 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

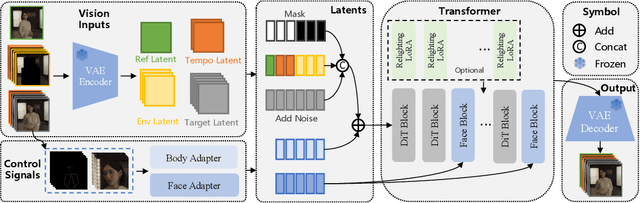
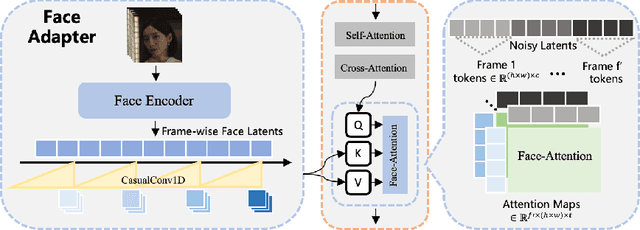
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Exact: Exploring Space-Time Perceptive Clues for Weakly Supervised Satellite Image Time Series Semantic Segmentation
Dec 05, 2024



Automated crop mapping through Satellite Image Time Series (SITS) has emerged as a crucial avenue for agricultural monitoring and management. However, due to the low resolution and unclear parcel boundaries, annotating pixel-level masks is exceptionally complex and time-consuming in SITS. This paper embraces the weakly supervised paradigm (i.e., only image-level categories available) to liberate the crop mapping task from the exhaustive annotation burden. The unique characteristics of SITS give rise to several challenges in weakly supervised learning: (1) noise perturbation from spatially neighboring regions, and (2) erroneous semantic bias from anomalous temporal periods. To address the above difficulties, we propose a novel method, termed exploring space-time perceptive clues (Exact). First, we introduce a set of spatial clues to explicitly capture the representative patterns of different crops from the most class-relative regions. Besides, we leverage the temporal-to-class interaction of the model to emphasize the contributions of pivotal clips, thereby enhancing the model perception for crop regions. Build upon the space-time perceptive clues, we derive the clue-based CAMs to effectively supervise the SITS segmentation network. Our method demonstrates impressive performance on various SITS benchmarks. Remarkably, the segmentation network trained on Exact-generated masks achieves 95% of its fully supervised performance, showing the bright promise of weakly supervised paradigm in crop mapping scenario. Our code will be publicly available.
Towards Robustness and Diversity: Continual Learning in Dialog Generation with Text-Mixup and Batch Nuclear-Norm Maximization
Mar 16, 2024In our dynamic world where data arrives in a continuous stream, continual learning enables us to incrementally add new tasks/domains without the need to retrain from scratch. A major challenge in continual learning of language model is catastrophic forgetting, the tendency of models to forget knowledge from previously trained tasks/domains when training on new ones. This paper studies dialog generation under the continual learning setting. We propose a novel method that 1) uses \textit{Text-Mixup} as data augmentation to avoid model overfitting on replay memory and 2) leverages Batch-Nuclear Norm Maximization (BNNM) to alleviate the problem of mode collapse. Experiments on a $37$-domain task-oriented dialog dataset and DailyDialog (a $10$-domain chitchat dataset) demonstrate that our proposed approach outperforms the state-of-the-art in continual learning.
Pick-and-Draw: Training-free Semantic Guidance for Text-to-Image Personalization
Jan 30, 2024Diffusion-based text-to-image personalization have achieved great success in generating subjects specified by users among various contexts. Even though, existing finetuning-based methods still suffer from model overfitting, which greatly harms the generative diversity, especially when given subject images are few. To this end, we propose Pick-and-Draw, a training-free semantic guidance approach to boost identity consistency and generative diversity for personalization methods. Our approach consists of two components: appearance picking guidance and layout drawing guidance. As for the former, we construct an appearance palette with visual features from the reference image, where we pick local patterns for generating the specified subject with consistent identity. As for layout drawing, we outline the subject's contour by referring to a generative template from the vanilla diffusion model, and inherit the strong image prior to synthesize diverse contexts according to different text conditions. The proposed approach can be applied to any personalized diffusion models and requires as few as a single reference image. Qualitative and quantitative experiments show that Pick-and-Draw consistently improves identity consistency and generative diversity, pushing the trade-off between subject fidelity and image-text fidelity to a new Pareto frontier.
R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation
Oct 26, 2023



Recent text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images given text-prompts as input. However, these models fail to convey appropriate spatial composition specified by a layout instruction. In this work, we probe into zero-shot grounded T2I generation with diffusion models, that is, generating images corresponding to the input layout information without training auxiliary modules or finetuning diffusion models. We propose a Region and Boundary (R&B) aware cross-attention guidance approach that gradually modulates the attention maps of diffusion model during generative process, and assists the model to synthesize images (1) with high fidelity, (2) highly compatible with textual input, and (3) interpreting layout instructions accurately. Specifically, we leverage the discrete sampling to bridge the gap between consecutive attention maps and discrete layout constraints, and design a region-aware loss to refine the generative layout during diffusion process. We further propose a boundary-aware loss to strengthen object discriminability within the corresponding regions. Experimental results show that our method outperforms existing state-of-the-art zero-shot grounded T2I generation methods by a large margin both qualitatively and quantitatively on several benchmarks.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 31, 2022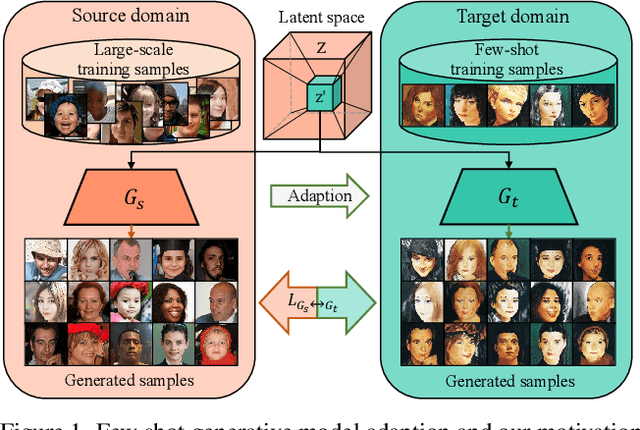
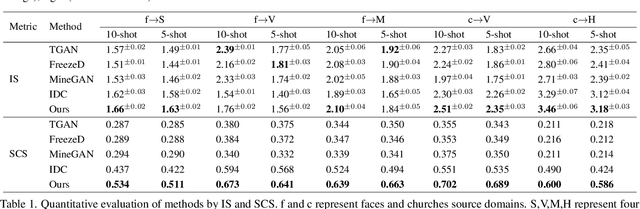
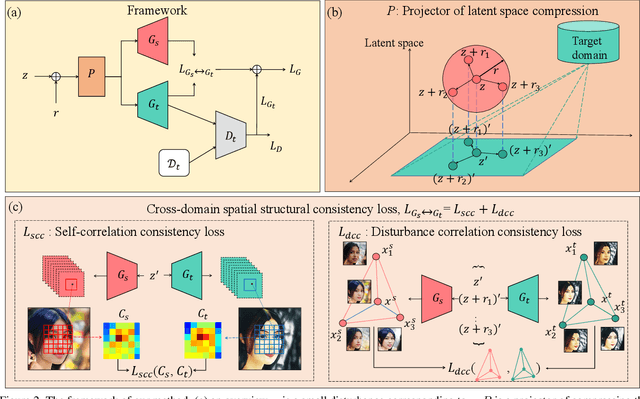

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
Towards Learning Spatially Discriminative Feature Representations
Sep 03, 2021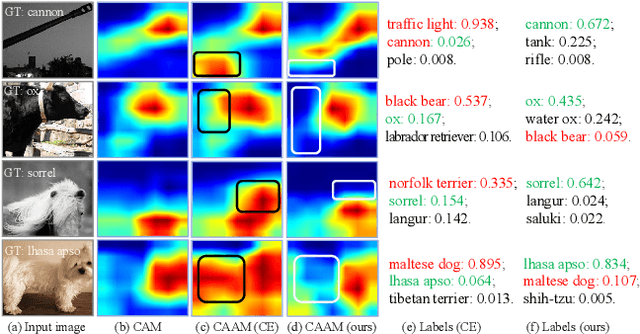

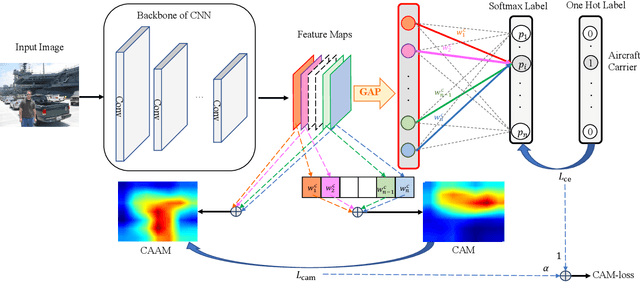
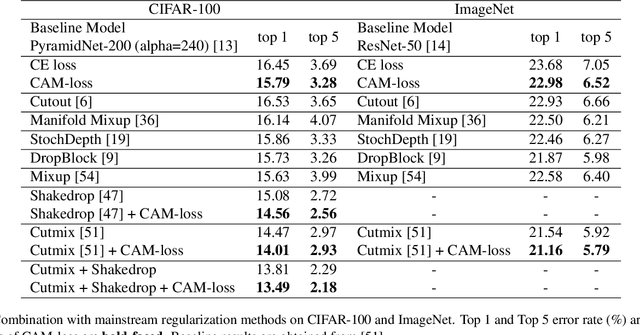
The backbone of traditional CNN classifier is generally considered as a feature extractor, followed by a linear layer which performs the classification. We propose a novel loss function, termed as CAM-loss, to constrain the embedded feature maps with the class activation maps (CAMs) which indicate the spatially discriminative regions of an image for particular categories. CAM-loss drives the backbone to express the features of target category and suppress the features of non-target categories or background, so as to obtain more discriminative feature representations. It can be simply applied in any CNN architecture with neglectable additional parameters and calculations. Experimental results show that CAM-loss is applicable to a variety of network structures and can be combined with mainstream regularization methods to improve the performance of image classification. The strong generalization ability of CAM-loss is validated in the transfer learning and few shot learning tasks. Based on CAM-loss, we also propose a novel CAAM-CAM matching knowledge distillation method. This method directly uses the CAM generated by the teacher network to supervise the CAAM generated by the student network, which effectively improves the accuracy and convergence rate of the student network.
Fully Automated Multi-Organ Segmentation in Abdominal Magnetic Resonance Imaging with Deep Neural Networks
Dec 23, 2019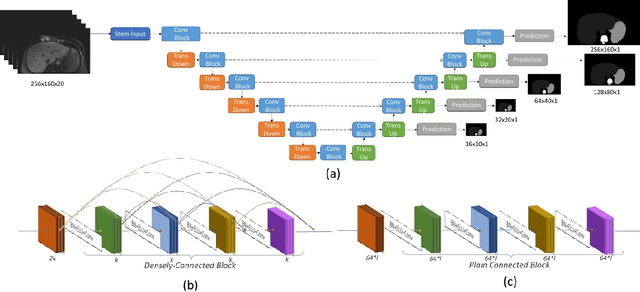
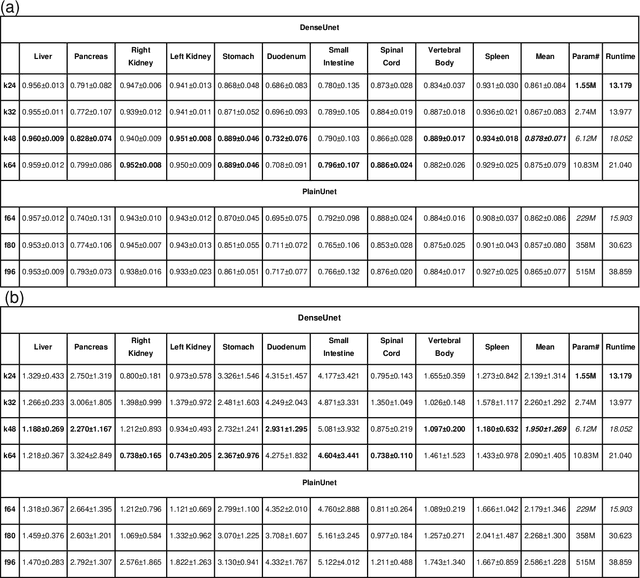

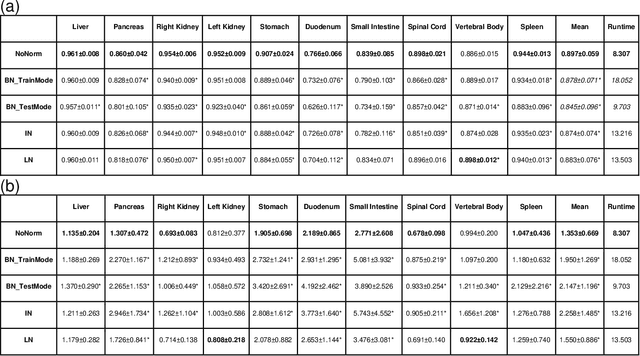
Segmentation of multiple organs-at-risk (OARs) is essential for radiation therapy treatment planning and other clinical applications. We developed an Automated deep Learning-based Abdominal Multi-Organ segmentation (ALAMO) framework based on 2D U-net and a densely connected network structure with tailored design in data augmentation and training procedures such as deep connection, auxiliary supervision, and multi-view. The model takes in multi-slice MR images and generates the output of segmentation results. Three-Tesla T1 VIBE (Volumetric Interpolated Breath-hold Examination) images of 102 subjects were collected and used in our study. Ten OARs were studied, including the liver, spleen, pancreas, left/right kidneys, stomach, duodenum, small intestine, spinal cord, and vertebral bodies. Two radiologists manually labeled and obtained the consensus contours as the ground-truth. In the complete cohort of 102, 20 samples were held out for independent testing, and the rest were used for training and validation. The performance was measured using volume overlapping and surface distance. The ALAMO framework generated segmentation labels in good agreement with the manual results. Specifically, among the 10 OARs, 9 achieved high Dice Similarity Coefficients (DSCs) in the range of 0.87-0.96, except for the duodenum with a DSC of 0.80. The inference completes within one minute for a 3D volume of 320x288x180. Overall, the ALAMO model matches the state-of-the-art performance. The proposed ALAMO framework allows for fully automated abdominal MR segmentation with high accuracy and low memory and computation time demands.