 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hyperparameter Optimization for LLM Reinforcement Learning
Jun 02, 2026Reinforcement learning (RL) for large language models (LLMs) is highly sensitive to hyperparameter configurations, making hyperparameter optimization (HPO) essential yet computationally expensive. Existing multi-fidelity HPO methods remain inefficient for LLM RL due to the massive model scale and resource-intensive training cycles. In this paper, we propose Joint Fidelity Hyperparameter Optimization (JF-HPO), which simultaneously adapts both model size and training budget as fidelity. JF-HPO is empowered by: (i) it leverages a small proxy model of the target LLM for efficient training and evaluation in each HPO trial; (ii) it integrates carefully designed early-stopping strategies based on training dynamics; (iii) it introduces an efficient checkpointing mechanism to eliminate redundant computations. Compared with existing HPO methods, JF-HPO significantly improves the computational efficiency of each trial (up to 14.9 times), while achieving better or competitive predictive accuracy under the same time budget. Notably, compared with utilizing hyperparameter configurations from the VeRL Recipe, JF-HPO delivers performance improvements ranging from 5.8% to 111.6%.
AgentSentry: Mitigating Indirect Prompt Injection in LLM Agents via Temporal Causal Diagnostics and Context Purification
Feb 26, 2026Large language model (LLM) agents increasingly rely on external tools and retrieval systems to autonomously complete complex tasks. However, this design exposes agents to indirect prompt injection (IPI), where attacker-controlled context embedded in tool outputs or retrieved content silently steers agent actions away from user intent. Unlike prompt-based attacks, IPI unfolds over multi-turn trajectories, making malicious control difficult to disentangle from legitimate task execution. Existing inference-time defenses primarily rely on heuristic detection and conservative blocking of high-risk actions, which can prematurely terminate workflows or broadly suppress tool usage under ambiguous multi-turn scenarios. We propose AgentSentry, a novel inference-time detection and mitigation framework for tool-augmented LLM agents. To the best of our knowledge, AgentSentry is the first inference-time defense to model multi-turn IPI as a temporal causal takeover. It localizes takeover points via controlled counterfactual re-executions at tool-return boundaries and enables safe continuation through causally guided context purification that removes attack-induced deviations while preserving task-relevant evidence. We evaluate AgentSentry on the \textsc{AgentDojo} benchmark across four task suites, three IPI attack families, and multiple black-box LLMs. AgentSentry eliminates successful attacks and maintains strong utility under attack, achieving an average Utility Under Attack (UA) of 74.55 %, improving UA by 20.8 to 33.6 percentage points over the strongest baselines without degrading benign performance.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
FoldNet: Learning Generalizable Closed-Loop Policy for Garment Folding via Keypoint-Driven Asset and Demonstration Synthesis
May 14, 2025



Due to the deformability of garments, generating a large amount of high-quality data for robotic garment manipulation tasks is highly challenging. In this paper, we present a synthetic garment dataset that can be used for robotic garment folding. We begin by constructing geometric garment templates based on keypoints and applying generative models to generate realistic texture patterns. Leveraging these keypoint annotations, we generate folding demonstrations in simulation and train folding policies via closed-loop imitation learning. To improve robustness, we propose KG-DAgger, which uses a keypoint-based strategy to generate demonstration data for recovering from failures. KG-DAgger significantly improves the model performance, boosting the real-world success rate by 25\%. After training with 15K trajectories (about 2M image-action pairs), the model achieves a 75\% success rate in the real world. Experiments in both simulation and real-world settings validate the effectiveness of our proposed framework.
RoboHanger: Learning Generalizable Robotic Hanger Insertion for Diverse Garments
Dec 02, 2024



For the task of hanging clothes, learning how to insert a hanger into a garment is crucial but has been seldom explored in robotics. In this work, we address the problem of inserting a hanger into various unseen garments that are initially laid out flat on a table. This task is challenging due to its long-horizon nature, the high degrees of freedom of the garments, and the lack of data. To simplify the learning process, we first propose breaking the task into several stages. Then, we formulate each stage as a policy learning problem and propose low-dimensional action parameterization. To overcome the challenge of limited data, we build our own simulator and create 144 synthetic clothing assets to effectively collect high-quality training data. Our approach uses single-view depth images and object masks as input, which mitigates the Sim2Real appearance gap and achieves high generalization capabilities for new garments. Extensive experiments in both simulation and the real world validate our proposed method. By training on various garments in the simulator, our method achieves a 75\% success rate with 8 different unseen garments in the real world.
FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance
Nov 19, 2020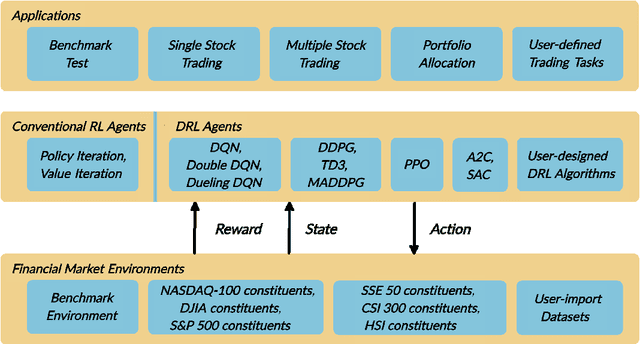
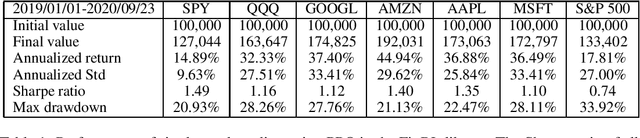
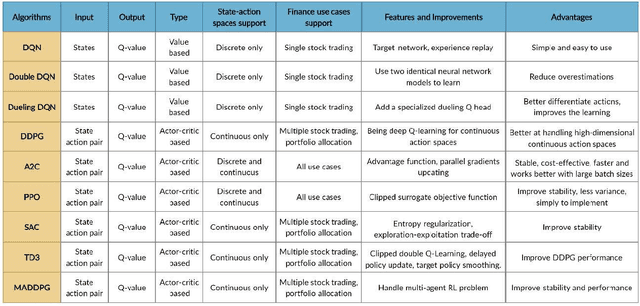
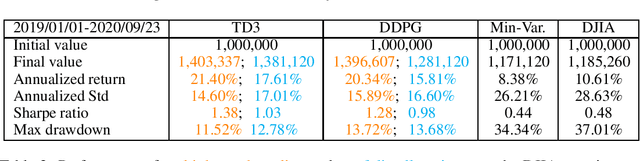
As deep reinforcement learning (DRL) has been recognized as an effective approach in quantitative finance, getting hands-on experiences is attractive to beginners. However, to train a practical DRL trading agent that decides where to trade, at what price, and what quantity involves error-prone and arduous development and debugging. In this paper, we introduce a DRL library FinRL that facilitates beginners to expose themselves to quantitative finance and to develop their own stock trading strategies. Along with easily-reproducible tutorials, FinRL library allows users to streamline their own developments and to compare with existing schemes easily. Within FinRL, virtual environments are configured with stock market datasets, trading agents are trained with neural networks, and extensive backtesting is analyzed via trading performance. Moreover, it incorporates important trading constraints such as transaction cost, market liquidity and the investor's degree of risk-aversion. FinRL is featured with completeness, hands-on tutorial and reproducibility that favors beginners: (i) at multiple levels of time granularity, FinRL simulates trading environments across various stock markets, including NASDAQ-100, DJIA, S&P 500, HSI, SSE 50, and CSI 300; (ii) organized in a layered architecture with modular structure, FinRL provides fine-tuned state-of-the-art DRL algorithms (DQN, DDPG, PPO, SAC, A2C, TD3, etc.), commonly-used reward functions and standard evaluation baselines to alleviate the debugging workloads and promote the reproducibility, and (iii) being highly extendable, FinRL reserves a complete set of user-import interfaces. Furthermore, we incorporated three application demonstrations, namely single stock trading, multiple stock trading, and portfolio allocation. The FinRL library will be available on Github at link https://github.com/AI4Finance-LLC/FinRL-Library.
Recurrent Feedback Improves Feedforward Representations in Deep Neural Networks
Dec 22, 2019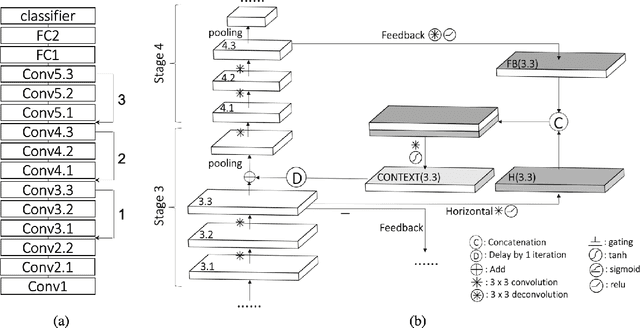


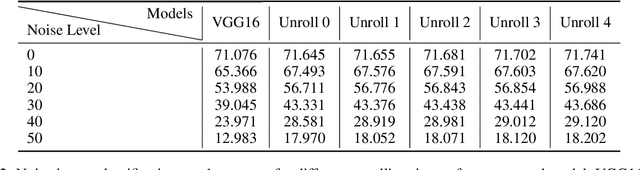
The abundant recurrent horizontal and feedback connections in the primate visual cortex are thought to play an important role in bringing global and semantic contextual information to early visual areas during perceptual inference, helping to resolve local ambiguity and fill in missing details. In this study, we find that introducing feedback loops and horizontal recurrent connections to a deep convolution neural network (VGG16) allows the network to become more robust against noise and occlusion during inference, even in the initial feedforward pass. This suggests that recurrent feedback and contextual modulation transform the feedforward representations of the network in a meaningful and interesting way. We study the population codes of neurons in the network, before and after learning with feedback, and find that learning with feedback yielded an increase in discriminability (measured by d-prime) between the different object classes in the population codes of the neurons in the feedforward path, even at the earliest layer that receives feedback. We find that recurrent feedback, by injecting top-down semantic meaning to the population activities, helps the network learn better feedforward paths to robustly map noisy image patches to the latent representations corresponding to important visual concepts of each object class, resulting in greater robustness of the network against noises and occlusion as well as better fine-grained recognition.