 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth Diffusion: Crafting Smooth Latent Spaces in Diffusion Models
Dec 07, 2023



Recently, diffusion models have made remarkable progress in text-to-image (T2I) generation, synthesizing images with high fidelity and diverse contents. Despite this advancement, latent space smoothness within diffusion models remains largely unexplored. Smooth latent spaces ensure that a perturbation on an input latent corresponds to a steady change in the output image. This property proves beneficial in downstream tasks, including image interpolation, inversion, and editing. In this work, we expose the non-smoothness of diffusion latent spaces by observing noticeable visual fluctuations resulting from minor latent variations. To tackle this issue, we propose Smooth Diffusion, a new category of diffusion models that can be simultaneously high-performing and smooth. Specifically, we introduce Step-wise Variation Regularization to enforce the proportion between the variations of an arbitrary input latent and that of the output image is a constant at any diffusion training step. In addition, we devise an interpolation standard deviation (ISTD) metric to effectively assess the latent space smoothness of a diffusion model. Extensive quantitative and qualitative experiments demonstrate that Smooth Diffusion stands out as a more desirable solution not only in T2I generation but also across various downstream tasks. Smooth Diffusion is implemented as a plug-and-play Smooth-LoRA to work with various community models. Code is available at https://github.com/SHI-Labs/Smooth-Diffusion.
Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation
Oct 06, 2023



Recent breakthroughs in large language models (LLMs) have brought remarkable success in the field of LLM-as-Agent. Nevertheless, a prevalent assumption is that the information processed by LLMs is consistently honest, neglecting the pervasive deceptive or misleading information in human society and AI-generated content. This oversight makes LLMs susceptible to malicious manipulations, potentially resulting in detrimental outcomes. This study utilizes the intricate Avalon game as a testbed to explore LLMs' potential in deceptive environments. Avalon, full of misinformation and requiring sophisticated logic, manifests as a "Game-of-Thoughts". Inspired by the efficacy of humans' recursive thinking and perspective-taking in the Avalon game, we introduce a novel framework, Recursive Contemplation (ReCon), to enhance LLMs' ability to identify and counteract deceptive information. ReCon combines formulation and refinement contemplation processes; formulation contemplation produces initial thoughts and speech, while refinement contemplation further polishes them. Additionally, we incorporate first-order and second-order perspective transitions into these processes respectively. Specifically, the first-order allows an LLM agent to infer others' mental states, and the second-order involves understanding how others perceive the agent's mental state. After integrating ReCon with different LLMs, extensive experiment results from the Avalon game indicate its efficacy in aiding LLMs to discern and maneuver around deceptive information without extra fine-tuning and data. Finally, we offer a possible explanation for the efficacy of ReCon and explore the current limitations of LLMs in terms of safety, reasoning, speaking style, and format, potentially furnishing insights for subsequent research.
Latency-aware Unified Dynamic Networks for Efficient Image Recognition
Sep 02, 2023Dynamic computation has emerged as a promising avenue to enhance the inference efficiency of deep networks. It allows selective activation of computational units, leading to a reduction in unnecessary computations for each input sample. However, the actual efficiency of these dynamic models can deviate from theoretical predictions. This mismatch arises from: 1) the lack of a unified approach due to fragmented research; 2) the focus on algorithm design over critical scheduling strategies, especially in CUDA-enabled GPU contexts; and 3) challenges in measuring practical latency, given that most libraries cater to static operations. Addressing these issues, we unveil the Latency-Aware Unified Dynamic Networks (LAUDNet), a framework that integrates three primary dynamic paradigms-spatially adaptive computation, dynamic layer skipping, and dynamic channel skipping. To bridge the theoretical and practical efficiency gap, LAUDNet merges algorithmic design with scheduling optimization, guided by a latency predictor that accurately gauges dynamic operator latency. We've tested LAUDNet across multiple vision tasks, demonstrating its capacity to notably reduce the latency of models like ResNet-101 by over 50% on platforms such as V100, RTX3090, and TX2 GPUs. Notably, LAUDNet stands out in balancing accuracy and efficiency. Code is available at: https://www.github.com/LeapLabTHU/LAUDNet.
Computation-efficient Deep Learning for Computer Vision: A Survey
Aug 27, 2023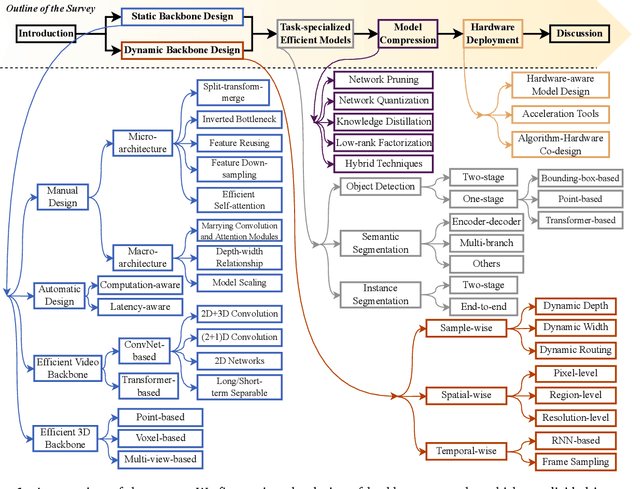
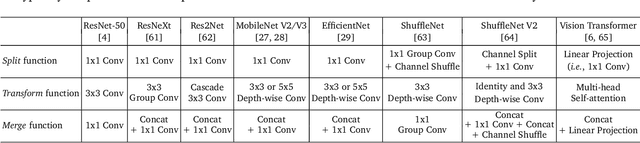
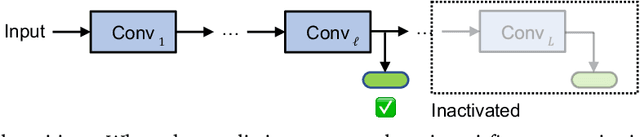
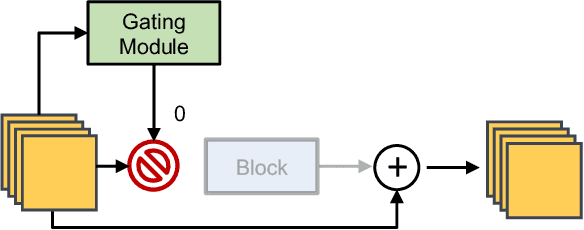
Over the past decade, deep learning models have exhibited considerable advancements, reaching or even exceeding human-level performance in a range of visual perception tasks. This remarkable progress has sparked interest in applying deep networks to real-world applications, such as autonomous vehicles, mobile devices, robotics, and edge computing. However, the challenge remains that state-of-the-art models usually demand significant computational resources, leading to impractical power consumption, latency, or carbon emissions in real-world scenarios. This trade-off between effectiveness and efficiency has catalyzed the emergence of a new research focus: computationally efficient deep learning, which strives to achieve satisfactory performance while minimizing the computational cost during inference. This review offers an extensive analysis of this rapidly evolving field by examining four key areas: 1) the development of static or dynamic light-weighted backbone models for the efficient extraction of discriminative deep representations; 2) the specialized network architectures or algorithms tailored for specific computer vision tasks; 3) the techniques employed for compressing deep learning models; and 4) the strategies for deploying efficient deep networks on hardware platforms. Additionally, we provide a systematic discussion on the critical challenges faced in this domain, such as network architecture design, training schemes, practical efficiency, and more realistic model compression approaches, as well as potential future research directions.
Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
Apr 06, 2023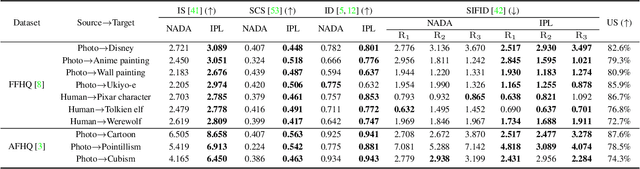
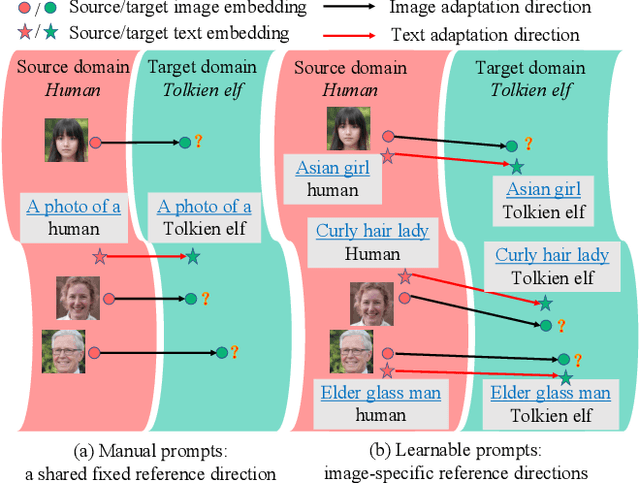
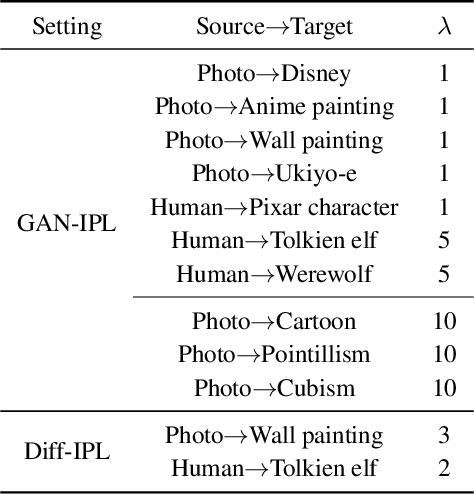
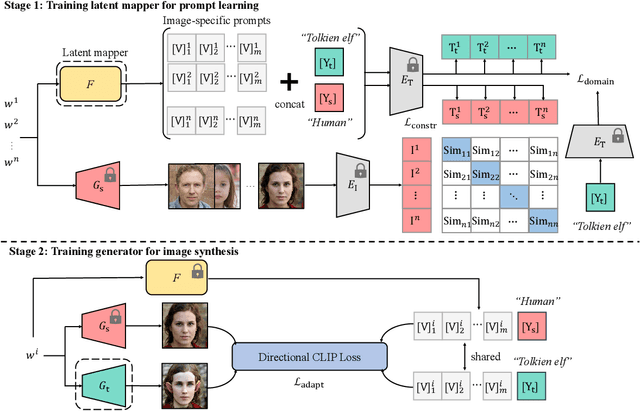
Recently, CLIP-guided image synthesis has shown appealing performance on adapting a pre-trained source-domain generator to an unseen target domain. It does not require any target-domain samples but only the textual domain labels. The training is highly efficient, e.g., a few minutes. However, existing methods still have some limitations in the quality of generated images and may suffer from the mode collapse issue. A key reason is that a fixed adaptation direction is applied for all cross-domain image pairs, which leads to identical supervision signals. To address this issue, we propose an Image-specific Prompt Learning (IPL) method, which learns specific prompt vectors for each source-domain image. This produces a more precise adaptation direction for every cross-domain image pair, endowing the target-domain generator with greatly enhanced flexibility. Qualitative and quantitative evaluations on various domains demonstrate that IPL effectively improves the quality and diversity of synthesized images and alleviates the mode collapse. Moreover, IPL is independent of the structure of the generative model, such as generative adversarial networks or diffusion models. Code is available at https://github.com/Picsart-AI-Research/IPL-Zero-Shot-Generative-Model-Adaptation.
Efficient Knowledge Distillation from Model Checkpoints
Oct 12, 2022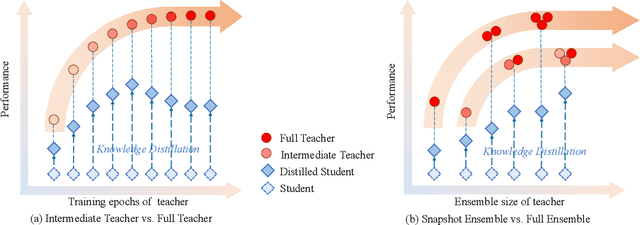
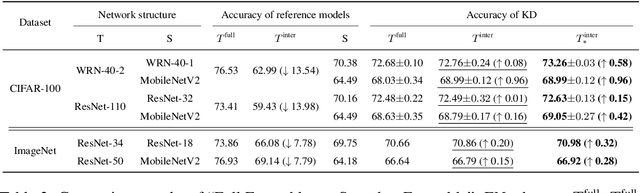
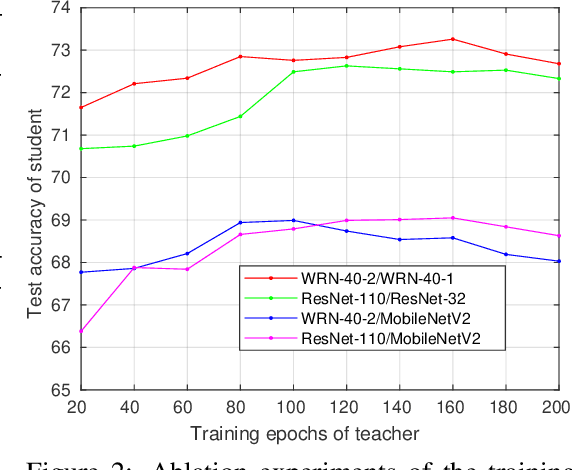
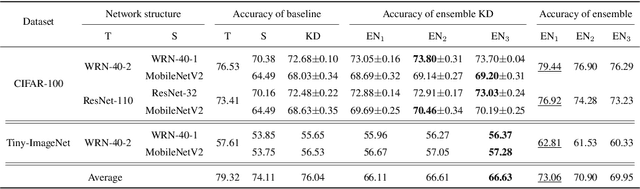
Knowledge distillation is an effective approach to learn compact models (students) with the supervision of large and strong models (teachers). As empirically there exists a strong correlation between the performance of teacher and student models, it is commonly believed that a high performing teacher is preferred. Consequently, practitioners tend to use a well trained network or an ensemble of them as the teacher. In this paper, we make an intriguing observation that an intermediate model, i.e., a checkpoint in the middle of the training procedure, often serves as a better teacher compared to the fully converged model, although the former has much lower accuracy. More surprisingly, a weak snapshot ensemble of several intermediate models from a same training trajectory can outperform a strong ensemble of independently trained and fully converged models, when they are used as teachers. We show that this phenomenon can be partially explained by the information bottleneck principle: the feature representations of intermediate models can have higher mutual information regarding the input, and thus contain more "dark knowledge" for effective distillation. We further propose an optimal intermediate teacher selection algorithm based on maximizing the total task-related mutual information. Experiments verify its effectiveness and applicability.
Learning to Weight Samples for Dynamic Early-exiting Networks
Sep 17, 2022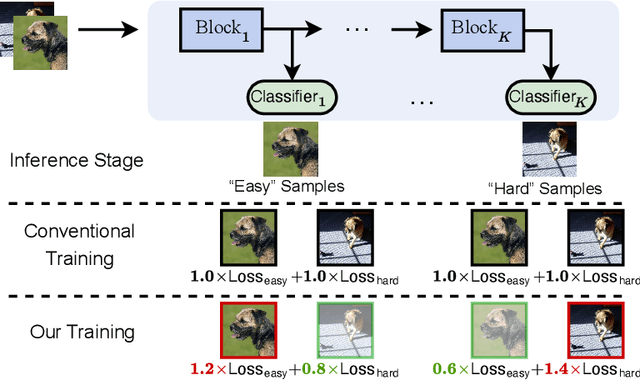
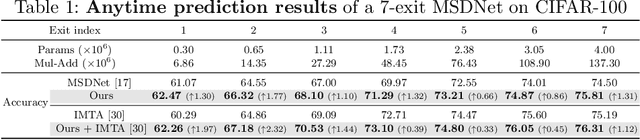

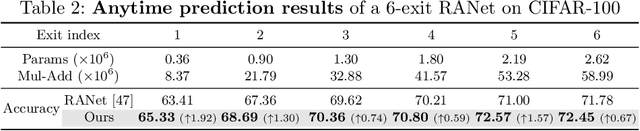
Early exiting is an effective paradigm for improving the inference efficiency of deep networks. By constructing classifiers with varying resource demands (the exits), such networks allow easy samples to be output at early exits, removing the need for executing deeper layers. While existing works mainly focus on the architectural design of multi-exit networks, the training strategies for such models are largely left unexplored. The current state-of-the-art models treat all samples the same during training. However, the early-exiting behavior during testing has been ignored, leading to a gap between training and testing. In this paper, we propose to bridge this gap by sample weighting. Intuitively, easy samples, which generally exit early in the network during inference, should contribute more to training early classifiers. The training of hard samples (mostly exit from deeper layers), however, should be emphasized by the late classifiers. Our work proposes to adopt a weight prediction network to weight the loss of different training samples at each exit. This weight prediction network and the backbone model are jointly optimized under a meta-learning framework with a novel optimization objective. By bringing the adaptive behavior during inference into the training phase, we show that the proposed weighting mechanism consistently improves the trade-off between classification accuracy and inference efficiency. Code is available at https://github.com/LeapLabTHU/L2W-DEN.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 31, 2022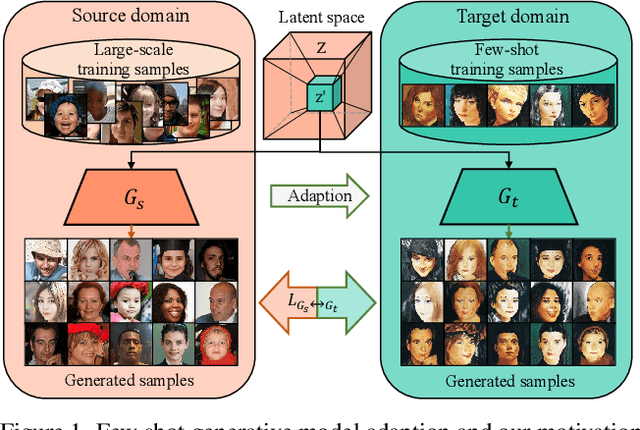
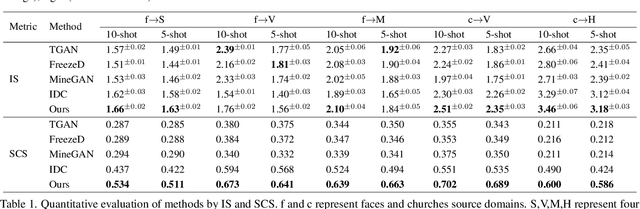
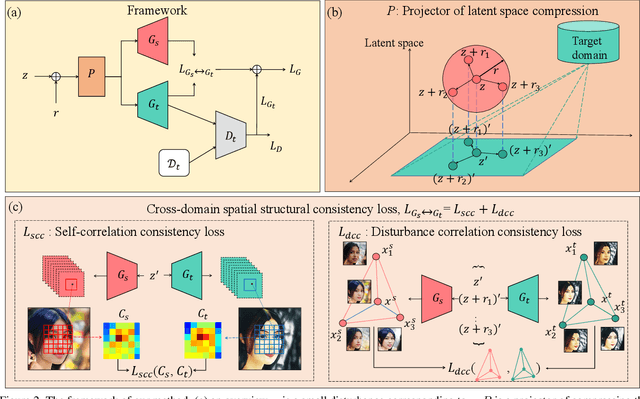

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
Learn From the Past: Experience Ensemble Knowledge Distillation
Feb 25, 2022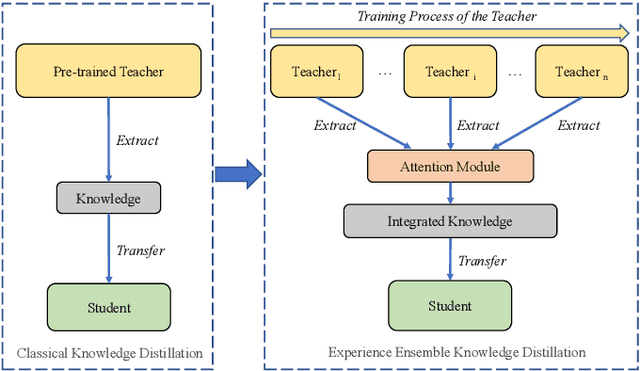
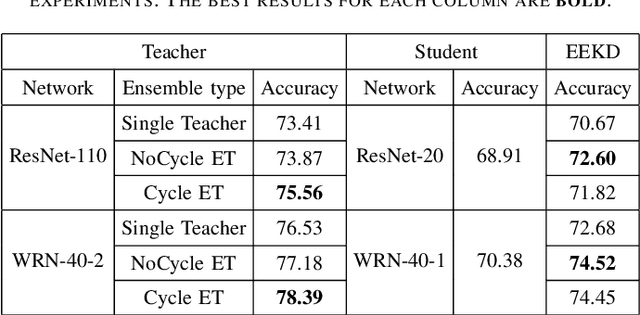
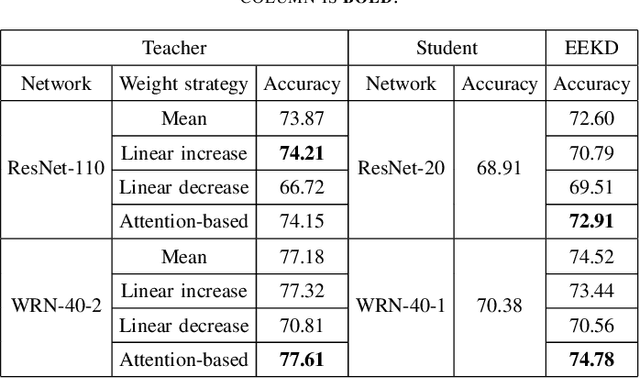
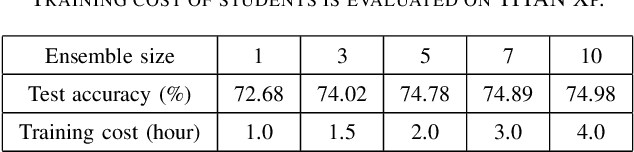
Traditional knowledge distillation transfers "dark knowledge" of a pre-trained teacher network to a student network, and ignores the knowledge in the training process of the teacher, which we call teacher's experience. However, in realistic educational scenarios, learning experience is often more important than learning results. In this work, we propose a novel knowledge distillation method by integrating the teacher's experience for knowledge transfer, named experience ensemble knowledge distillation (EEKD). We save a moderate number of intermediate models from the training process of the teacher model uniformly, and then integrate the knowledge of these intermediate models by ensemble technique. A self-attention module is used to adaptively assign weights to different intermediate models in the process of knowledge transfer. Three principles of constructing EEKD on the quality, weights and number of intermediate models are explored. A surprising conclusion is found that strong ensemble teachers do not necessarily produce strong students. The experimental results on CIFAR-100 and ImageNet show that EEKD outperforms the mainstream knowledge distillation methods and achieves the state-of-the-art. In particular, EEKD even surpasses the standard ensemble distillation on the premise of saving training cost.
Fine-Grained Few Shot Learning with Foreground Object Transformation
Sep 13, 2021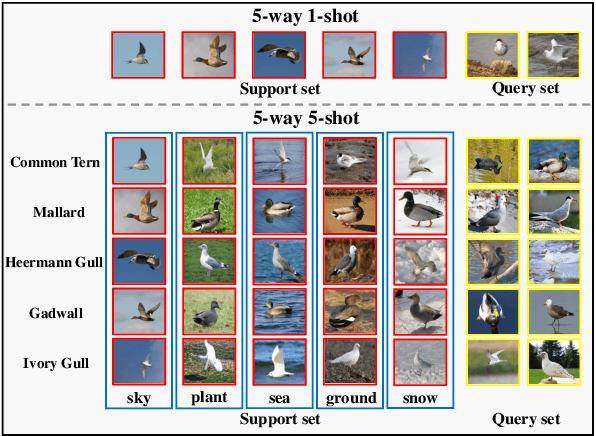
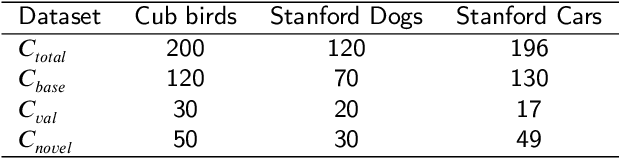
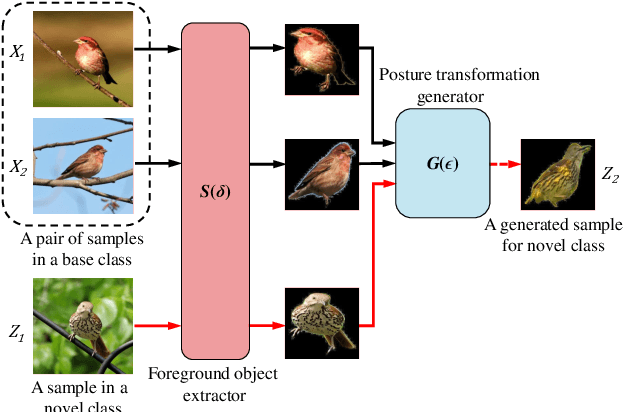
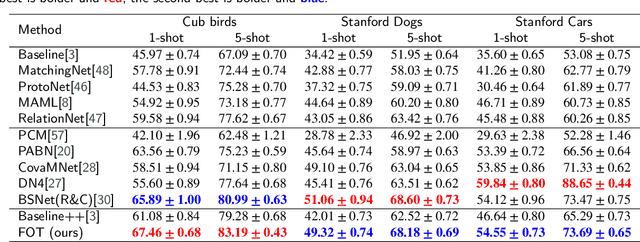
Traditional fine-grained image classification generally requires abundant labeled samples to deal with the low inter-class variance but high intra-class variance problem. However, in many scenarios we may have limited samples for some novel sub-categories, leading to the fine-grained few shot learning (FG-FSL) setting. To address this challenging task, we propose a novel method named foreground object transformation (FOT), which is composed of a foreground object extractor and a posture transformation generator. The former aims to remove image background, which tends to increase the difficulty of fine-grained image classification as it amplifies the intra-class variance while reduces inter-class variance. The latter transforms the posture of the foreground object to generate additional samples for the novel sub-category. As a data augmentation method, FOT can be conveniently applied to any existing few shot learning algorithm and greatly improve its performance on FG-FSL tasks. In particular, in combination with FOT, simple fine-tuning baseline methods can be competitive with the state-of-the-art methods both in inductive setting and transductive setting. Moreover, FOT can further boost the performances of latest excellent methods and bring them up to the new state-of-the-art. In addition, we also show the effectiveness of FOT on general FSL tasks.