 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Animal Identification for Long Videos
Jan 14, 2026Identifying individual animals in long-duration videos is essential for behavioral ecology, wildlife monitoring, and livestock management. Traditional methods require extensive manual annotation, while existing self-supervised approaches are computationally demanding and ill-suited for long sequences due to memory constraints and temporal error propagation. We introduce a highly efficient, self-supervised method that reframes animal identification as a global clustering task rather than a sequential tracking problem. Our approach assumes a known, fixed number of individuals within a single video -- a common scenario in practice -- and requires only bounding box detections and the total count. By sampling pairs of frames, using a frozen pre-trained backbone, and employing a self-bootstrapping mechanism with the Hungarian algorithm for in-batch pseudo-label assignment, our method learns discriminative features without identity labels. We adapt a Binary Cross Entropy loss from vision-language models, enabling state-of-the-art accuracy ($>$97\%) while consuming less than 1 GB of GPU memory per batch -- an order of magnitude less than standard contrastive methods. Evaluated on challenging real-world datasets (3D-POP pigeons and 8-calves feeding videos), our framework matches or surpasses supervised baselines trained on over 1,000 labeled frames, effectively removing the manual annotation bottleneck. This work enables practical, high-accuracy animal identification on consumer-grade hardware, with broad applicability in resource-constrained research settings. All code written for this paper are \href{https://huggingface.co/datasets/tonyFang04/8-calves}{here}.
8-Calves Image dataset
Mar 17, 2025
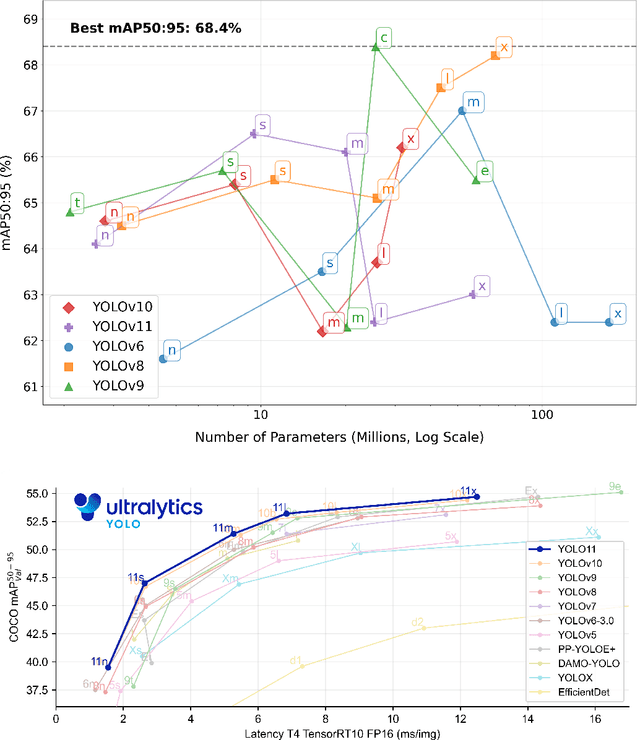
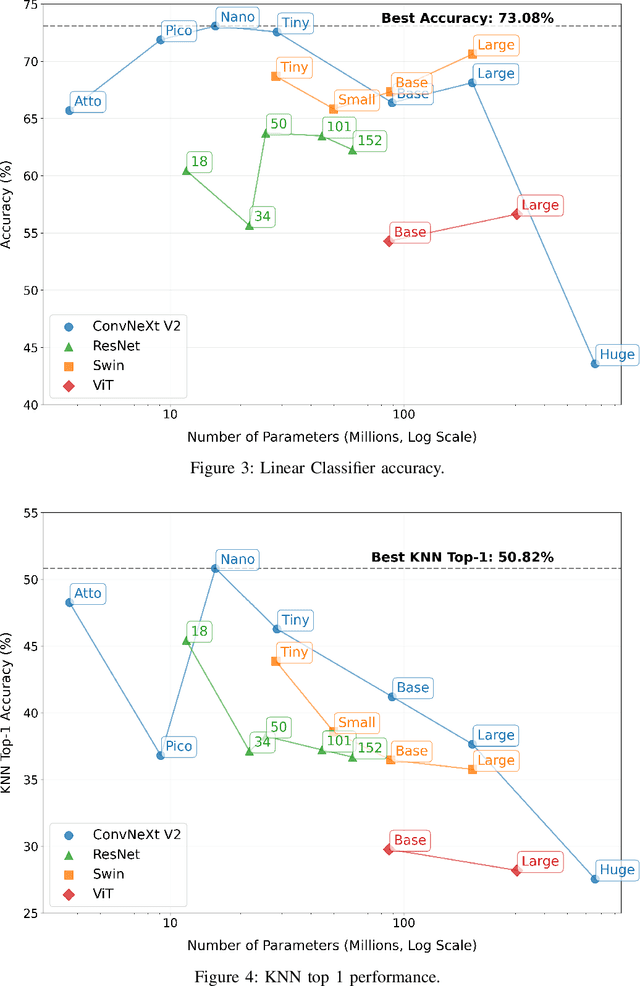
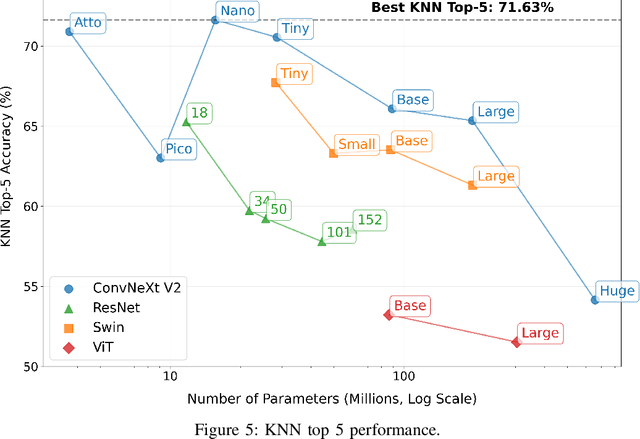
We introduce the 8-Calves dataset, a benchmark for evaluating object detection and identity classification in occlusion-rich, temporally consistent environments. The dataset comprises a 1-hour video (67,760 frames) of eight Holstein Friesian calves in a barn, with ground truth bounding boxes and identities, alongside 900 static frames for detection tasks. Each calf exhibits a unique coat pattern, enabling precise identity distinction. For cow detection, we fine-tuned 28 models (25 YOLO variants, 3 transformers) on 600 frames, testing on the full video. Results reveal smaller YOLO models (e.g., YOLOV9c) outperform larger counterparts despite potential bias from a YOLOv8m-based labeling pipeline. For identity classification, embeddings from 23 pretrained vision models (ResNet, ConvNextV2, ViTs) were evaluated via linear classifiers and KNN. Modern architectures like ConvNextV2 excelled, while larger models frequently overfit, highlighting inefficiencies in scaling. Key findings include: (1) Minimal, targeted augmentations (e.g., rotation) outperform complex strategies on simpler datasets; (2) Pretraining strategies (e.g., BEiT, DinoV2) significantly boost identity recognition; (3) Temporal continuity and natural motion patterns offer unique challenges absent in synthetic or domain-specific benchmarks. The dataset's controlled design and extended sequences (1 hour vs. prior 10-minute benchmarks) make it a pragmatic tool for stress-testing occlusion handling, temporal consistency, and efficiency. The link to the dataset is https://github.com/tonyFang04/8-calves.
Recurrent Feedback Improves Feedforward Representations in Deep Neural Networks
Dec 22, 2019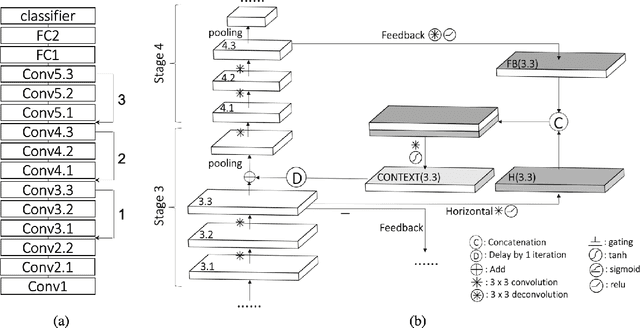


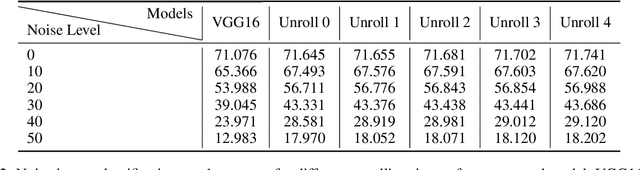
The abundant recurrent horizontal and feedback connections in the primate visual cortex are thought to play an important role in bringing global and semantic contextual information to early visual areas during perceptual inference, helping to resolve local ambiguity and fill in missing details. In this study, we find that introducing feedback loops and horizontal recurrent connections to a deep convolution neural network (VGG16) allows the network to become more robust against noise and occlusion during inference, even in the initial feedforward pass. This suggests that recurrent feedback and contextual modulation transform the feedforward representations of the network in a meaningful and interesting way. We study the population codes of neurons in the network, before and after learning with feedback, and find that learning with feedback yielded an increase in discriminability (measured by d-prime) between the different object classes in the population codes of the neurons in the feedforward path, even at the earliest layer that receives feedback. We find that recurrent feedback, by injecting top-down semantic meaning to the population activities, helps the network learn better feedforward paths to robustly map noisy image patches to the latent representations corresponding to important visual concepts of each object class, resulting in greater robustness of the network against noises and occlusion as well as better fine-grained recognition.