method exhibits superior prediction accuracy and task proficiency over non-material-conditioned and non-adaptive models. The project page is available at https://robopil.github.io/adaptigraph/ .
4DRecons: 4D Neural Implicit Deformable Objects Reconstruction from a single RGB-D Camera with Geometrical and Topological Regularizations
Jun 14, 2024



This paper presents a novel approach 4DRecons that takes a single camera RGB-D sequence of a dynamic subject as input and outputs a complete textured deforming 3D model over time. 4DRecons encodes the output as a 4D neural implicit surface and presents an optimization procedure that combines a data term and two regularization terms. The data term fits the 4D implicit surface to the input partial observations. We address fundamental challenges in fitting a complete implicit surface to partial observations. The first regularization term enforces that the deformation among adjacent frames is as rigid as possible (ARAP). To this end, we introduce a novel approach to compute correspondences between adjacent textured implicit surfaces, which are used to define the ARAP regularization term. The second regularization term enforces that the topology of the underlying object remains fixed over time. This regularization is critical for avoiding self-intersections that are typical in implicit-based reconstructions. We have evaluated the performance of 4DRecons on a variety of datasets. Experimental results show that 4DRecons can handle large deformations and complex inter-part interactions and outperform state-of-the-art approaches considerably.