 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Encoding Adversarial Imitation Learning
Paper and Code
Jun 22, 2022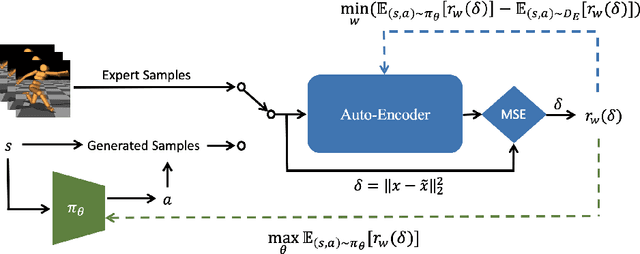
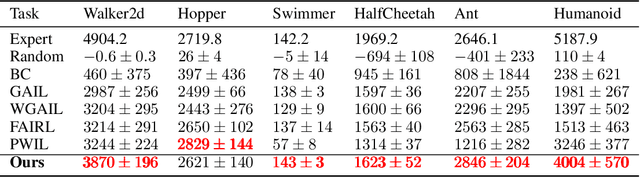
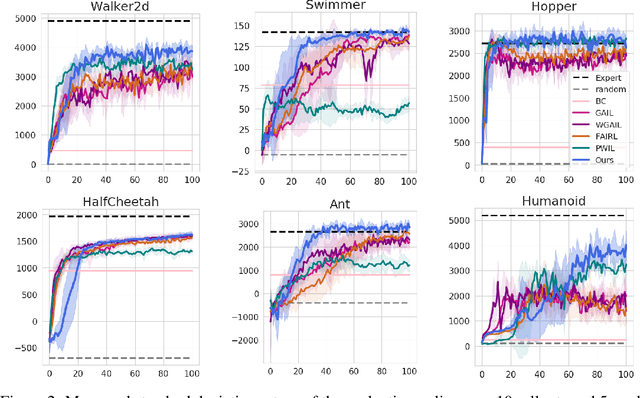

Reinforcement learning (RL) provides a powerful framework for decision-making, but its application in practice often requires a carefully designed reward function. Adversarial Imitation Learning (AIL) sheds light on automatic policy acquisition without access to the reward signal from the environment. In this work, we propose Auto-Encoding Adversarial Imitation Learning (AEAIL), a robust and scalable AIL framework. To induce expert policies from demonstrations, AEAIL utilizes the reconstruction error of an auto-encoder as a reward signal, which provides more information for optimizing policies than the prior discriminator-based ones. Subsequently, we use the derived objective functions to train the auto-encoder and the agent policy. Experiments show that our AEAIL performs superior compared to state-of-the-art methods in the MuJoCo environments. More importantly, AEAIL shows much better robustness when the expert demonstrations are noisy. Specifically, our method achieves $16.4\%$ and $47.2\%$ relative improvement overall compared to the best baseline FAIRL and PWIL on clean and noisy expert data, respectively. Video results, open-source code and dataset are available in https://sites.google.com/view/auto-encoding-imitation.