 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELF-EMO: Emotional Self-Evolution from Recognition to Consistent Expression
Apr 20, 2026Emotion Recognition in Conversation (ERC) has become a fundamental capability for large language models (LLMs) in human-centric interaction. Beyond accurate recognition, coherent emotional expression is also crucial, yet both are limited by the scarcity and static nature of high-quality annotated data. In this work, we propose SELF-EMO, a self-evolution framework grounded in the hypothesis that better emotion prediction leads to more consistent emotional responses. We introduce two auxiliary tasks, emotional understanding and emotional expression, and design a role-based self-play paradigm where the model acts as both an emotion recognizer and a dialogue responder. Through iterative interactions, the model generates diverse conversational trajectories, enabling scalable data generation. To ensure quality, we adopt a data flywheel mechanism that filters candidate predictions and responses using a smoothed IoU-based reward and feeds selected samples back for continuous self-improvement without external supervision. We further develop SELF-GRPO, a reinforcement learning algorithm that stabilizes optimization with multi-label alignment rewards and group-level consistency signals. Experiments on IEMOCAP, MELD, and EmoryNLP show that SELF-EMO achieves state-of-the-art performance, improving accuracy by +6.33% on Qwen3-4B and +8.54% on Qwen3-8B, demonstrating strong effectiveness and generalization.
DEP: A Decentralized Large Language Model Evaluation Protocol
Mar 01, 2026With the rapid development of Large Language Models (LLMs), a large number of benchmarks have been proposed. However, most benchmarks lack unified evaluation standard and require the manual implementation of custom scripts, making results hard to ensure consistency and reproducibility. Furthermore, mainstream evaluation frameworks are centralized, with datasets and answers, which increases the risk of benchmark leakage. To address these issues, we propose a Decentralized Evaluation Protocol (DEP), a decentralized yet unified and standardized evaluation framework through a matching server without constraining benchmarks. The server can be mounted locally or deployed remotely, and once adapted, it can be reused over the long term. By decoupling users, LLMs, and benchmarks, DEP enables modular, plug-and-play evaluation: benchmark files and evaluation logic stay exclusively on the server side. In remote setting, users cannot access the ground truth, thereby achieving data isolation and leak-proof evaluation. To facilitate practical adoption, we develop DEP Toolkit, a protocol-compatible toolkit that supports features such as breakpoint resume, concurrent requests, and congestion control. We also provide detailed documentation for adapting new benchmarks to DEP. Using DEP toolkit, we evaluate multiple LLMs across benchmarks. Experimental results verify the effectiveness of DEP and show that it reduces the cost of deploying benchmark evaluations. As of February 2026, we have adapted over 60 benchmarks and continue to promote community co-construction to support unified evaluation across various tasks and domains.
Self-Motivated Multi-Agent Exploration
Jan 05, 2023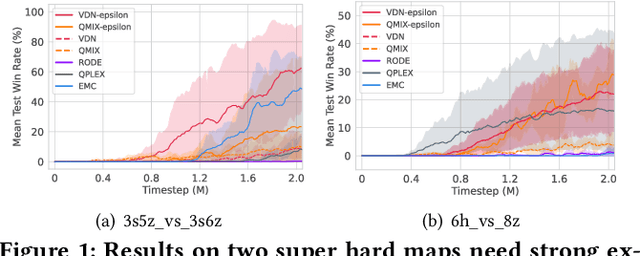

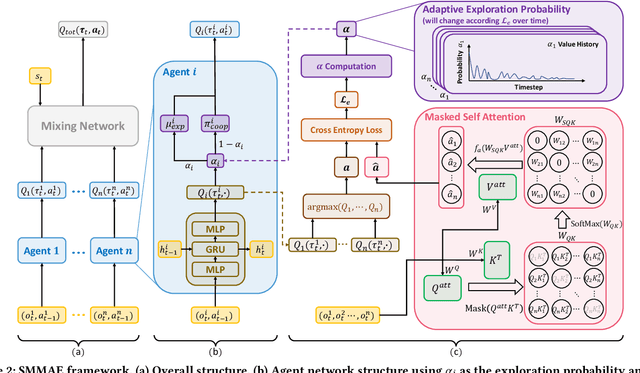
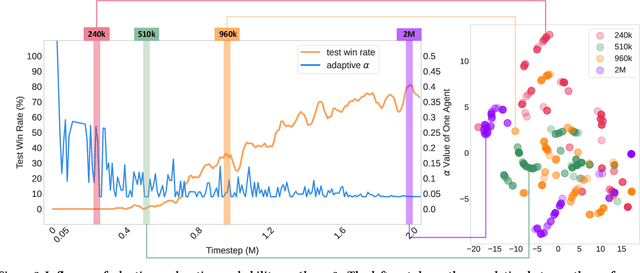
In cooperative multi-agent reinforcement learning (CMARL), it is critical for agents to achieve a balance between self-exploration and team collaboration. However, agents can hardly accomplish the team task without coordination and they would be trapped in a local optimum where easy cooperation is accessed without enough individual exploration. Recent works mainly concentrate on agents' coordinated exploration, which brings about the exponentially grown exploration of the state space. To address this issue, we propose Self-Motivated Multi-Agent Exploration (SMMAE), which aims to achieve success in team tasks by adaptively finding a trade-off between self-exploration and team cooperation. In SMMAE, we train an independent exploration policy for each agent to maximize their own visited state space. Each agent learns an adjustable exploration probability based on the stability of the joint team policy. The experiments on highly cooperative tasks in StarCraft II micromanagement benchmark (SMAC) demonstrate that SMMAE can explore task-related states more efficiently, accomplish coordinated behaviours and boost the learning performance.
Learn From the Past: Experience Ensemble Knowledge Distillation
Feb 25, 2022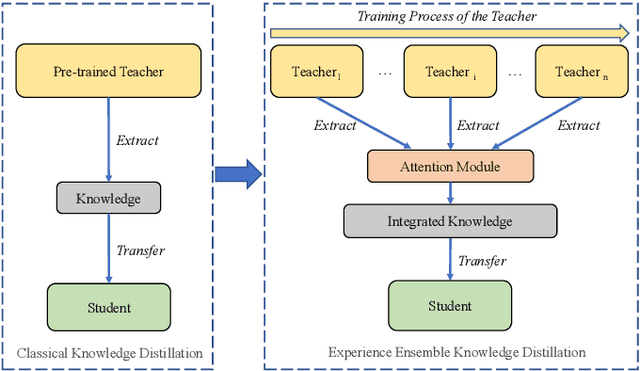
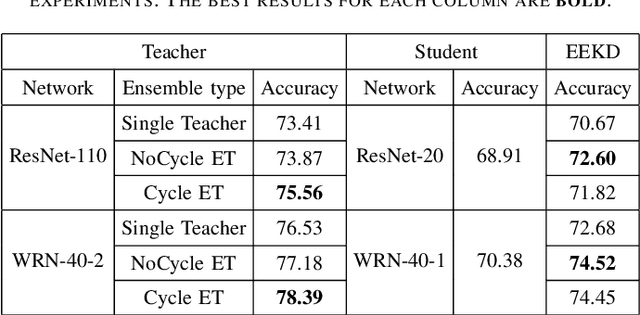
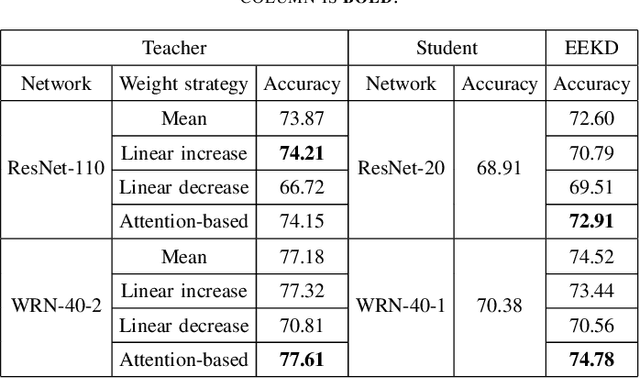
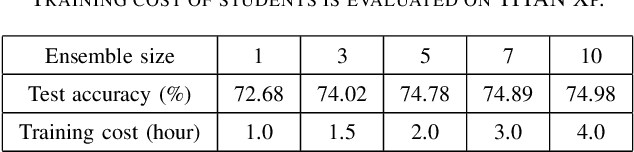
Traditional knowledge distillation transfers "dark knowledge" of a pre-trained teacher network to a student network, and ignores the knowledge in the training process of the teacher, which we call teacher's experience. However, in realistic educational scenarios, learning experience is often more important than learning results. In this work, we propose a novel knowledge distillation method by integrating the teacher's experience for knowledge transfer, named experience ensemble knowledge distillation (EEKD). We save a moderate number of intermediate models from the training process of the teacher model uniformly, and then integrate the knowledge of these intermediate models by ensemble technique. A self-attention module is used to adaptively assign weights to different intermediate models in the process of knowledge transfer. Three principles of constructing EEKD on the quality, weights and number of intermediate models are explored. A surprising conclusion is found that strong ensemble teachers do not necessarily produce strong students. The experimental results on CIFAR-100 and ImageNet show that EEKD outperforms the mainstream knowledge distillation methods and achieves the state-of-the-art. In particular, EEKD even surpasses the standard ensemble distillation on the premise of saving training cost.
LINDA: Multi-Agent Local Information Decomposition for Awareness of Teammates
Oct 15, 2021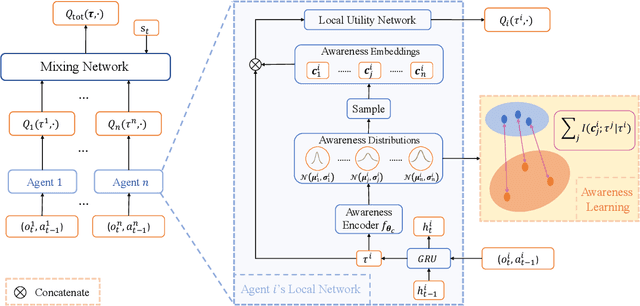


In cooperative multi-agent reinforcement learning (MARL), where agents only have access to partial observations, efficiently leveraging local information is critical. During long-time observations, agents can build \textit{awareness} for teammates to alleviate the problem of partial observability. However, previous MARL methods usually neglect this kind of utilization of local information. To address this problem, we propose a novel framework, multi-agent \textit{Local INformation Decomposition for Awareness of teammates} (LINDA), with which agents learn to decompose local information and build awareness for each teammate. We model the awareness as stochastic random variables and perform representation learning to ensure the informativeness of awareness representations by maximizing the mutual information between awareness and the actual trajectory of the corresponding agent. LINDA is agnostic to specific algorithms and can be flexibly integrated to different MARL methods. Sufficient experiments show that the proposed framework learns informative awareness from local partial observations for better collaboration and significantly improves the learning performance, especially on challenging tasks.