 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConventional Contrastive Learning Often Falls Short: Improving Dense Retrieval with Cross-Encoder Listwise Distillation and Synthetic Data
May 25, 2025We investigate improving the retrieval effectiveness of embedding models through the lens of corpus-specific fine-tuning. Prior work has shown that fine-tuning with queries generated using a dataset's retrieval corpus can boost retrieval effectiveness for the dataset. However, we find that surprisingly, fine-tuning using the conventional InfoNCE contrastive loss often reduces effectiveness in state-of-the-art models. To overcome this, we revisit cross-encoder listwise distillation and demonstrate that, unlike using contrastive learning alone, listwise distillation can help more consistently improve retrieval effectiveness across multiple datasets. Additionally, we show that synthesizing more training data using diverse query types (such as claims, keywords, and questions) yields greater effectiveness than using any single query type alone, regardless of the query type used in evaluation. Our findings further indicate that synthetic queries offer comparable utility to human-written queries for training. We use our approach to train an embedding model that achieves state-of-the-art effectiveness among BERT embedding models. We release our model and both query generation and training code to facilitate further research.
Benchmarking LLM Faithfulness in RAG with Evolving Leaderboards
May 07, 2025


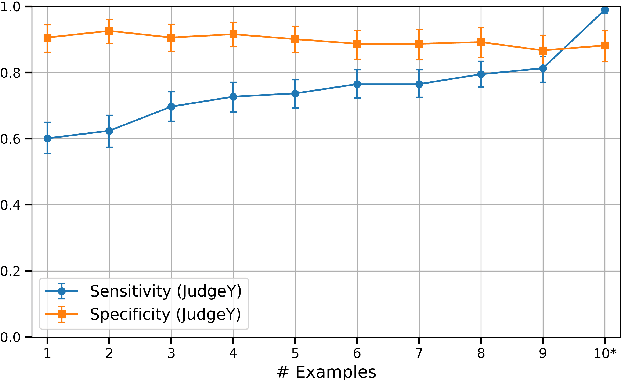
Hallucinations remain a persistent challenge for LLMs. RAG aims to reduce hallucinations by grounding responses in contexts. However, even when provided context, LLMs still frequently introduce unsupported information or contradictions. This paper presents our efforts to measure LLM hallucinations with a focus on summarization tasks, assessing how often various LLMs introduce hallucinations when summarizing documents. We discuss Vectara's existing LLM hallucination leaderboard, based on the Hughes Hallucination Evaluation Model (HHEM). While HHEM and Vectara's Hallucination Leaderboard have garnered great research interest, we examine challenges faced by HHEM and current hallucination detection methods by analyzing the effectiveness of these methods on existing hallucination datasets. To address these limitations, we propose FaithJudge, an LLM-as-a-judge approach guided by few-shot human hallucination annotations, which substantially improves automated LLM hallucination evaluation over current methods. We introduce an enhanced hallucination leaderboard centered on FaithJudge, alongside our current hallucination leaderboard, enabling more reliable benchmarking of LLMs for hallucinations in RAG.
Teaching Dense Retrieval Models to Specialize with Listwise Distillation and LLM Data Augmentation
Feb 27, 2025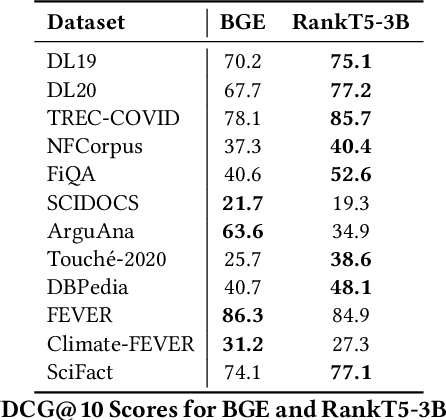
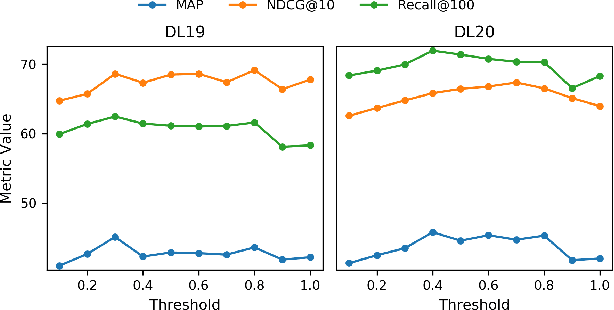

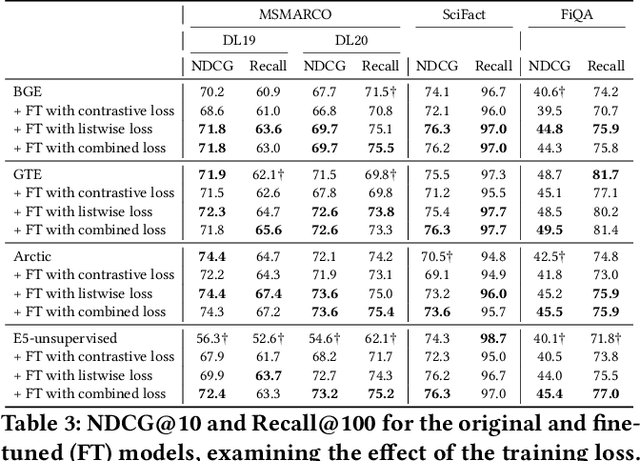
While the current state-of-the-art dense retrieval models exhibit strong out-of-domain generalization, they might fail to capture nuanced domain-specific knowledge. In principle, fine-tuning these models for specialized retrieval tasks should yield higher effectiveness than relying on a one-size-fits-all model, but in practice, results can disappoint. We show that standard fine-tuning methods using an InfoNCE loss can unexpectedly degrade effectiveness rather than improve it, even for domain-specific scenarios. This holds true even when applying widely adopted techniques such as hard-negative mining and negative de-noising. To address this, we explore a training strategy that uses listwise distillation from a teacher cross-encoder, leveraging rich relevance signals to fine-tune the retriever. We further explore synthetic query generation using large language models. Through listwise distillation and training with a diverse set of queries ranging from natural user searches and factual claims to keyword-based queries, we achieve consistent effectiveness gains across multiple datasets. Our results also reveal that synthetic queries can rival human-written queries in training utility. However, we also identify limitations, particularly in the effectiveness of cross-encoder teachers as a bottleneck. We release our code and scripts to encourage further research.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024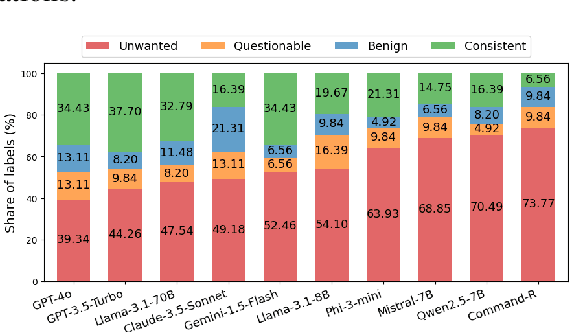
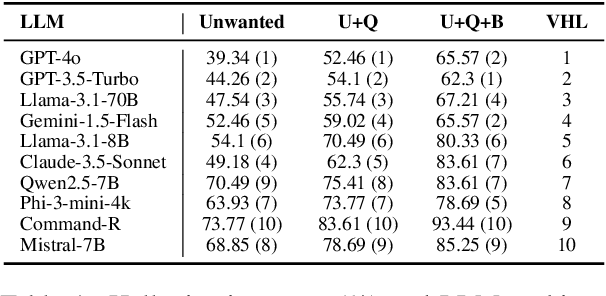
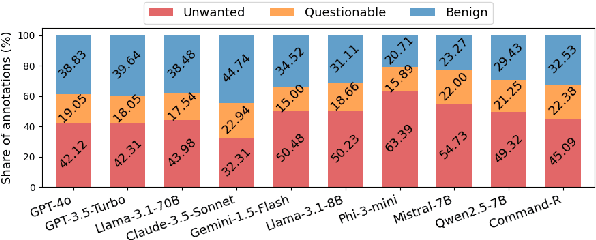
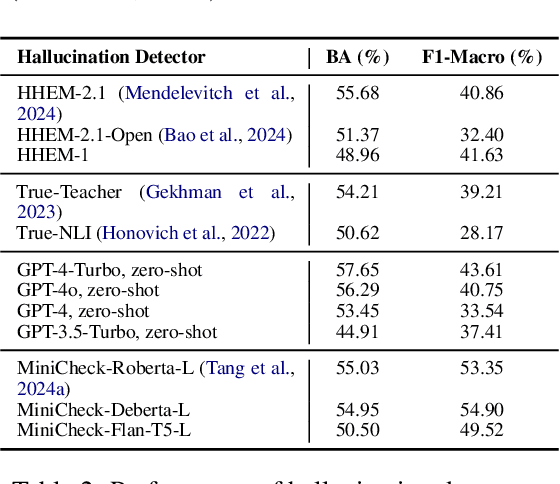
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
MIRAGE-Bench: Automatic Multilingual Benchmark Arena for Retrieval-Augmented Generation Systems
Oct 17, 2024
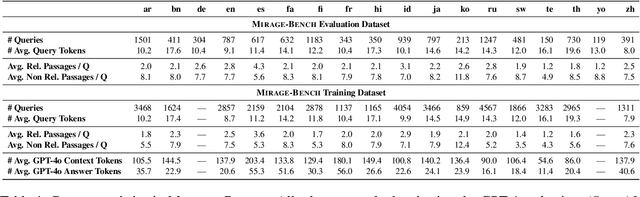
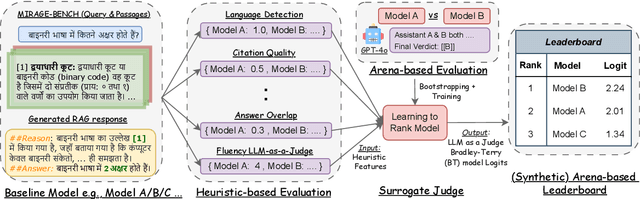
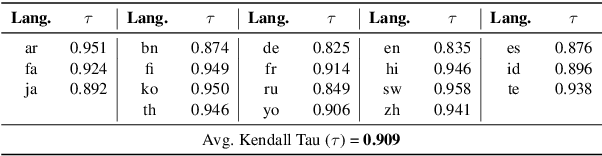
Traditional Retrieval-Augmented Generation (RAG) benchmarks rely on different heuristic-based metrics for evaluation, but these require human preferences as ground truth for reference. In contrast, arena-based benchmarks, where two models compete each other, require an expensive Large Language Model (LLM) as a judge for a reliable evaluation. We present an easy and efficient technique to get the best of both worlds. The idea is to train a learning to rank model as a "surrogate" judge using RAG-based evaluation heuristics as input, to produce a synthetic arena-based leaderboard. Using this idea, We develop MIRAGE-Bench, a standardized arena-based multilingual RAG benchmark for 18 diverse languages on Wikipedia. The benchmark is constructed using MIRACL, a retrieval dataset, and extended for multilingual generation evaluation. MIRAGE-Bench evaluates RAG extensively coupling both heuristic features and LLM as a judge evaluator. In our work, we benchmark 19 diverse multilingual-focused LLMs, and achieve a high correlation (Kendall Tau ($\tau$) = 0.909) using our surrogate judge learned using heuristic features with pairwise evaluations and between GPT-4o as a teacher on the MIRAGE-Bench leaderboard using the Bradley-Terry framework. We observe proprietary and large open-source LLMs currently dominate in multilingual RAG. MIRAGE-Bench is available at: https://github.com/vectara/mirage-bench.