 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying UDM Series in Real-Life Stuttered Speech Applications: A Clinical Evaluation Framework
Sep 17, 2025Stuttered and dysfluent speech detection systems have traditionally suffered from the trade-off between accuracy and clinical interpretability. While end-to-end deep learning models achieve high performance, their black-box nature limits clinical adoption. This paper looks at the Unconstrained Dysfluency Modeling (UDM) series-the current state-of-the-art framework developed by Berkeley that combines modular architecture, explicit phoneme alignment, and interpretable outputs for real-world clinical deployment. Through extensive experiments involving patients and certified speech-language pathologists (SLPs), we demonstrate that UDM achieves state-of-the-art performance (F1: 0.89+-0.04) while providing clinically meaningful interpretability scores (4.2/5.0). Our deployment study shows 87% clinician acceptance rate and 34% reduction in diagnostic time. The results provide strong evidence that UDM represents a practical pathway toward AI-assisted speech therapy in clinical environments.
Can Gradient Descent Simulate Prompting?
Jun 26, 2025There are two primary ways of incorporating new information into a language model (LM): changing its prompt or changing its parameters, e.g. via fine-tuning. Parameter updates incur no long-term storage cost for model changes. However, for many model updates, prompting is significantly more effective: prompted models can generalize robustly from single examples and draw logical inferences that do not occur under standard fine-tuning. Can models be modified so that fine-tuning does emulate prompting? This paper describes a method for meta-training LMs such that gradient updates emulate the effects of conditioning on new information. Our approach uses tools from gradient-based meta-learning but uses an LM's own prompted predictions as targets, eliminating the need for ground-truth labels. Subsequent gradient descent training recovers some (and occasionally all) of prompted model performance -- showing improvement on the ``reversal curse'' tasks, and answering questions about text passages after a single gradient update. These results suggest that, with appropriate initialization, gradient descent can be surprisingly expressive. Our results suggest new avenues for long-context modeling and offer insight into the generalization capabilities of gradient-based learning.
Unforgettable Generalization in Language Models
Sep 03, 2024



When language models (LMs) are trained to forget (or "unlearn'') a skill, how precisely does their behavior change? We study the behavior of transformer LMs in which tasks have been forgotten via fine-tuning on randomized labels. Such LMs learn to generate near-random predictions for individual examples in the "training'' set used for forgetting. Across tasks, however, LMs exhibit extreme variability in whether LM predictions change on examples outside the training set. In some tasks (like entailment classification), forgetting generalizes robustly, and causes models to produce uninformative predictions on new task instances; in other tasks (like physical commonsense reasoning and scientific question answering) forgetting affects only the training examples, and models continue to perform the "forgotten'' task accurately even for examples very similar to those that appeared in the training set. Dataset difficulty is not predictive of whether a behavior can be forgotten; instead, generalization in forgetting is (weakly) predicted by the confidence of LMs' initial task predictions and the variability of LM representations of training data, with low confidence and low variability both associated with greater generalization. Perhaps most surprisingly, random-label forgetting appears to be somewhat insensitive to the contents of the training set: for example, models trained on science questions with random labels continue to answer other science questions accurately, but begin to produce random labels on entailment classification tasks. Finally, we show that even generalizable forgetting is shallow: linear probes trained on LMs' representations can still perform tasks reliably after forgetting. Our results highlight the difficulty and unpredictability of performing targeted skill removal from models via fine-tuning.
* 18 pages, 9 figures, published in First Conference on Language Modeling 2024
Ragnarök: A Reusable RAG Framework and Baselines for TREC 2024 Retrieval-Augmented Generation Track
Jun 24, 2024Did you try out the new Bing Search? Or maybe you fiddled around with Google AI~Overviews? These might sound familiar because the modern-day search stack has recently evolved to include retrieval-augmented generation (RAG) systems. They allow searching and incorporating real-time data into large language models (LLMs) to provide a well-informed, attributed, concise summary in contrast to the traditional search paradigm that relies on displaying a ranked list of documents. Therefore, given these recent advancements, it is crucial to have an arena to build, test, visualize, and systematically evaluate RAG-based search systems. With this in mind, we propose the TREC 2024 RAG Track to foster innovation in evaluating RAG systems. In our work, we lay out the steps we've made towards making this track a reality -- we describe the details of our reusable framework, Ragnar\"ok, explain the curation of the new MS MARCO V2.1 collection choice, release the development topics for the track, and standardize the I/O definitions which assist the end user. Next, using Ragnar\"ok, we identify and provide key industrial baselines such as OpenAI's GPT-4o or Cohere's Command R+. Further, we introduce a web-based user interface for an interactive arena allowing benchmarking pairwise RAG systems by crowdsourcing. We open-source our Ragnar\"ok framework and baselines to achieve a unified standard for future RAG systems.
Point-PEFT: Parameter-Efficient Fine-Tuning for 3D Pre-trained Models
Oct 04, 2023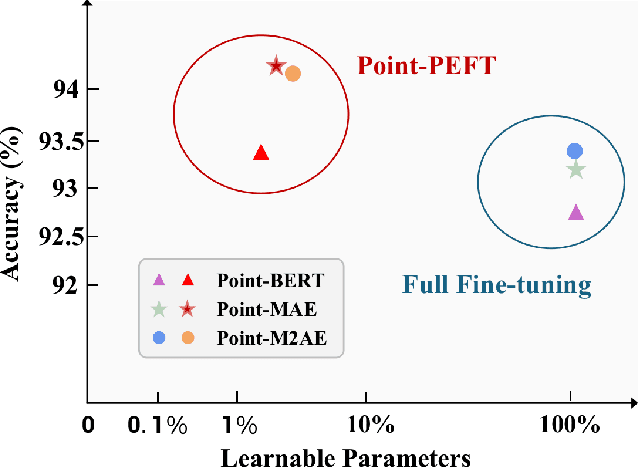
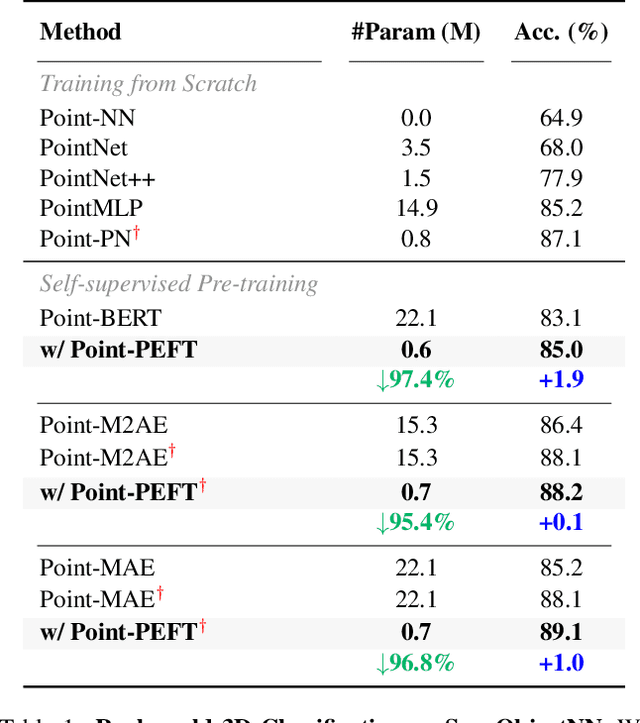
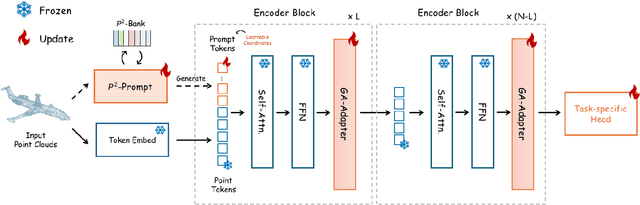
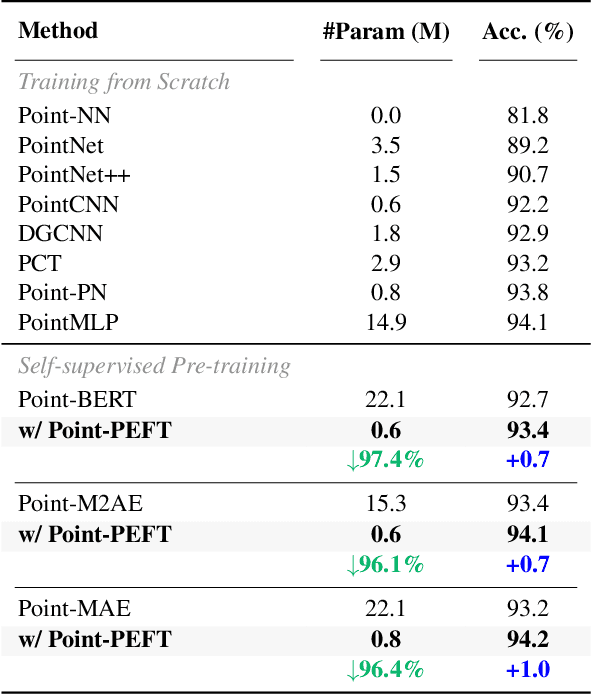
The popularity of pre-trained large models has revolutionized downstream tasks across diverse fields, such as language, vision, and multi-modality. To minimize the adaption cost for downstream tasks, many Parameter-Efficient Fine-Tuning (PEFT) techniques are proposed for language and 2D image pre-trained models. However, the specialized PEFT method for 3D pre-trained models is still under-explored. To this end, we introduce Point-PEFT, a novel framework for adapting point cloud pre-trained models with minimal learnable parameters. Specifically, for a pre-trained 3D model, we freeze most of its parameters, and only tune the newly added PEFT modules on downstream tasks, which consist of a Point-prior Prompt and a Geometry-aware Adapter. The Point-prior Prompt adopts a set of learnable prompt tokens, for which we propose to construct a memory bank with domain-specific knowledge, and utilize a parameter-free attention to enhance the prompt tokens. The Geometry-aware Adapter aims to aggregate point cloud features within spatial neighborhoods to capture fine-grained geometric information through local interactions. Extensive experiments indicate that our Point-PEFT can achieve better performance than the full fine-tuning on various downstream tasks, while using only 5% of the trainable parameters, demonstrating the efficiency and effectiveness of our approach. Code will be released at https://github.com/EvenJoker/Point-PEFT.
Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
Apr 06, 2023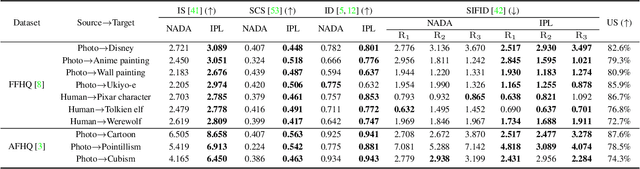
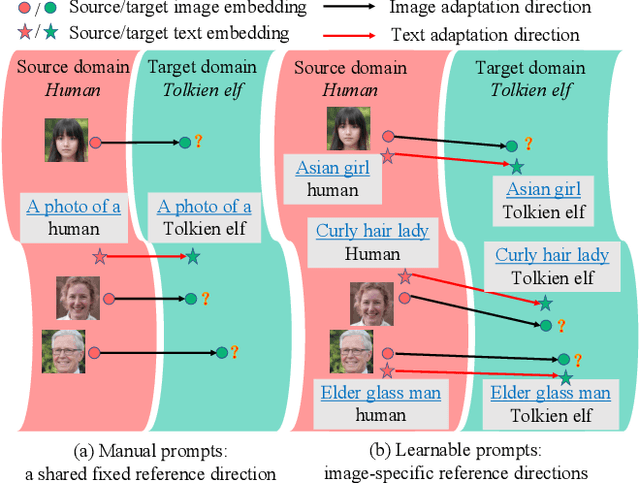
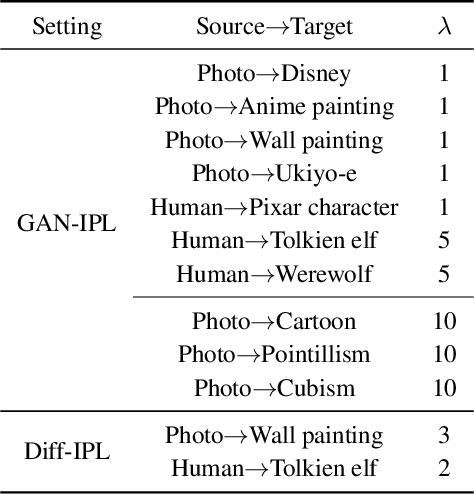
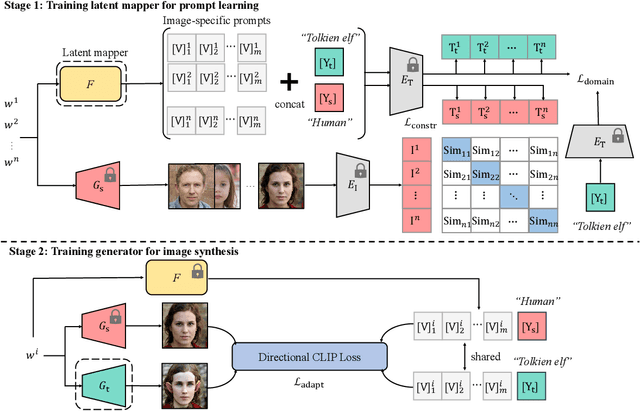
Recently, CLIP-guided image synthesis has shown appealing performance on adapting a pre-trained source-domain generator to an unseen target domain. It does not require any target-domain samples but only the textual domain labels. The training is highly efficient, e.g., a few minutes. However, existing methods still have some limitations in the quality of generated images and may suffer from the mode collapse issue. A key reason is that a fixed adaptation direction is applied for all cross-domain image pairs, which leads to identical supervision signals. To address this issue, we propose an Image-specific Prompt Learning (IPL) method, which learns specific prompt vectors for each source-domain image. This produces a more precise adaptation direction for every cross-domain image pair, endowing the target-domain generator with greatly enhanced flexibility. Qualitative and quantitative evaluations on various domains demonstrate that IPL effectively improves the quality and diversity of synthesized images and alleviates the mode collapse. Moreover, IPL is independent of the structure of the generative model, such as generative adversarial networks or diffusion models. Code is available at https://github.com/Picsart-AI-Research/IPL-Zero-Shot-Generative-Model-Adaptation.
Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
Mar 30, 2023



The unlearning problem of deep learning models, once primarily an academic concern, has become a prevalent issue in the industry. The significant advances in text-to-image generation techniques have prompted global discussions on privacy, copyright, and safety, as numerous unauthorized personal IDs, content, artistic creations, and potentially harmful materials have been learned by these models and later utilized to generate and distribute uncontrolled content. To address this challenge, we propose \textbf{Forget-Me-Not}, an efficient and low-cost solution designed to safely remove specified IDs, objects, or styles from a well-configured text-to-image model in as little as 30 seconds, without impairing its ability to generate other content. Alongside our method, we introduce the \textbf{Memorization Score (M-Score)} and \textbf{ConceptBench} to measure the models' capacity to generate general concepts, grouped into three primary categories: ID, object, and style. Using M-Score and ConceptBench, we demonstrate that Forget-Me-Not can effectively eliminate targeted concepts while maintaining the model's performance on other concepts. Furthermore, Forget-Me-Not offers two practical extensions: a) removal of potentially harmful or NSFW content, and b) enhancement of model accuracy, inclusion and diversity through \textbf{concept correction and disentanglement}. It can also be adapted as a lightweight model patch for Stable Diffusion, allowing for concept manipulation and convenient distribution. To encourage future research in this critical area and promote the development of safe and inclusive generative models, we will open-source our code and ConceptBench at \href{https://github.com/SHI-Labs/Forget-Me-Not}{https://github.com/SHI-Labs/Forget-Me-Not}.
Versatile Diffusion: Text, Images and Variations All in One Diffusion Model
Nov 20, 2022The recent advances in diffusion models have set an impressive milestone in many generation tasks. Trending works such as DALL-E2, Imagen, and Stable Diffusion have attracted great interest in academia and industry. Despite the rapid landscape changes, recent new approaches focus on extensions and performance rather than capacity, thus requiring separate models for separate tasks. In this work, we expand the existing single-flow diffusion pipeline into a multi-flow network, dubbed Versatile Diffusion (VD), that handles text-to-image, image-to-text, image-variation, and text-variation in one unified model. Moreover, we generalize VD to a unified multi-flow multimodal diffusion framework with grouped layers, swappable streams, and other propositions that can process modalities beyond images and text. Through our experiments, we demonstrate that VD and its underlying framework have the following merits: a) VD handles all subtasks with competitive quality; b) VD initiates novel extensions and applications such as disentanglement of style and semantic, image-text dual-guided generation, etc.; c) Through these experiments and applications, VD provides more semantic insights of the generated outputs. Our code and models are open-sourced at https://github.com/SHI-Labs/Versatile-Diffusion.