 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing Data That Hurts Performance: Cascading LLMs to Relabel Hard Negatives for Robust Information Retrieval
May 22, 2025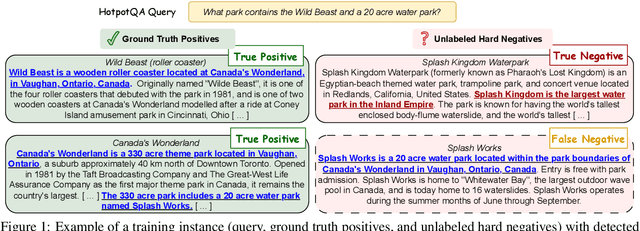
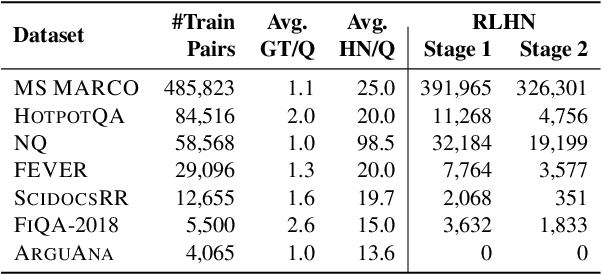
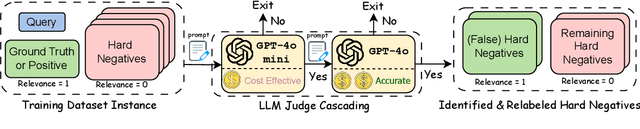
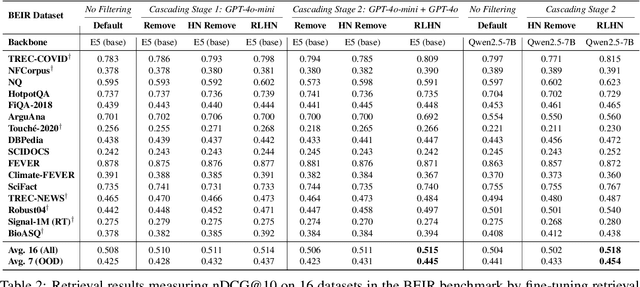
Training robust retrieval and reranker models typically relies on large-scale retrieval datasets; for example, the BGE collection contains 1.6 million query-passage pairs sourced from various data sources. However, we find that certain datasets can negatively impact model effectiveness -- pruning 8 out of 15 datasets from the BGE collection reduces the training set size by 2.35$\times$ and increases nDCG@10 on BEIR by 1.0 point. This motivates a deeper examination of training data quality, with a particular focus on "false negatives", where relevant passages are incorrectly labeled as irrelevant. We propose a simple, cost-effective approach using cascading LLM prompts to identify and relabel hard negatives. Experimental results show that relabeling false negatives with true positives improves both E5 (base) and Qwen2.5-7B retrieval models by 0.7-1.4 nDCG@10 on BEIR and by 1.7-1.8 nDCG@10 on zero-shot AIR-Bench evaluation. Similar gains are observed for rerankers fine-tuned on the relabeled data, such as Qwen2.5-3B on BEIR. The reliability of the cascading design is further supported by human annotation results, where we find judgment by GPT-4o shows much higher agreement with humans than GPT-4o-mini.
Chatbot Arena Meets Nuggets: Towards Explanations and Diagnostics in the Evaluation of LLM Responses
Apr 28, 2025Battles, or side-by-side comparisons in so called arenas that elicit human preferences, have emerged as a popular approach to assessing the output quality of LLMs. Recently, this idea has been extended to retrieval-augmented generation (RAG) systems. While undoubtedly representing an advance in evaluation, battles have at least two drawbacks, particularly in the context of complex information-seeking queries: they are neither explanatory nor diagnostic. Recently, the nugget evaluation methodology has emerged as a promising approach to evaluate the quality of RAG answers. Nuggets decompose long-form LLM-generated answers into atomic facts, highlighting important pieces of information necessary in a "good" response. In this work, we apply our AutoNuggetizer framework to analyze data from roughly 7K Search Arena battles provided by LMArena in a fully automatic manner. Our results show a significant correlation between nugget scores and human preferences, showcasing promise in our approach to explainable and diagnostic system evaluations.
The Great Nugget Recall: Automating Fact Extraction and RAG Evaluation with Large Language Models
Apr 21, 2025



Large Language Models (LLMs) have significantly enhanced the capabilities of information access systems, especially with retrieval-augmented generation (RAG). Nevertheless, the evaluation of RAG systems remains a barrier to continued progress, a challenge we tackle in this work by proposing an automatic evaluation framework that is validated against human annotations. We believe that the nugget evaluation methodology provides a solid foundation for evaluating RAG systems. This approach, originally developed for the TREC Question Answering (QA) Track in 2003, evaluates systems based on atomic facts that should be present in good answers. Our efforts focus on "refactoring" this methodology, where we describe the AutoNuggetizer framework that specifically applies LLMs to both automatically create nuggets and automatically assign nuggets to system answers. In the context of the TREC 2024 RAG Track, we calibrate a fully automatic approach against strategies where nuggets are created manually or semi-manually by human assessors and then assigned manually to system answers. Based on results from a community-wide evaluation, we observe strong agreement at the run level between scores derived from fully automatic nugget evaluation and human-based variants. The agreement is stronger when individual framework components such as nugget assignment are automated independently. This suggests that our evaluation framework provides tradeoffs between effort and quality that can be used to guide the development of future RAG systems. However, further research is necessary to refine our approach, particularly in establishing robust per-topic agreement to diagnose system failures effectively.
Support Evaluation for the TREC 2024 RAG Track: Comparing Human versus LLM Judges
Apr 21, 2025Retrieval-augmented generation (RAG) enables large language models (LLMs) to generate answers with citations from source documents containing "ground truth", thereby reducing system hallucinations. A crucial factor in RAG evaluation is "support", whether the information in the cited documents supports the answer. To this end, we conducted a large-scale comparative study of 45 participant submissions on 36 topics to the TREC 2024 RAG Track, comparing an automatic LLM judge (GPT-4o) against human judges for support assessment. We considered two conditions: (1) fully manual assessments from scratch and (2) manual assessments with post-editing of LLM predictions. Our results indicate that for 56% of the manual from-scratch assessments, human and GPT-4o predictions match perfectly (on a three-level scale), increasing to 72% in the manual with post-editing condition. Furthermore, by carefully analyzing the disagreements in an unbiased study, we found that an independent human judge correlates better with GPT-4o than a human judge, suggesting that LLM judges can be a reliable alternative for support assessment. To conclude, we provide a qualitative analysis of human and GPT-4o errors to help guide future iterations of support assessment.
FreshStack: Building Realistic Benchmarks for Evaluating Retrieval on Technical Documents
Apr 17, 2025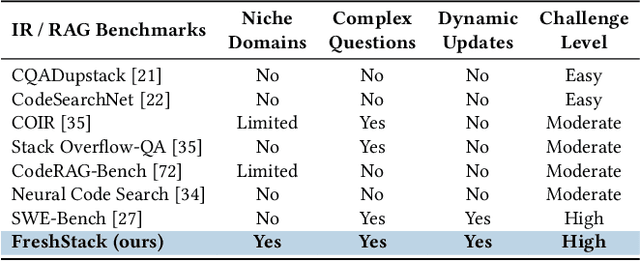
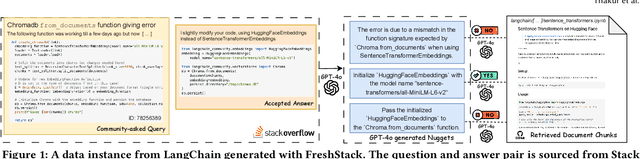
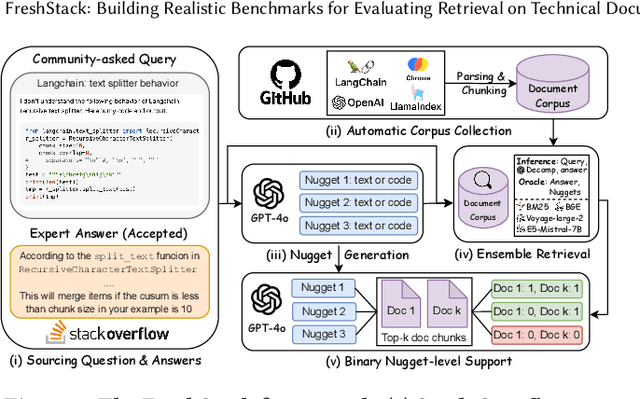

We introduce FreshStack, a reusable framework for automatically building information retrieval (IR) evaluation benchmarks from community-asked questions and answers. FreshStack conducts the following steps: (1) automatic corpus collection from code and technical documentation, (2) nugget generation from community-asked questions and answers, and (3) nugget-level support, retrieving documents using a fusion of retrieval techniques and hybrid architectures. We use FreshStack to build five datasets on fast-growing, recent, and niche topics to ensure the tasks are sufficiently challenging. On FreshStack, existing retrieval models, when applied out-of-the-box, significantly underperform oracle approaches on all five topics, denoting plenty of headroom to improve IR quality. In addition, we identify cases where rerankers do not clearly improve first-stage retrieval accuracy (two out of five topics). We hope that FreshStack will facilitate future work toward constructing realistic, scalable, and uncontaminated IR and RAG evaluation benchmarks. FreshStack datasets are available at: https://fresh-stack.github.io.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Initial Nugget Evaluation Results for the TREC 2024 RAG Track with the AutoNuggetizer Framework
Nov 14, 2024

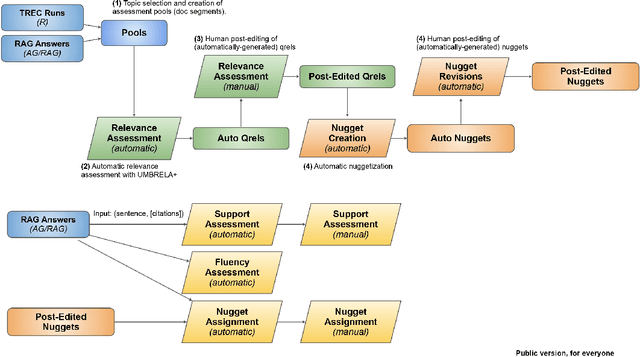

This report provides an initial look at partial results from the TREC 2024 Retrieval-Augmented Generation (RAG) Track. We have identified RAG evaluation as a barrier to continued progress in information access (and more broadly, natural language processing and artificial intelligence), and it is our hope that we can contribute to tackling the many challenges in this space. The central hypothesis we explore in this work is that the nugget evaluation methodology, originally developed for the TREC Question Answering Track in 2003, provides a solid foundation for evaluating RAG systems. As such, our efforts have focused on "refactoring" this methodology, specifically applying large language models to both automatically create nuggets and to automatically assign nuggets to system answers. We call this the AutoNuggetizer framework. Within the TREC setup, we are able to calibrate our fully automatic process against a manual process whereby nuggets are created by human assessors semi-manually and then assigned manually to system answers. Based on initial results across 21 topics from 45 runs, we observe a strong correlation between scores derived from a fully automatic nugget evaluation and a (mostly) manual nugget evaluation by human assessors. This suggests that our fully automatic evaluation process can be used to guide future iterations of RAG systems.
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look
Nov 13, 2024The application of large language models to provide relevance assessments presents exciting opportunities to advance information retrieval, natural language processing, and beyond, but to date many unknowns remain. This paper reports on the results of a large-scale evaluation (the TREC 2024 RAG Track) where four different relevance assessment approaches were deployed in situ: the "standard" fully manual process that NIST has implemented for decades and three different alternatives that take advantage of LLMs to different extents using the open-source UMBRELA tool. This setup allows us to correlate system rankings induced by the different approaches to characterize tradeoffs between cost and quality. We find that in terms of nDCG@20, nDCG@100, and Recall@100, system rankings induced by automatically generated relevance assessments from UMBRELA correlate highly with those induced by fully manual assessments across a diverse set of 77 runs from 19 teams. Our results suggest that automatically generated UMBRELA judgments can replace fully manual judgments to accurately capture run-level effectiveness. Surprisingly, we find that LLM assistance does not appear to increase correlation with fully manual assessments, suggesting that costs associated with human-in-the-loop processes do not bring obvious tangible benefits. Overall, human assessors appear to be stricter than UMBRELA in applying relevance criteria. Our work validates the use of LLMs in academic TREC-style evaluations and provides the foundation for future studies.
MIRAGE-Bench: Automatic Multilingual Benchmark Arena for Retrieval-Augmented Generation Systems
Oct 17, 2024
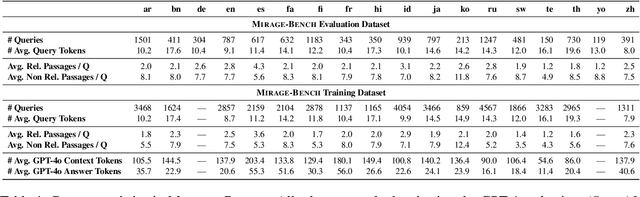
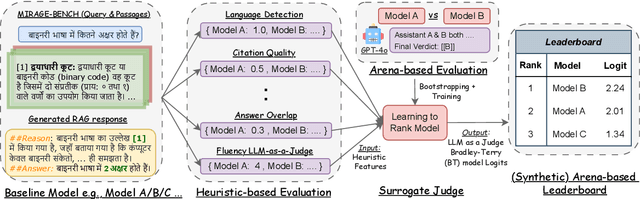
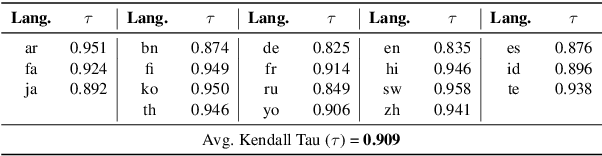
Traditional Retrieval-Augmented Generation (RAG) benchmarks rely on different heuristic-based metrics for evaluation, but these require human preferences as ground truth for reference. In contrast, arena-based benchmarks, where two models compete each other, require an expensive Large Language Model (LLM) as a judge for a reliable evaluation. We present an easy and efficient technique to get the best of both worlds. The idea is to train a learning to rank model as a "surrogate" judge using RAG-based evaluation heuristics as input, to produce a synthetic arena-based leaderboard. Using this idea, We develop MIRAGE-Bench, a standardized arena-based multilingual RAG benchmark for 18 diverse languages on Wikipedia. The benchmark is constructed using MIRACL, a retrieval dataset, and extended for multilingual generation evaluation. MIRAGE-Bench evaluates RAG extensively coupling both heuristic features and LLM as a judge evaluator. In our work, we benchmark 19 diverse multilingual-focused LLMs, and achieve a high correlation (Kendall Tau ($\tau$) = 0.909) using our surrogate judge learned using heuristic features with pairwise evaluations and between GPT-4o as a teacher on the MIRAGE-Bench leaderboard using the Bradley-Terry framework. We observe proprietary and large open-source LLMs currently dominate in multilingual RAG. MIRAGE-Bench is available at: https://github.com/vectara/mirage-bench.
Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIR
Jul 10, 2024



The zero-shot effectiveness of neural retrieval models is often evaluated on the BEIR benchmark -- a combination of different IR evaluation datasets. Interestingly, previous studies found that particularly on the BEIR subset Touch\'e 2020, an argument retrieval task, neural retrieval models are considerably less effective than BM25. Still, so far, no further investigation has been conducted on what makes argument retrieval so "special". To more deeply analyze the respective potential limits of neural retrieval models, we run a reproducibility study on the Touch\'e 2020 data. In our study, we focus on two experiments: (i) a black-box evaluation (i.e., no model retraining), incorporating a theoretical exploration using retrieval axioms, and (ii) a data denoising evaluation involving post-hoc relevance judgments. Our black-box evaluation reveals an inherent bias of neural models towards retrieving short passages from the Touch\'e 2020 data, and we also find that quite a few of the neural models' results are unjudged in the Touch\'e 2020 data. As many of the short Touch\'e passages are not argumentative and thus non-relevant per se, and as the missing judgments complicate fair comparison, we denoise the Touch\'e 2020 data by excluding very short passages (less than 20 words) and by augmenting the unjudged data with post-hoc judgments following the Touch\'e guidelines. On the denoised data, the effectiveness of the neural models improves by up to 0.52 in nDCG@10, but BM25 is still more effective. Our code and the augmented Touch\'e 2020 dataset are available at \url{https://github.com/castorini/touche-error-analysis}.