 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCORO-CLIP: A Multi-View Foundation Model for Comprehensive Coronary Angiography Video-Text Analysis and External Validation
Mar 18, 2026Coronary angiography is the reference standard for evaluating coronary artery disease, yet visual interpretation remains variable between readers. Existing artificial intelligence methods typically analyze single frames or projections and focus mainly on stenosis, limiting comprehensive coronary assessment. We present DeepCORO-CLIP, a multi-view foundation model trained with video-text contrastive learning on 203,808 angiography videos from 28,117 patients across 32,473 studies at the Montreal Heart Institute and externally validated on 4,249 studies from the University of California, San Francisco. DeepCORO-CLIP integrates multiple projections with attention-based pooling for study-level assessment across diagnostic, prognostic, and disease progression tasks. For significant stenosis detection, the model achieved an AUROC of 0.888 internally and 0.89 on external validation. Mean absolute error against core laboratory quantitative coronary angiography was 13.6%, lower than clinical reports at 19.0%. The model also performed strongly for chronic total occlusion, intracoronary thrombus, and coronary calcification detection. Transfer learning enabled prediction of one-year major adverse cardiovascular events with AUROC 0.79 and estimation of left ventricular ejection fraction with mean absolute error 7.3%. Embeddings also captured disease progression across serial examinations. With a mean inference time of 4.2 seconds in hospital deployment, DeepCORO-CLIP provides a foundation for automated coronary angiography interpretation at the point of care. Code, sample data, model weights, and deployment infrastructure are publicly released.
Medical Image De-Identification Benchmark Challenge
Jul 31, 2025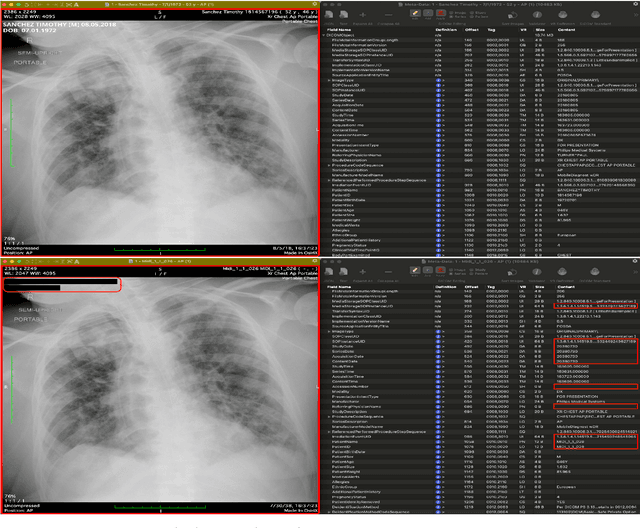
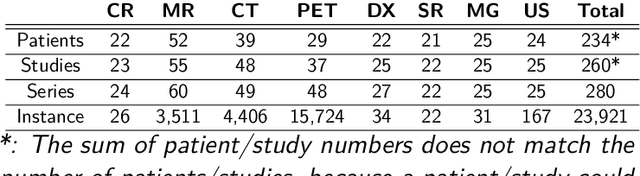
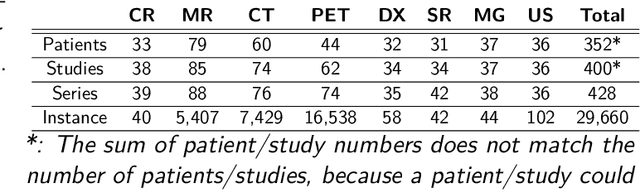
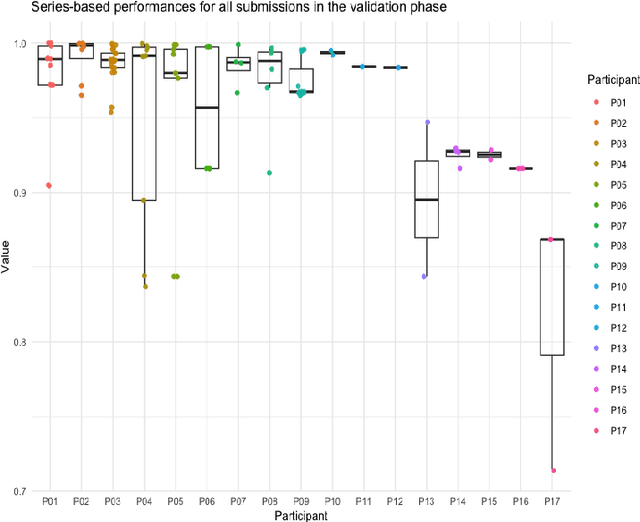
The de-identification (deID) of protected health information (PHI) and personally identifiable information (PII) is a fundamental requirement for sharing medical images, particularly through public repositories, to ensure compliance with patient privacy laws. In addition, preservation of non-PHI metadata to inform and enable downstream development of imaging artificial intelligence (AI) is an important consideration in biomedical research. The goal of MIDI-B was to provide a standardized platform for benchmarking of DICOM image deID tools based on a set of rules conformant to the HIPAA Safe Harbor regulation, the DICOM Attribute Confidentiality Profiles, and best practices in preservation of research-critical metadata, as defined by The Cancer Imaging Archive (TCIA). The challenge employed a large, diverse, multi-center, and multi-modality set of real de-identified radiology images with synthetic PHI/PII inserted. The MIDI-B Challenge consisted of three phases: training, validation, and test. Eighty individuals registered for the challenge. In the training phase, we encouraged participants to tune their algorithms using their in-house or public data. The validation and test phases utilized the DICOM images containing synthetic identifiers (of 216 and 322 subjects, respectively). Ten teams successfully completed the test phase of the challenge. To measure success of a rule-based approach to image deID, scores were computed as the percentage of correct actions from the total number of required actions. The scores ranged from 97.91% to 99.93%. Participants employed a variety of open-source and proprietary tools with customized configurations, large language models, and optical character recognition (OCR). In this paper we provide a comprehensive report on the MIDI-B Challenge's design, implementation, results, and lessons learned.
EchoPrime: A Multi-Video View-Informed Vision-Language Model for Comprehensive Echocardiography Interpretation
Oct 13, 2024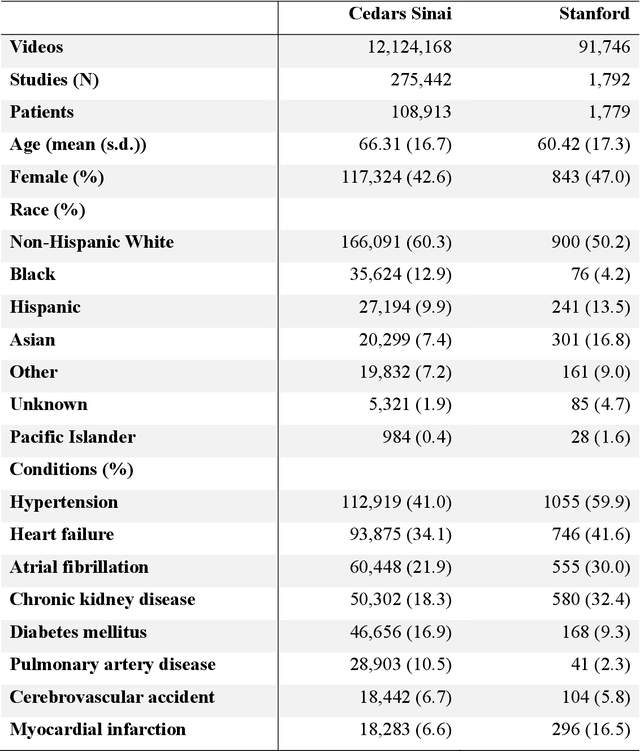
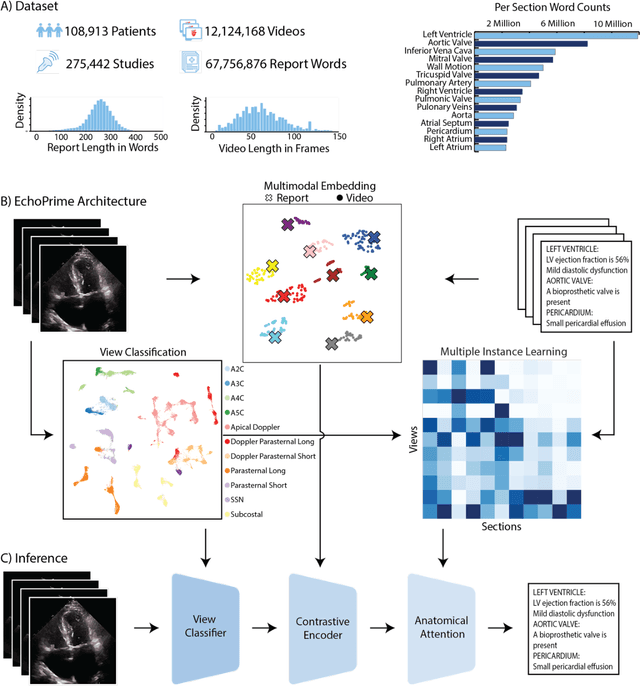
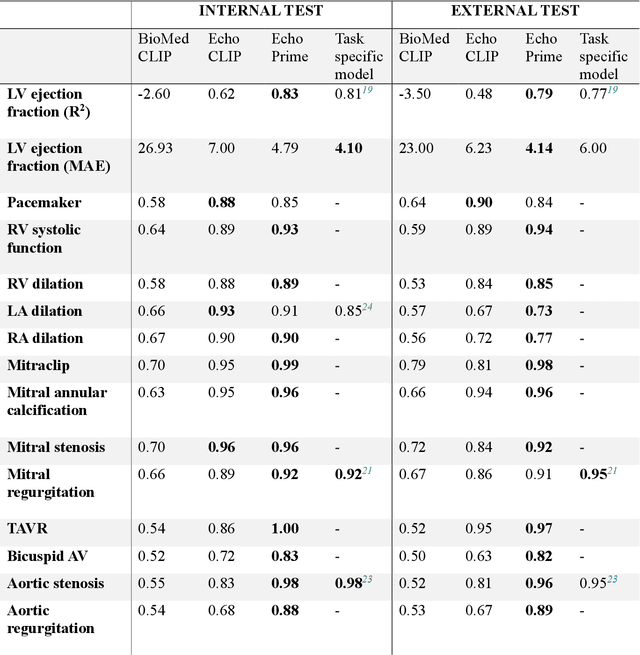
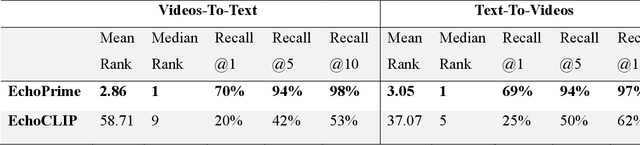
Echocardiography is the most widely used cardiac imaging modality, capturing ultrasound video data to assess cardiac structure and function. Artificial intelligence (AI) in echocardiography has the potential to streamline manual tasks and improve reproducibility and precision. However, most echocardiography AI models are single-view, single-task systems that do not synthesize complementary information from multiple views captured during a full exam, and thus lead to limited performance and scope of applications. To address this problem, we introduce EchoPrime, a multi-view, view-informed, video-based vision-language foundation model trained on over 12 million video-report pairs. EchoPrime uses contrastive learning to train a unified embedding model for all standard views in a comprehensive echocardiogram study with representation of both rare and common diseases and diagnoses. EchoPrime then utilizes view-classification and a view-informed anatomic attention model to weight video-specific interpretations that accurately maps the relationship between echocardiographic views and anatomical structures. With retrieval-augmented interpretation, EchoPrime integrates information from all echocardiogram videos in a comprehensive study and performs holistic comprehensive clinical echocardiography interpretation. In datasets from two independent healthcare systems, EchoPrime achieves state-of-the art performance on 23 diverse benchmarks of cardiac form and function, surpassing the performance of both task-specific approaches and prior foundation models. Following rigorous clinical evaluation, EchoPrime can assist physicians in the automated preliminary assessment of comprehensive echocardiography.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Multimodal Foundation Models For Echocardiogram Interpretation
Sep 02, 2023Multimodal deep learning foundation models can learn the relationship between images and text. In the context of medical imaging, mapping images to language concepts reflects the clinical task of diagnostic image interpretation, however current general-purpose foundation models do not perform well in this context because their training corpus have limited medical text and images. To address this challenge and account for the range of cardiac physiology, we leverage 1,032,975 cardiac ultrasound videos and corresponding expert interpretations to develop EchoCLIP, a multimodal foundation model for echocardiography. EchoCLIP displays strong zero-shot (not explicitly trained) performance in cardiac function assessment (external validation left ventricular ejection fraction mean absolute error (MAE) of 7.1%) and identification of implanted intracardiac devices (areas under the curve (AUC) between 0.84 and 0.98 for pacemakers and artificial heart valves). We also developed a long-context variant (EchoCLIP-R) with a custom echocardiography report text tokenizer which can accurately identify unique patients across multiple videos (AUC of 0.86), identify clinical changes such as orthotopic heart transplants (AUC of 0.79) or cardiac surgery (AUC 0.77), and enable robust image-to-text search (mean cross-modal retrieval rank in the top 1% of candidate text reports). These emergent capabilities can be used for preliminary assessment and summarization of echocardiographic findings.