 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation-efficient Deep Learning for Computer Vision: A Survey
Paper and Code
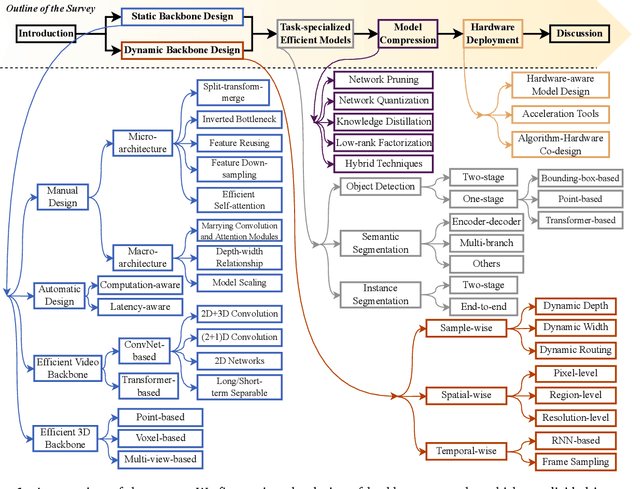
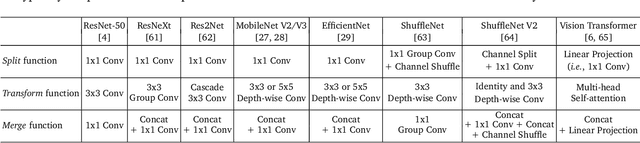
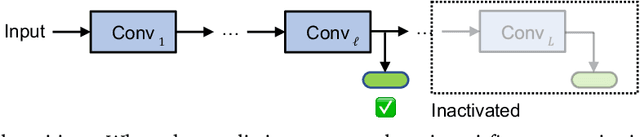
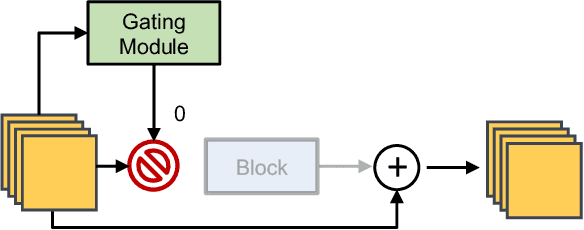
Over the past decade, deep learning models have exhibited considerable advancements, reaching or even exceeding human-level performance in a range of visual perception tasks. This remarkable progress has sparked interest in applying deep networks to real-world applications, such as autonomous vehicles, mobile devices, robotics, and edge computing. However, the challenge remains that state-of-the-art models usually demand significant computational resources, leading to impractical power consumption, latency, or carbon emissions in real-world scenarios. This trade-off between effectiveness and efficiency has catalyzed the emergence of a new research focus: computationally efficient deep learning, which strives to achieve satisfactory performance while minimizing the computational cost during inference. This review offers an extensive analysis of this rapidly evolving field by examining four key areas: 1) the development of static or dynamic light-weighted backbone models for the efficient extraction of discriminative deep representations; 2) the specialized network architectures or algorithms tailored for specific computer vision tasks; 3) the techniques employed for compressing deep learning models; and 4) the strategies for deploying efficient deep networks on hardware platforms. Additionally, we provide a systematic discussion on the critical challenges faced in this domain, such as network architecture design, training schemes, practical efficiency, and more realistic model compression approaches, as well as potential future research directions.