 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRICKS-WM: Building Reusability via Interface Composition Kinetics for Structured World Models
Jun 15, 2026Model-based Reinforcement Learning (MBRL) has achieved remarkable success in continuous control by leveraging latent world models. However, prevailing approaches typically rely on monolithic latent dynamics, entangling environment dynamics into a coupled process. This coupling severely limits reusability: altering the agent necessitates retraining the entire world from scratch, even if the environment remains constant. To address this, we introduce BRICKS-WM (Building Reusability via Interface Composition Kinetics for Structured World Models), a framework for the modular assembly of structured world models. Driven by the insight that the physical world is composed of independent entities, we posit that global dynamics can be modeled as a composition of distinct dynamical modules interacting via latent interfaces. As a minimal instantiation, we factorize the latent state space into an actuated Agent module and an external Background module, bridged by a learned latent interface. Unlike prior object-centric methods that prioritize visual segmentation, BRICKS-WM enforces a functional separation in transition dynamics, ensuring that background dynamics remains agnostic to the agent's dynamics. Empirically, BRICKS-WM achieves control performance comparable to strong monolithic baselines when trained from scratch, and enables the reuse of frozen background dynamics across agents.
Self-Motivated Multi-Agent Exploration
Jan 05, 2023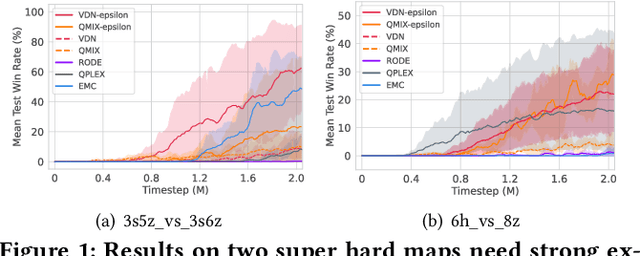

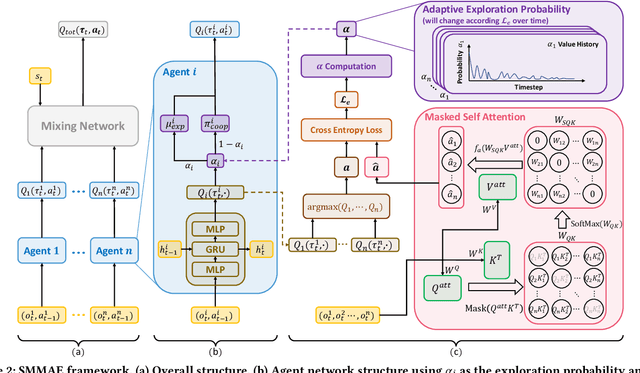
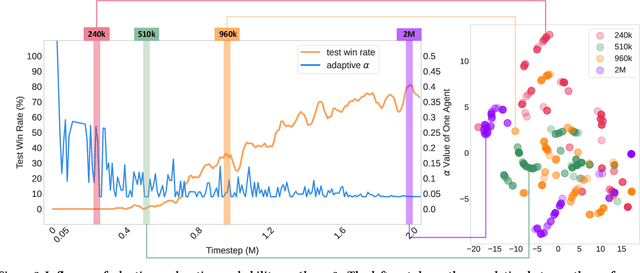
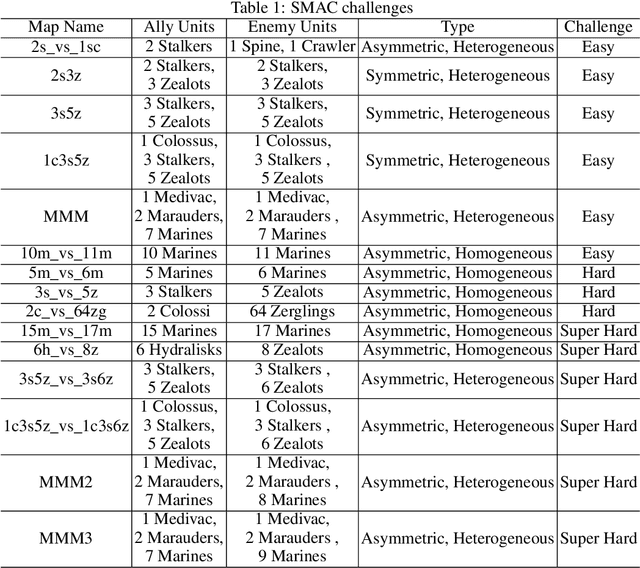
In cooperative multi-agent reinforcement learning (CMARL), it is critical for agents to achieve a balance between self-exploration and team collaboration. However, agents can hardly accomplish the team task without coordination and they would be trapped in a local optimum where easy cooperation is accessed without enough individual exploration. Recent works mainly concentrate on agents' coordinated exploration, which brings about the exponentially grown exploration of the state space. To address this issue, we propose Self-Motivated Multi-Agent Exploration (SMMAE), which aims to achieve success in team tasks by adaptively finding a trade-off between self-exploration and team cooperation. In SMMAE, we train an independent exploration policy for each agent to maximize their own visited state space. Each agent learns an adjustable exploration probability based on the stability of the joint team policy. The experiments on highly cooperative tasks in StarCraft II micromanagement benchmark (SMAC) demonstrate that SMMAE can explore task-related states more efficiently, accomplish coordinated behaviours and boost the learning performance.
LINDA: Multi-Agent Local Information Decomposition for Awareness of Teammates
Oct 15, 2021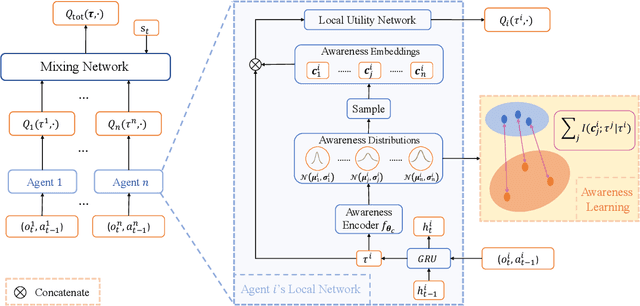


In cooperative multi-agent reinforcement learning (MARL), where agents only have access to partial observations, efficiently leveraging local information is critical. During long-time observations, agents can build \textit{awareness} for teammates to alleviate the problem of partial observability. However, previous MARL methods usually neglect this kind of utilization of local information. To address this problem, we propose a novel framework, multi-agent \textit{Local INformation Decomposition for Awareness of teammates} (LINDA), with which agents learn to decompose local information and build awareness for each teammate. We model the awareness as stochastic random variables and perform representation learning to ensure the informativeness of awareness representations by maximizing the mutual information between awareness and the actual trajectory of the corresponding agent. LINDA is agnostic to specific algorithms and can be flexibly integrated to different MARL methods. Sufficient experiments show that the proposed framework learns informative awareness from local partial observations for better collaboration and significantly improves the learning performance, especially on challenging tasks.