 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveTok: 3D Driving Scene Tokenization for Unified Multi-View Reconstruction and Understanding
Mar 19, 2026With the growing adoption of vision-language-action models and world models in autonomous driving systems, scalable image tokenization becomes crucial as the interface for the visual modality. However, most existing tokenizers are designed for monocular and 2D scenes, leading to inefficiency and inter-view inconsistency when applied to high-resolution multi-view driving scenes. To address this, we propose DriveTok, an efficient 3D driving scene tokenizer for unified multi-view reconstruction and understanding. DriveTok first obtains semantically rich visual features from vision foundation models and then transforms them into the scene tokens with 3D deformable cross-attention. For decoding, we employ a multi-view transformer to reconstruct multi-view features from the scene tokens and use multiple heads to obtain RGB, depth, and semantic reconstructions. We also add a 3D head directly on the scene tokens for 3D semantic occupancy prediction for better spatial awareness. With the multiple training objectives, DriveTok learns unified scene tokens that integrate semantic, geometric, and textural information for efficient multi-view tokenization. Extensive experiments on the widely used nuScenes dataset demonstrate that the scene tokens from DriveTok perform well on image reconstruction, semantic segmentation, depth prediction, and 3D occupancy prediction tasks.
DrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
Dec 14, 2025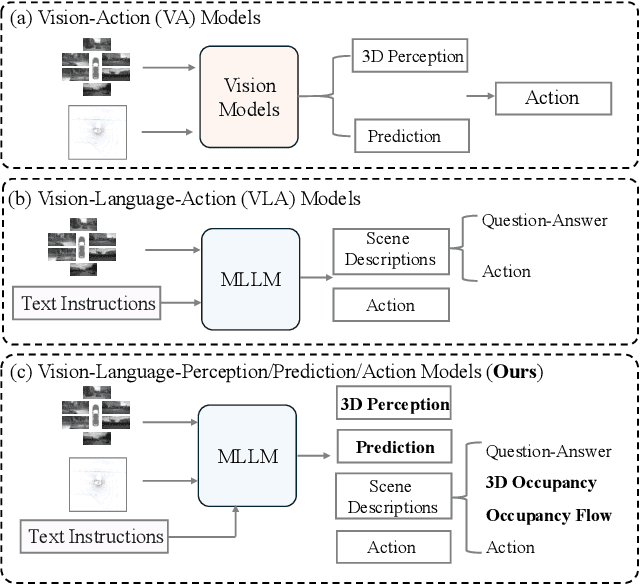
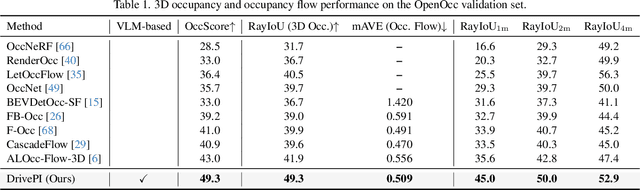
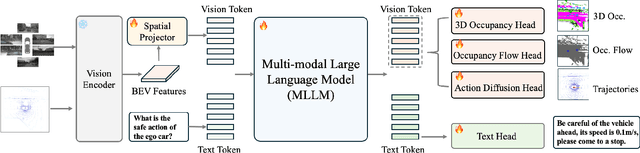
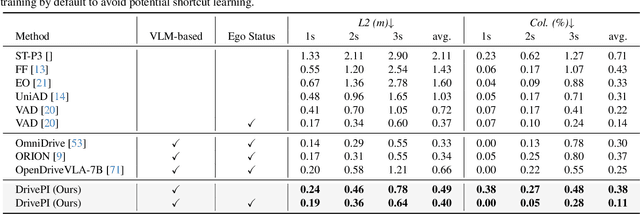
Although multi-modal large language models (MLLMs) have shown strong capabilities across diverse domains, their application in generating fine-grained 3D perception and prediction outputs in autonomous driving remains underexplored. In this paper, we propose DrivePI, a novel spatial-aware 4D MLLM that serves as a unified Vision-Language-Action (VLA) framework that is also compatible with vision-action (VA) models. Our method jointly performs spatial understanding, 3D perception (i.e., 3D occupancy), prediction (i.e., occupancy flow), and planning (i.e., action outputs) in parallel through end-to-end optimization. To obtain both precise geometric information and rich visual appearance, our approach integrates point clouds, multi-view images, and language instructions within a unified MLLM architecture. We further develop a data engine to generate text-occupancy and text-flow QA pairs for 4D spatial understanding. Remarkably, with only a 0.5B Qwen2.5 model as MLLM backbone, DrivePI as a single unified model matches or exceeds both existing VLA models and specialized VA models. Specifically, compared to VLA models, DrivePI outperforms OpenDriveVLA-7B by 2.5% mean accuracy on nuScenes-QA and reduces collision rate by 70% over ORION (from 0.37% to 0.11%) on nuScenes. Against specialized VA models, DrivePI surpasses FB-OCC by 10.3 RayIoU for 3D occupancy on OpenOcc, reduces the mAVE from 0.591 to 0.509 for occupancy flow on OpenOcc, and achieves 32% lower L2 error than VAD (from 0.72m to 0.49m) for planning on nuScenes. Code will be available at https://github.com/happinesslz/DrivePI
Wavelet-based Decoupling Framework for low-light Stereo Image Enhancement
Jul 16, 2025



Low-light images suffer from complex degradation, and existing enhancement methods often encode all degradation factors within a single latent space. This leads to highly entangled features and strong black-box characteristics, making the model prone to shortcut learning. To mitigate the above issues, this paper proposes a wavelet-based low-light stereo image enhancement method with feature space decoupling. Our insight comes from the following findings: (1) Wavelet transform enables the independent processing of low-frequency and high-frequency information. (2) Illumination adjustment can be achieved by adjusting the low-frequency component of a low-light image, extracted through multi-level wavelet decomposition. Thus, by using wavelet transform the feature space is decomposed into a low-frequency branch for illumination adjustment and multiple high-frequency branches for texture enhancement. Additionally, stereo low-light image enhancement can extract useful cues from another view to improve enhancement. To this end, we propose a novel high-frequency guided cross-view interaction module (HF-CIM) that operates within high-frequency branches rather than across the entire feature space, effectively extracting valuable image details from the other view. Furthermore, to enhance the high-frequency information, a detail and texture enhancement module (DTEM) is proposed based on cross-attention mechanism. The model is trained on a dataset consisting of images with uniform illumination and images with non-uniform illumination. Experimental results on both real and synthetic images indicate that our algorithm offers significant advantages in light adjustment while effectively recovering high-frequency information. The code and dataset are publicly available at: https://github.com/Cherisherr/WDCI-Net.git.
ViGoR: Improving Visual Grounding of Large Vision Language Models with Fine-Grained Reward Modeling
Feb 09, 2024



By combining natural language understanding and the generation capabilities and breadth of knowledge of large language models with image perception, recent large vision language models (LVLMs) have shown unprecedented reasoning capabilities in the real world. However, the generated text often suffers from inaccurate grounding in the visual input, resulting in errors such as hallucinating nonexistent scene elements, missing significant parts of the scene, and inferring incorrect attributes and relationships between objects. To address these issues, we introduce a novel framework, ViGoR (Visual Grounding Through Fine-Grained Reward Modeling) that utilizes fine-grained reward modeling to significantly enhance the visual grounding of LVLMs over pre-trained baselines. This improvement is efficiently achieved using much cheaper human evaluations instead of full supervisions, as well as automated methods. We show the effectiveness of our approach through numerous metrics on several benchmarks. Additionally, we construct a comprehensive and challenging dataset specifically designed to validate the visual grounding capabilities of LVLMs. Finally, we plan to release our human annotation comprising approximately 16,000 images and generated text pairs with fine-grained evaluations to contribute to related research in the community.
Learning from Multi-View Representation for Point-Cloud Pre-Training
Jun 05, 2023



A critical problem in the pre-training of 3D point clouds is leveraging massive 2D data. A fundamental challenge is to address the 2D-3D domain gap. This paper proposes a novel approach to point-cloud pre-training that enables learning 3D representations by leveraging pre-trained 2D-based networks. In particular, it avoids overfitting to 2D representations and potentially discarding critical 3D features for 3D recognition tasks. The key to our approach is a novel multi-view representation, which learns a shared 3D feature volume consistent with deep features extracted from multiple 2D camera views. The 2D deep features are regularized using pre-trained 2D networks through the 2D knowledge transfer loss. To prevent the resulting 3D feature representations from discarding 3D signals, we introduce the multi-view consistency loss that forces the projected 2D feature representations to capture pixel-wise correspondences across different views. Such correspondences induce 3D geometry and effectively retain 3D features in the projected 2D features. Experimental results demonstrate that our pre-trained model can be successfully transferred to various downstream tasks, including 3D detection and semantic segmentation, and achieve state-of-the-art performance.
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Apr 14, 2023



Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.
Implicit Autoencoder for Point Cloud Self-supervised Representation Learning
Jan 03, 2022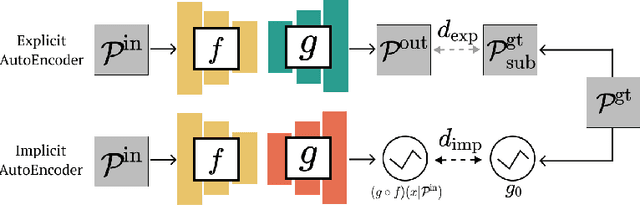
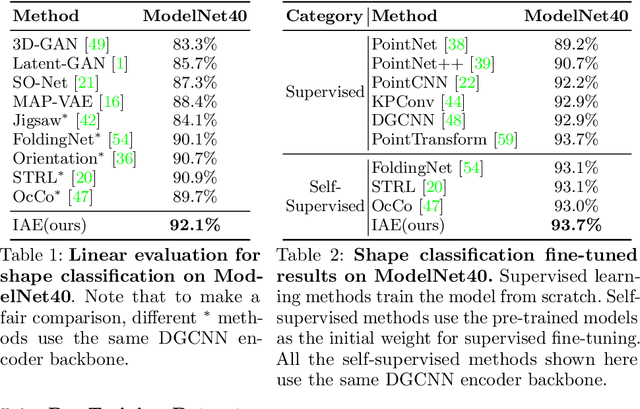
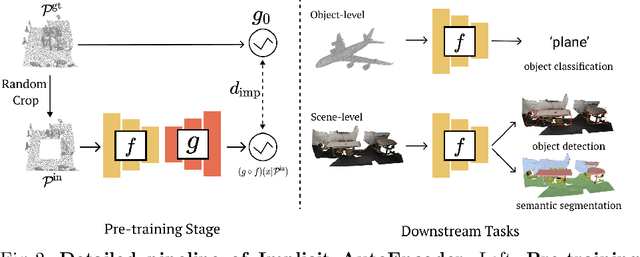

Many 3D representations (e.g., point clouds) are discrete samples of the underlying continuous 3D surface. This process inevitably introduces sampling variations on the underlying 3D shapes. In learning 3D representation, the variations should be disregarded while transferable knowledge of the underlying 3D shape should be captured. This becomes a grand challenge in existing representation learning paradigms. This paper studies autoencoding on point clouds. The standard autoencoding paradigm forces the encoder to capture such sampling variations as the decoder has to reconstruct the original point cloud that has sampling variations. We introduce Implicit Autoencoder(IAE), a simple yet effective method that addresses this challenge by replacing the point cloud decoder with an implicit decoder. The implicit decoder outputs a continuous representation that is shared among different point cloud sampling of the same model. Reconstructing under the implicit representation can prioritize that the encoder discards sampling variations, introducing more space to learn useful features. We theoretically justify this claim under a simple linear autoencoder. Moreover, the implicit decoder offers a rich space to design suitable implicit representations for different tasks. We demonstrate the usefulness of IAE across various self-supervised learning tasks for both 3D objects and 3D scenes. Experimental results show that IAE consistently outperforms the state-of-the-art in each task.
Scene Synthesis via Uncertainty-Driven Attribute Synchronization
Sep 01, 2021
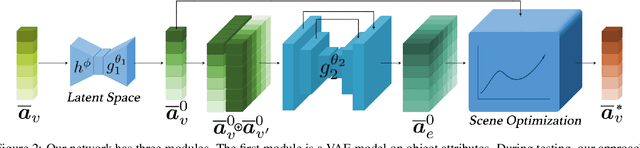


Developing deep neural networks to generate 3D scenes is a fundamental problem in neural synthesis with immediate applications in architectural CAD, computer graphics, as well as in generating virtual robot training environments. This task is challenging because 3D scenes exhibit diverse patterns, ranging from continuous ones, such as object sizes and the relative poses between pairs of shapes, to discrete patterns, such as occurrence and co-occurrence of objects with symmetrical relationships. This paper introduces a novel neural scene synthesis approach that can capture diverse feature patterns of 3D scenes. Our method combines the strength of both neural network-based and conventional scene synthesis approaches. We use the parametric prior distributions learned from training data, which provide uncertainties of object attributes and relative attributes, to regularize the outputs of feed-forward neural models. Moreover, instead of merely predicting a scene layout, our approach predicts an over-complete set of attributes. This methodology allows us to utilize the underlying consistency constraints among the predicted attributes to prune infeasible predictions. Experimental results show that our approach outperforms existing methods considerably. The generated 3D scenes interpolate the training data faithfully while preserving both continuous and discrete feature patterns.
HPNet: Deep Primitive Segmentation Using Hybrid Representations
May 22, 2021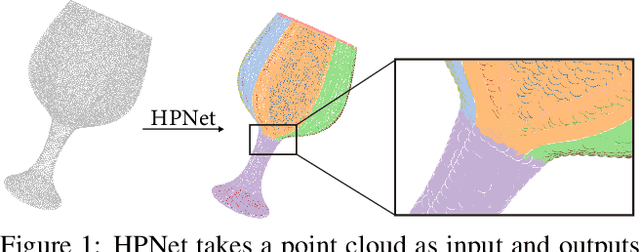

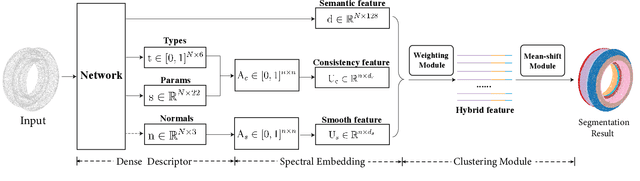
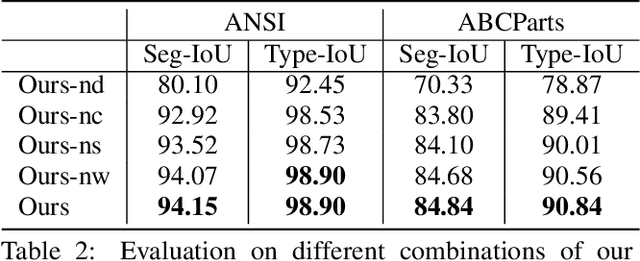
This paper introduces HPNet, a novel deep-learning approach for segmenting a 3D shape represented as a point cloud into primitive patches. The key to deep primitive segmentation is learning a feature representation that can separate points of different primitives. Unlike utilizing a single feature representation, HPNet leverages hybrid representations that combine one learned semantic descriptor, two spectral descriptors derived from predicted geometric parameters, as well as an adjacency matrix that encodes sharp edges. Moreover, instead of merely concatenating the descriptors, HPNet optimally combines hybrid representations by learning combination weights. This weighting module builds on the entropy of input features. The output primitive segmentation is obtained from a mean-shift clustering module. Experimental results on benchmark datasets ANSI and ABCParts show that HPNet leads to significant performance gains from baseline approaches.
Extreme Relative Pose Network under Hybrid Representations
Dec 25, 2019
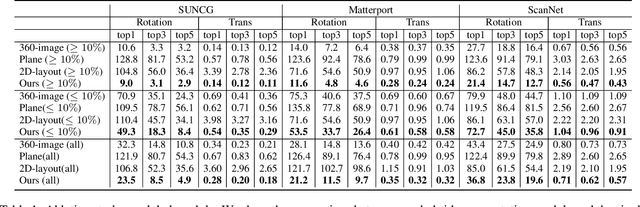
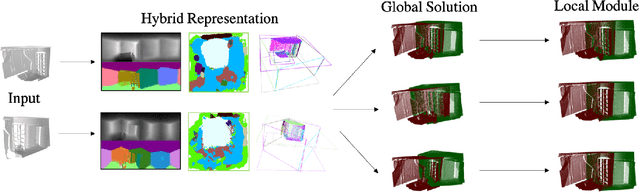

In this paper, we introduce a novel RGB-D based relative pose estimation approach that is suitable for small-overlapping or non-overlapping scans and can output multiple relative poses. Our method performs scene completion and matches the completed scans. However, instead of using a fixed representation for completion, the key idea is to utilize hybrid representations that combine 360-image, 2D image-based layout, and planar patches. This approach offers adaptively feature representations for relative pose estimation. Besides, we introduce a global-2-local matching procedure, which utilizes initial relative poses obtained during the global phase to detect and then integrate geometric relations for pose refinement. Experimental results justify the potential of this approach across a wide range of benchmark datasets. For example, on ScanNet, the rotation translation errors of the top-1/top-5 predictions of our approach are 34.9/0.69m and 19.6/0.57m, respectively. Our approach also considerably boosts the performance of multi-scan reconstruction in few-view reconstruction settings.