 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRerank Before You Reason: Analyzing Reranking Tradeoffs through Effective Token Cost in Deep Search Agents
Jan 20, 2026Deep research agents rely on iterative retrieval and reasoning to answer complex queries, but scaling test-time computation raises significant efficiency concerns. We study how to allocate reasoning budget in deep search pipelines, focusing on the role of listwise reranking. Using the BrowseComp-Plus benchmark, we analyze tradeoffs between model scale, reasoning effort, reranking depth, and total token cost via a novel effective token cost (ETC) metric. Our results show that reranking consistently improves retrieval and end-to-end accuracy, and that moderate reranking often yields larger gains than increasing search-time reasoning, achieving comparable accuracy at substantially lower cost. All our code is available at https://github.com/texttron/BrowseComp-Plus.git
RankLLM: A Python Package for Reranking with LLMs
May 25, 2025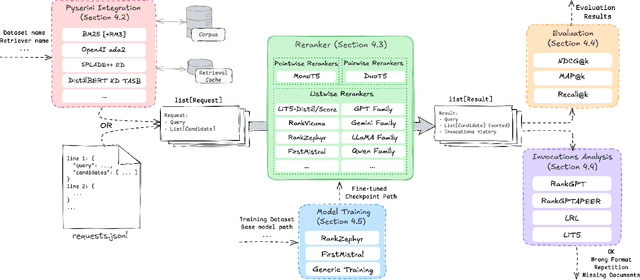
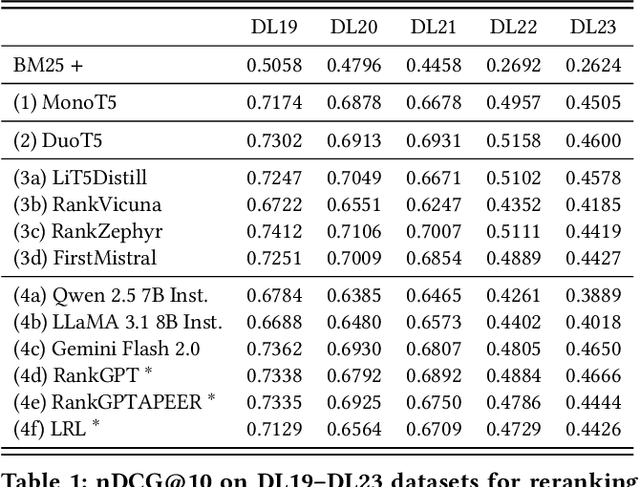
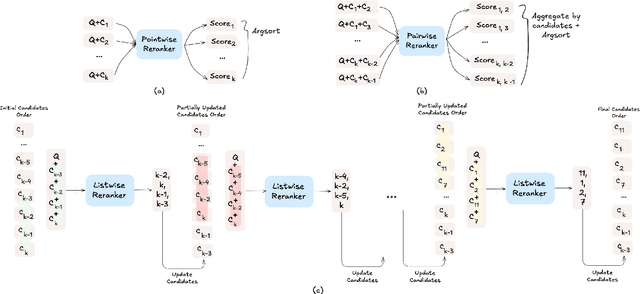
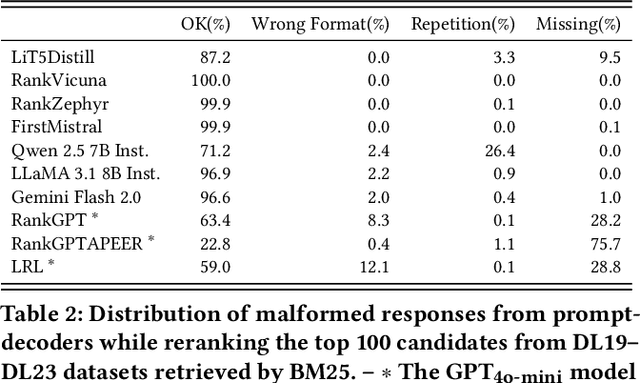
The adoption of large language models (LLMs) as rerankers in multi-stage retrieval systems has gained significant traction in academia and industry. These models refine a candidate list of retrieved documents, often through carefully designed prompts, and are typically used in applications built on retrieval-augmented generation (RAG). This paper introduces RankLLM, an open-source Python package for reranking that is modular, highly configurable, and supports both proprietary and open-source LLMs in customized reranking workflows. To improve usability, RankLLM features optional integration with Pyserini for retrieval and provides integrated evaluation for multi-stage pipelines. Additionally, RankLLM includes a module for detailed analysis of input prompts and LLM responses, addressing reliability concerns with LLM APIs and non-deterministic behavior in Mixture-of-Experts (MoE) models. This paper presents the architecture of RankLLM, along with a detailed step-by-step guide and sample code. We reproduce results from RankGPT, LRL, RankVicuna, RankZephyr, and other recent models. RankLLM integrates with common inference frameworks and a wide range of LLMs. This compatibility allows for quick reproduction of reported results, helping to speed up both research and real-world applications. The complete repository is available at rankllm.ai, and the package can be installed via PyPI.
Chatbot Arena Meets Nuggets: Towards Explanations and Diagnostics in the Evaluation of LLM Responses
Apr 28, 2025Battles, or side-by-side comparisons in so called arenas that elicit human preferences, have emerged as a popular approach to assessing the output quality of LLMs. Recently, this idea has been extended to retrieval-augmented generation (RAG) systems. While undoubtedly representing an advance in evaluation, battles have at least two drawbacks, particularly in the context of complex information-seeking queries: they are neither explanatory nor diagnostic. Recently, the nugget evaluation methodology has emerged as a promising approach to evaluate the quality of RAG answers. Nuggets decompose long-form LLM-generated answers into atomic facts, highlighting important pieces of information necessary in a "good" response. In this work, we apply our AutoNuggetizer framework to analyze data from roughly 7K Search Arena battles provided by LMArena in a fully automatic manner. Our results show a significant correlation between nugget scores and human preferences, showcasing promise in our approach to explainable and diagnostic system evaluations.
Ragnarök: A Reusable RAG Framework and Baselines for TREC 2024 Retrieval-Augmented Generation Track
Jun 24, 2024Did you try out the new Bing Search? Or maybe you fiddled around with Google AI~Overviews? These might sound familiar because the modern-day search stack has recently evolved to include retrieval-augmented generation (RAG) systems. They allow searching and incorporating real-time data into large language models (LLMs) to provide a well-informed, attributed, concise summary in contrast to the traditional search paradigm that relies on displaying a ranked list of documents. Therefore, given these recent advancements, it is crucial to have an arena to build, test, visualize, and systematically evaluate RAG-based search systems. With this in mind, we propose the TREC 2024 RAG Track to foster innovation in evaluating RAG systems. In our work, we lay out the steps we've made towards making this track a reality -- we describe the details of our reusable framework, Ragnar\"ok, explain the curation of the new MS MARCO V2.1 collection choice, release the development topics for the track, and standardize the I/O definitions which assist the end user. Next, using Ragnar\"ok, we identify and provide key industrial baselines such as OpenAI's GPT-4o or Cohere's Command R+. Further, we introduce a web-based user interface for an interactive arena allowing benchmarking pairwise RAG systems by crowdsourcing. We open-source our Ragnar\"ok framework and baselines to achieve a unified standard for future RAG systems.
UniRAG: Universal Retrieval Augmentation for Multi-Modal Large Language Models
May 16, 2024



Recently, Multi-Modal(MM) Large Language Models(LLMs) have unlocked many complex use-cases that require MM understanding (e.g., image captioning or visual question answering) and MM generation (e.g., text-guided image generation or editing) capabilities. To further improve the output fidelity of MM-LLMs we introduce the model-agnostic UniRAG technique that adds relevant retrieved information to prompts as few-shot examples during inference. Unlike the common belief that Retrieval Augmentation (RA) mainly improves generation or understanding of uncommon entities, our evaluation results on the MSCOCO dataset with common entities show that both proprietary models like GPT4 and Gemini-Pro and smaller open-source models like Llava, LaVIT, and Emu2 significantly enhance their generation quality when their input prompts are augmented with relevant information retrieved by MM retrievers like UniIR models.
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze!
Dec 05, 2023



In information retrieval, proprietary large language models (LLMs) such as GPT-4 and open-source counterparts such as LLaMA and Vicuna have played a vital role in reranking. However, the gap between open-source and closed models persists, with reliance on proprietary, non-transparent models constraining reproducibility. Addressing this gap, we introduce RankZephyr, a state-of-the-art, open-source LLM for listwise zero-shot reranking. RankZephyr not only bridges the effectiveness gap with GPT-4 but in some cases surpasses the proprietary model. Our comprehensive evaluations across several datasets (TREC Deep Learning Tracks; NEWS and COVID from BEIR) showcase this ability. RankZephyr benefits from strategic training choices and is resilient against variations in initial document ordering and the number of documents reranked. Additionally, our model outperforms GPT-4 on the NovelEval test set, comprising queries and passages past its training period, which addresses concerns about data contamination. To foster further research in this rapidly evolving field, we provide all code necessary to reproduce our results at https://github.com/castorini/rank_llm.
RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models
Sep 26, 2023



Researchers have successfully applied large language models (LLMs) such as ChatGPT to reranking in an information retrieval context, but to date, such work has mostly been built on proprietary models hidden behind opaque API endpoints. This approach yields experimental results that are not reproducible and non-deterministic, threatening the veracity of outcomes that build on such shaky foundations. To address this significant shortcoming, we present RankVicuna, the first fully open-source LLM capable of performing high-quality listwise reranking in a zero-shot setting. Experimental results on the TREC 2019 and 2020 Deep Learning Tracks show that we can achieve effectiveness comparable to zero-shot reranking with GPT-3.5 with a much smaller 7B parameter model, although our effectiveness remains slightly behind reranking with GPT-4. We hope our work provides the foundation for future research on reranking with modern LLMs. All the code necessary to reproduce our results is available at https://github.com/castorini/rank_llm.