 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlasGS: Brain MRI Spatial Resolution Harmonization With Shared Gaussian Geometry
Jun 01, 2026Splatting (GS)-based shared geometry framework adopts a two-stage training strategy, in which an explicit, subject-specific Gaussian scaffold encoding anatomical geometry is first learned from the isotropic structural scan and then reused to fit appearance for target modalities acquired with sparse slices. Experiments on the UK Biobank, GBM, and ABCD datasets for through-plane super-resolution across multiple modalities (T2-weighted, FLAIR, DWI, ASL), degradation factors ($\times 3$, $\times 5$, $\times 7$), and pathological abnormalities (glioblastoma) demonstrate state-of-the-art reconstruction fidelity. The shared Gaussian geometry enables arbitrary-view generation for target modalities with strong structural consistency and further shows potential for self-supervised in-plane super-resolution. This work establishes explicit geometry-guided representations as a novel, flexible, and interpretable pathway toward retrospective multi-contrast MRI harmonization and reliable clinical reference construction. Source code is available at: https://github.com/yfgao76/AtlasGS
AutoIQ: An Ensemble Framework for Automatic Assessment of Geometric Distortion in Prostate Diffusion-Weighted Imaging
May 29, 2026Geometric distortion in prostate diffusion-weighted imaging (DWI) can impair lesion localization and reduce the reliability of MRI-based clinical assessment. We propose AutoIQ, an ensemble machine learning framework for automatic quantification and classification of DWI geometric distortion severity. A total of 140 retrospective prostate biparametric MRI examinations were analyzed, including 33 scans with severe distortion requiring repeat acquisition and 107 scans with acceptable distortion based on expert radiologist assessment. AutoIQ combines two complementary distortion quantification strategies: a segmentation-based method measuring prostate boundary mismatch between T2-weighted imaging (T2WI) and DWI, and a registration-based method estimating deformation magnitude after DWI-to-T2WI alignment. The resulting distortion scores were used to train individual classifiers and a logistic-regression ensemble model. Both computational methods significantly differentiated severe from acceptable distortion cases (p < 0.001). On an independent test set, the ensemble model achieved an accuracy of 0.95, F1-score of 0.93, and AUC of 0.98, outperforming individual models. These results suggest that AutoIQ can provide automated, quantitative quality assessment for prostate DWI and may help identify scans that require repeat acquisition.
BCER Agent: Reliable Long-Horizon MRI Workflow Execution via Compilation, Artifact Binding, and Bounded Local Recovery
May 27, 2026Many recent medical VLM and agent studies are benchmarked on 2D images or comparatively short tool-calling exchanges, whereas real MRI analysis typically demands long, interdependent pipelines that operate on 3D/4D volumetric data. Under these conditions, reactive tool-calling agents are prone to cascading breakdowns triggered by faulty intermediate references, mismatched tool arguments, and limited control over cross-step dependencies. To address this, we introduce BCER (Brain-Cerebellum-Extremity-Reflector), a controller architecture aimed at dependable long-horizon MRI workflow execution. BCER decouples high-level planning from execution and provides bounded local recovery. We assess BCER on a multi-organ MRI benchmark covering brain, prostate, and cardiac tasks with both short- and long-chain workflows, using matched task contracts across controller variants and several backbone models. Relative to reactive baselines, BCER yields consistent improvements in end-to-end execution, with the most pronounced gains observed on long-chain workflows. BCER additionally enables auditability by maintaining explicit links between final outputs and intermediate artifacts and measurements. Code and benchmark are released at https://github.com/Albertlongzi/BCER.
Let Distortion Guide Restoration (DGR): A physics-informed learning framework for Prostate Diffusion MRI
Jan 01, 2026We present Distortion-Guided Restoration (DGR), a physics-informed hybrid CNN-diffusion framework for acquisition-free correction of severe susceptibility-induced distortions in prostate single-shot EPI diffusion-weighted imaging (DWI). DGR is trained to invert a realistic forward distortion model using large-scale paired distorted and undistorted data synthesized from distortion-free prostate DWI and co-registered T2-weighted images from 410 multi-institutional studies, together with 11 measured B0 field maps from metal-implant cases incorporated into a forward simulator to generate low-b DWI (b = 50 s per mm squared), high-b DWI (b = 1400 s per mm squared), and ADC distortions. The network couples a CNN-based geometric correction module with conditional diffusion refinement under T2-weighted anatomical guidance. On a held-out synthetic validation set (n = 34) using ground-truth simulated distortion fields, DGR achieved higher PSNR and lower NMSE than FSL TOPUP and FUGUE. In 34 real clinical studies with severe distortion, including hip prostheses and marked rectal distension, DGR improved geometric fidelity and increased radiologist-rated image quality and diagnostic confidence. Overall, learning the inverse of a physically simulated forward process provides a practical alternative to acquisition-dependent distortion-correction pipelines for prostate DWI.
EchoPrime: A Multi-Video View-Informed Vision-Language Model for Comprehensive Echocardiography Interpretation
Oct 13, 2024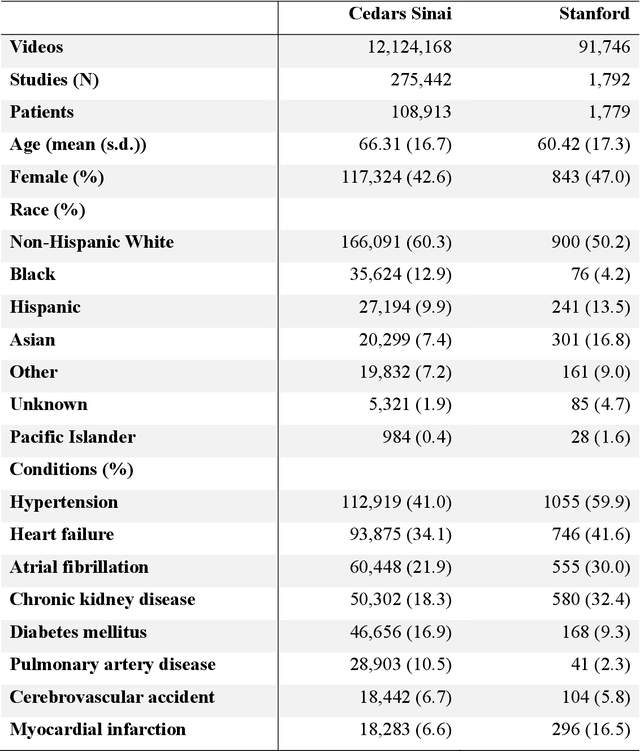
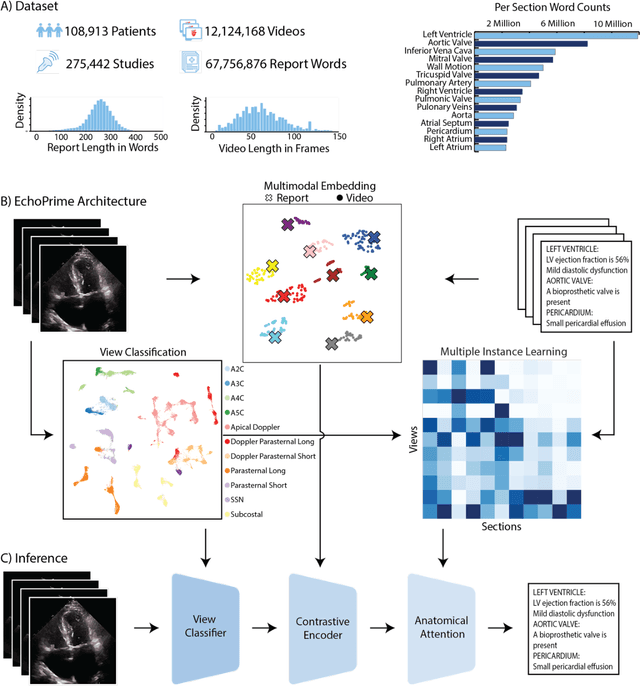
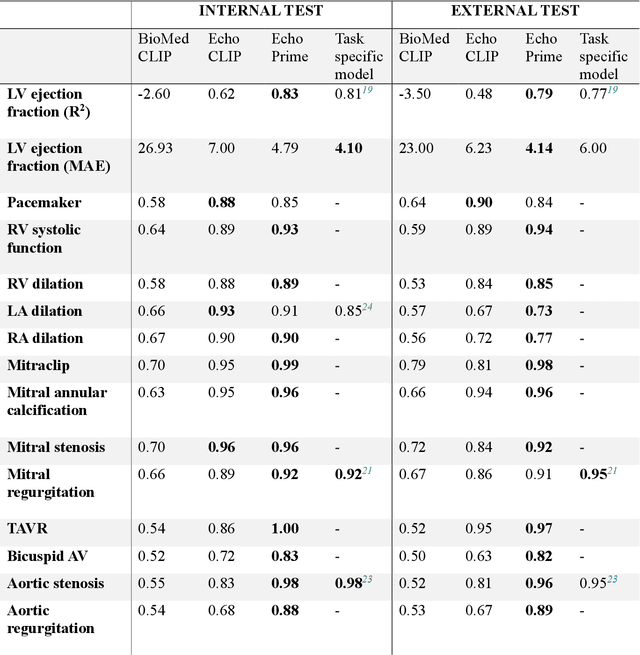
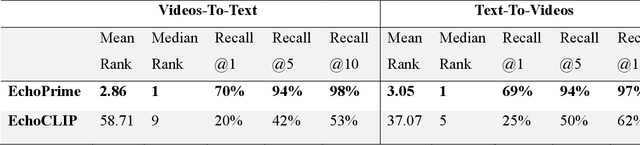
Echocardiography is the most widely used cardiac imaging modality, capturing ultrasound video data to assess cardiac structure and function. Artificial intelligence (AI) in echocardiography has the potential to streamline manual tasks and improve reproducibility and precision. However, most echocardiography AI models are single-view, single-task systems that do not synthesize complementary information from multiple views captured during a full exam, and thus lead to limited performance and scope of applications. To address this problem, we introduce EchoPrime, a multi-view, view-informed, video-based vision-language foundation model trained on over 12 million video-report pairs. EchoPrime uses contrastive learning to train a unified embedding model for all standard views in a comprehensive echocardiogram study with representation of both rare and common diseases and diagnoses. EchoPrime then utilizes view-classification and a view-informed anatomic attention model to weight video-specific interpretations that accurately maps the relationship between echocardiographic views and anatomical structures. With retrieval-augmented interpretation, EchoPrime integrates information from all echocardiogram videos in a comprehensive study and performs holistic comprehensive clinical echocardiography interpretation. In datasets from two independent healthcare systems, EchoPrime achieves state-of-the art performance on 23 diverse benchmarks of cardiac form and function, surpassing the performance of both task-specific approaches and prior foundation models. Following rigorous clinical evaluation, EchoPrime can assist physicians in the automated preliminary assessment of comprehensive echocardiography.
Data-Consistent Non-Cartesian Deep Subspace Learning for Efficient Dynamic MR Image Reconstruction
May 03, 2022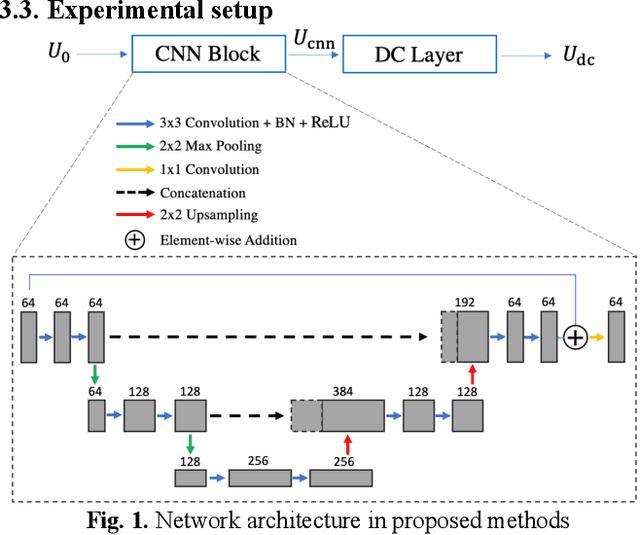
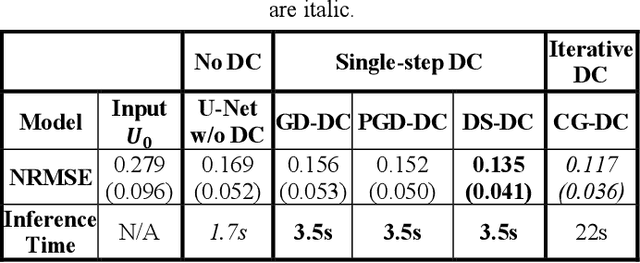
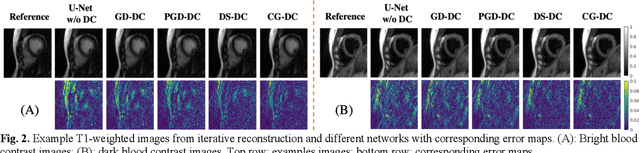
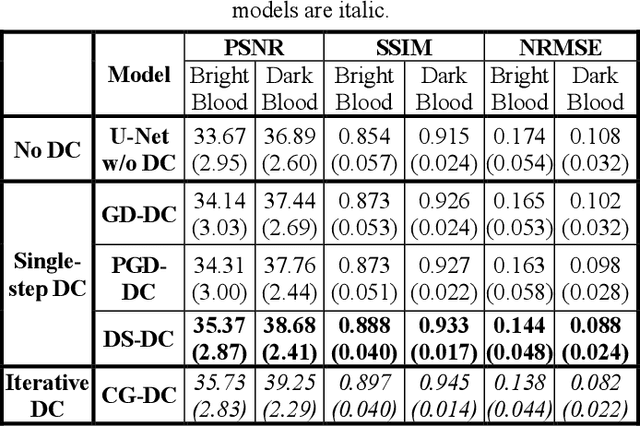
Non-Cartesian sampling with subspace-constrained image reconstruction is a popular approach to dynamic MRI, but slow iterative reconstruction limits its clinical application. Data-consistent (DC) deep learning can accelerate reconstruction with good image quality, but has not been formulated for non-Cartesian subspace imaging. In this study, we propose a DC non-Cartesian deep subspace learning framework for fast, accurate dynamic MR image reconstruction. Four novel DC formulations are developed and evaluated: two gradient decent approaches, a directly solved approach, and a conjugate gradient approach. We applied a U-Net model with and without DC layers to reconstruct T1-weighted images for cardiac MR Multitasking (an advanced multidimensional imaging method), comparing our results to the iteratively reconstructed reference. Experimental results show that the proposed framework significantly improves reconstruction accuracy over the U-Net model without DC, while significantly accelerating the reconstruction over conventional iterative reconstruction.
Cine Cardiac MRI Motion Artifact Reduction Using a Recurrent Neural Network
Jun 23, 2020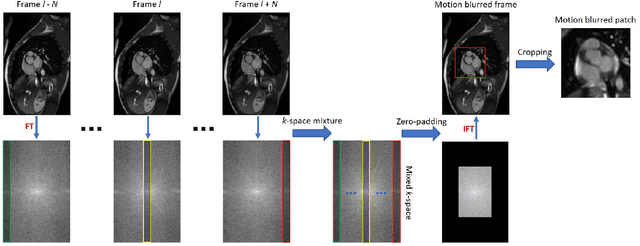

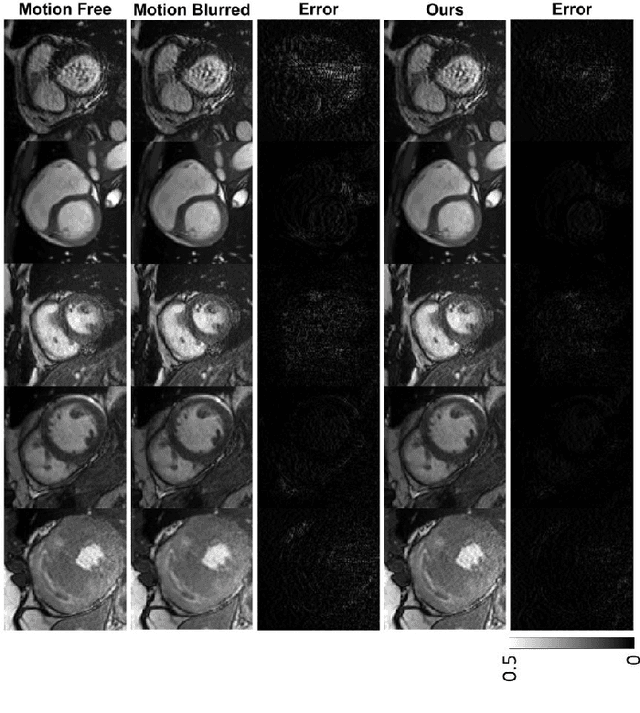
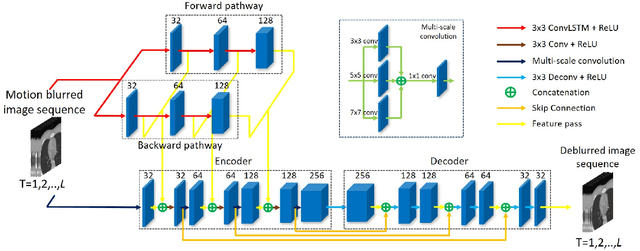
Cine cardiac magnetic resonance imaging (MRI) is widely used for diagnosis of cardiac diseases thanks to its ability to present cardiovascular features in excellent contrast. As compared to computed tomography (CT), MRI, however, requires a long scan time, which inevitably induces motion artifacts and causes patients' discomfort. Thus, there has been a strong clinical motivation to develop techniques to reduce both the scan time and motion artifacts. Given its successful applications in other medical imaging tasks such as MRI super-resolution and CT metal artifact reduction, deep learning is a promising approach for cardiac MRI motion artifact reduction. In this paper, we propose a recurrent neural network to simultaneously extract both spatial and temporal features from under-sampled, motion-blurred cine cardiac images for improved image quality. The experimental results demonstrate substantially improved image quality on two clinical test datasets. Also, our method enables data-driven frame interpolation at an enhanced temporal resolution. Compared with existing methods, our deep learning approach gives a superior performance in terms of structural similarity (SSIM) and peak signal-to-noise ratio (PSNR).
MRI Super-Resolution with GAN and 3D Multi-Level DenseNet: Smaller, Faster, and Better
Mar 06, 2020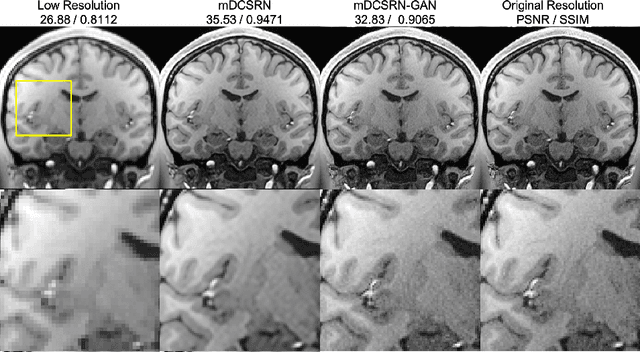
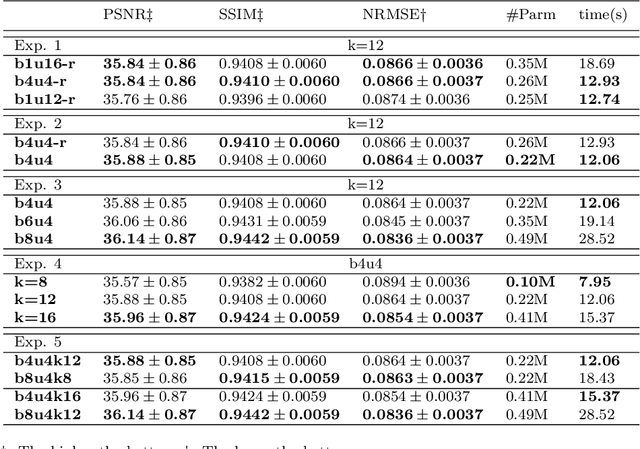
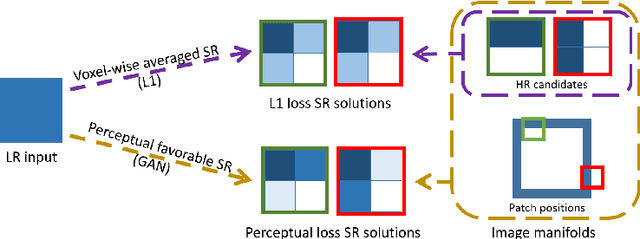
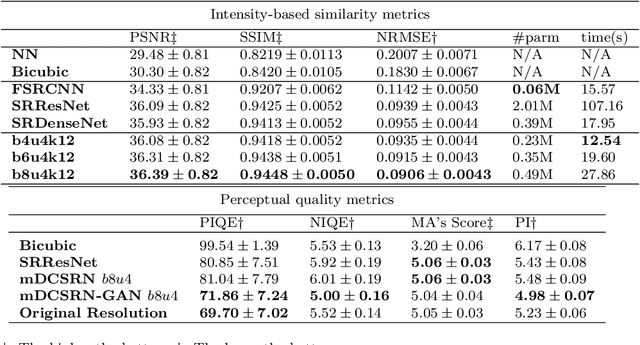
High-resolution (HR) magnetic resonance imaging (MRI) provides detailed anatomical information that is critical for diagnosis in the clinical application. However, HR MRI typically comes at the cost of long scan time, small spatial coverage, and low signal-to-noise ratio (SNR). Recent studies showed that with a deep convolutional neural network (CNN), HR generic images could be recovered from low-resolution (LR) inputs via single image super-resolution (SISR) approaches. Additionally, previous works have shown that a deep 3D CNN can generate high-quality SR MRIs by using learned image priors. However, 3D CNN with deep structures, have a large number of parameters and are computationally expensive. In this paper, we propose a novel 3D CNN architecture, namely a multi-level densely connected super-resolution network (mDCSRN), which is light-weight, fast and accurate. We also show that with the generative adversarial network (GAN)-guided training, the mDCSRN-GAN provides appealing sharp SR images with rich texture details that are highly comparable with the referenced HR images. Our results from experiments on a large public dataset with 1,113 subjects showed that this new architecture outperformed other popular deep learning methods in recovering 4x resolution-downgraded images in both quality and speed.
Fully Automated Multi-Organ Segmentation in Abdominal Magnetic Resonance Imaging with Deep Neural Networks
Dec 23, 2019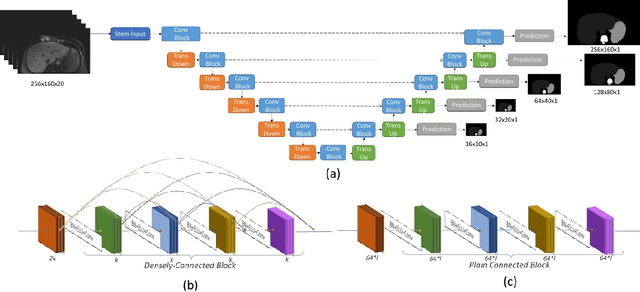
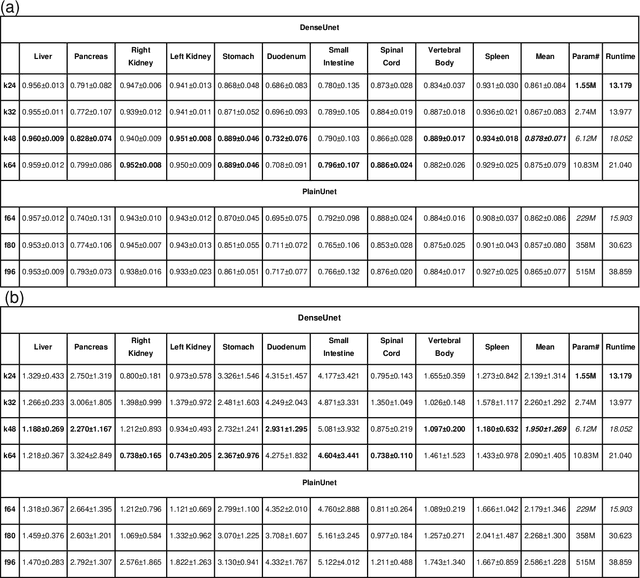

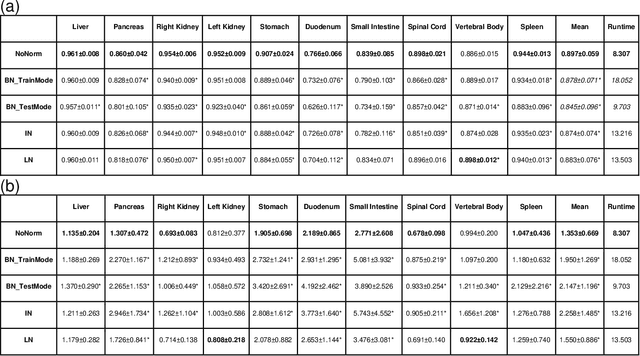
Segmentation of multiple organs-at-risk (OARs) is essential for radiation therapy treatment planning and other clinical applications. We developed an Automated deep Learning-based Abdominal Multi-Organ segmentation (ALAMO) framework based on 2D U-net and a densely connected network structure with tailored design in data augmentation and training procedures such as deep connection, auxiliary supervision, and multi-view. The model takes in multi-slice MR images and generates the output of segmentation results. Three-Tesla T1 VIBE (Volumetric Interpolated Breath-hold Examination) images of 102 subjects were collected and used in our study. Ten OARs were studied, including the liver, spleen, pancreas, left/right kidneys, stomach, duodenum, small intestine, spinal cord, and vertebral bodies. Two radiologists manually labeled and obtained the consensus contours as the ground-truth. In the complete cohort of 102, 20 samples were held out for independent testing, and the rest were used for training and validation. The performance was measured using volume overlapping and surface distance. The ALAMO framework generated segmentation labels in good agreement with the manual results. Specifically, among the 10 OARs, 9 achieved high Dice Similarity Coefficients (DSCs) in the range of 0.87-0.96, except for the duodenum with a DSC of 0.80. The inference completes within one minute for a 3D volume of 320x288x180. Overall, the ALAMO model matches the state-of-the-art performance. The proposed ALAMO framework allows for fully automated abdominal MR segmentation with high accuracy and low memory and computation time demands.
Deep learning within a priori temporal feature spaces for large-scale dynamic MR image reconstruction: Application to 5-D cardiac MR Multitasking
Oct 02, 2019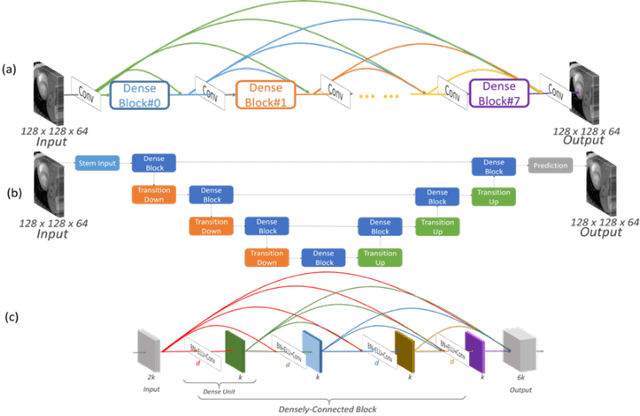
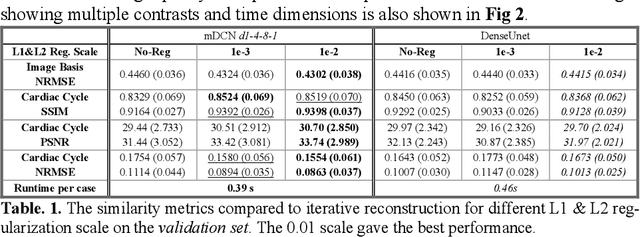
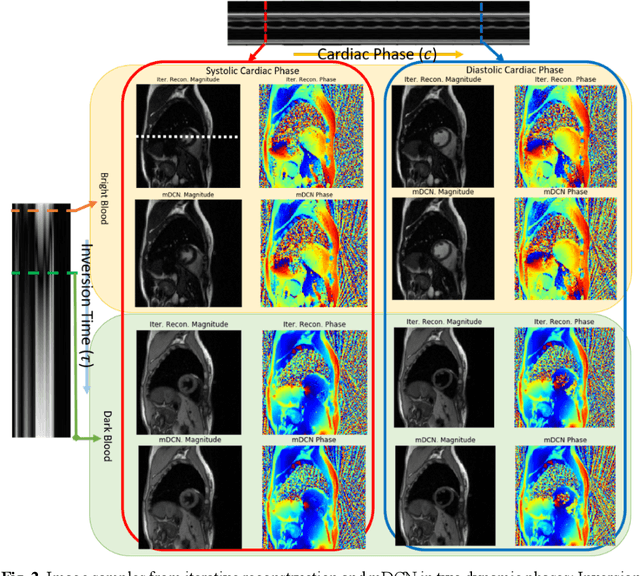
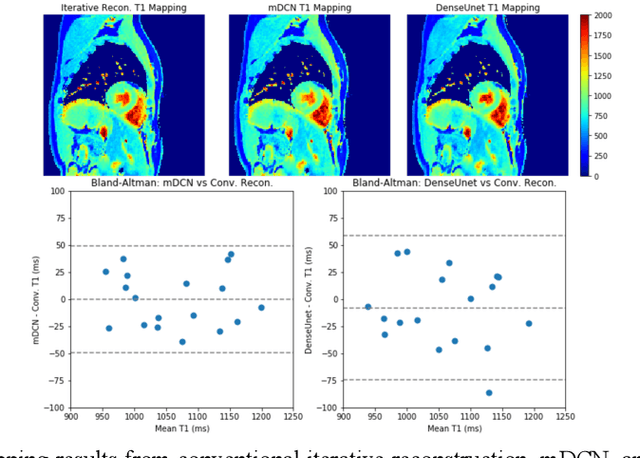
High spatiotemporal resolution dynamic magnetic resonance imaging (MRI) is a powerful clinical tool for imaging moving structures as well as to reveal and quantify other physical and physiological dynamics. The low speed of MRI necessitates acceleration methods such as deep learning reconstruction from under-sampled data. However, the massive size of many dynamic MRI problems prevents deep learning networks from directly exploiting global temporal relationships. In this work, we show that by applying deep neural networks inside a priori calculated temporal feature spaces, we enable deep learning reconstruction with global temporal modeling even for image sequences with >40,000 frames. One proposed variation of our approach using dilated multi-level Densely Connected Network (mDCN) speeds up feature space coordinate calculation by 3000x compared to conventional iterative methods, from 20 minutes to 0.39 seconds. Thus, the combination of low-rank tensor and deep learning models not only makes large-scale dynamic MRI feasible but also practical for routine clinical application.